
前言
在代表性工作之余,也有必要阅读一些其他的内容,这当然也需要总结,所以新开设一个章节,记录在这里。
PointLLM
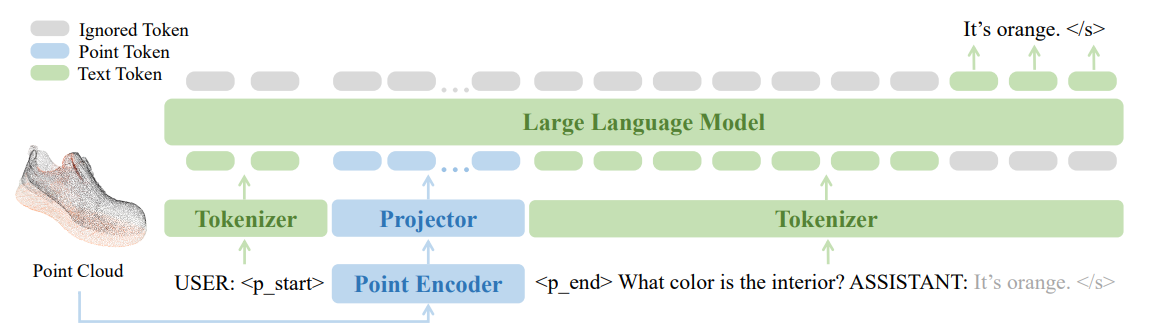
PointLLM 可以是说十分标志的工作了,属于是中规中矩,但是效果确实很不错。就像是一般的 VLM 一样,但是只不过是将图像的模态输入换成了点云,然后使用 point encoder,总体来说改变并不算多。可以说这篇工作的诞生是符合直觉的,点云模态也可以作为一种语言进行建模。
EmbodiedGPT
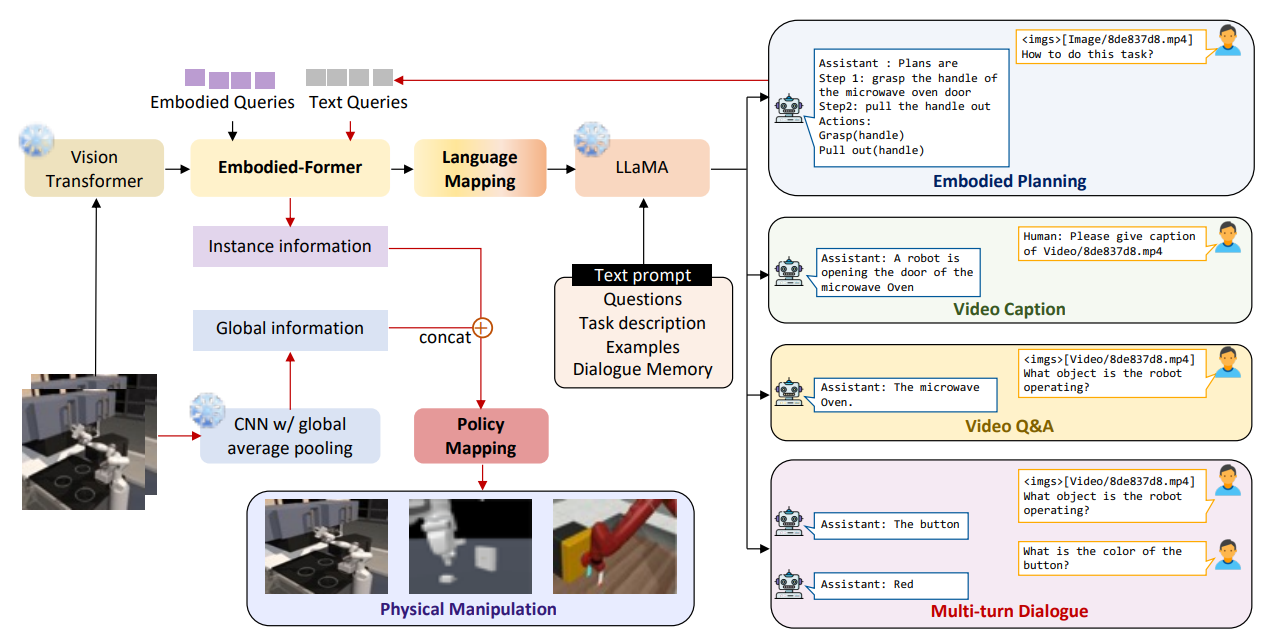
EmbodiedGPT 也是一篇比较符合直觉的工作,但是不是那么的极简。本身是按照 BLIP2 的范式来的,用了一个 Embodied-Former(其实也就是 Q-former)来连接 ViT 和 LLaMA3,来做一个桥梁,之后输出一个 instance information,一个 CNN 处理图像输出一个 global information,两个 concat 一下作为 low-level policy 的输入。
本身值得说的是,一方面这种设计,为什么不单独通过 embodied-former 直接输出的 instance information 呢?毕竟也是通过了 ViT 的信息编码的,之所以还需要一个 CNN,大概率是这样做了之后发现表征能力不强,所以需要更加显式的提供一些信息。
RT-Trajectory
RT-Trajectory 是一个输出 low-level policy 的模型,使用了 RT-1 的框架作为动作的输出,在此之前会输入之前和当前的帧以及一个工作轨迹,这里面动作轨迹通过 R 和 G 两个通道表征了时间顺序以及高度信息,和图像一起输入。因为从文字 prompt 改为了图像(轨迹),所以本质上具有更高的细粒度,性能更好也很正常。
Im2Flow2Act
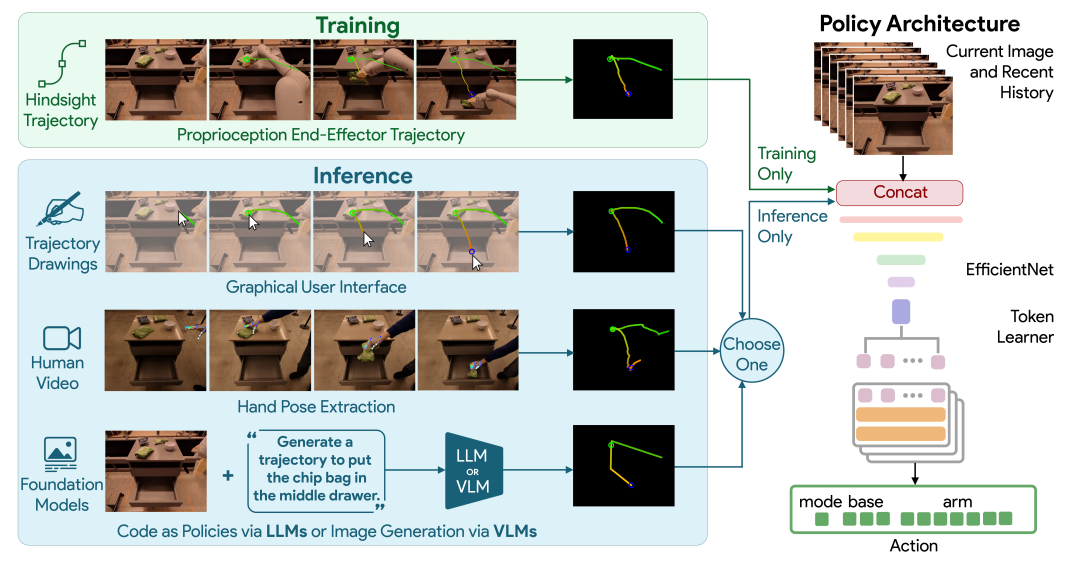
Im2Flow2Act 算是一篇比较有意思的工作,本身应该是 ATM 的后续工作,不过因为糟糕的阅读顺序,我其实是先阅读的这一篇。
因为确实需要的前置知识还是很多的,所以说先暂且形而上学的理解一下这个问题,后续估计需要详细的看一看相关的论文。Im2Flow2Act 的核心思想在于,首先根据任务生成对象流,对象流就具有很高的细粒度了,之后对象流通过模仿学习来获得动作规划。
这篇工作使用了 Diffusion 里面的动作生成(视频生成)作为流生成的方法。首先先框出来一个物体,在物体上面可以采样若干的关键点,这些点就组成了一个 $H\times W$ 的图片,但是这个图片不是正常的图片,和RT-Trajectory 里面的轨迹图片一样,是通过像素表征了别的信息,这里面就是图像系下的坐标和可见度。那么根据条件输入,就可以生成视频了,而这个视频本质上表征的是这个物体在不同时刻的空间信息。

流生成了之后,基本上是直接使用模仿学习进行的运动规划,用了 Transformer 去编码当前帧的状态,再用 Transformer 去和任务流做融合,来生成剩余的流,最后交给 Diffusion Policy 去生成动作。
粗浅的凑一下的话,创新性在于使用生成式的方法生成高细粒度的物体流,显然是优于 RT-Trajectory 的,同时第二阶段的时候使用当前的状态和任务流做融合,有一种 nav 中全局规划和局部规划的意味,但是并不完全。总的来说是一篇 based 轨迹的动作规划的很不错的工作,而且相较于 RT-Trajectory,更有细粒度,而且保证了公平性。
LLARVA
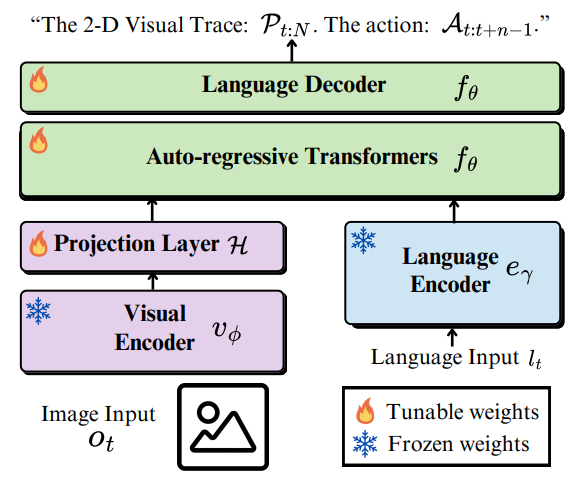
LLARVA 相较于之前的工作,可以说也是一个比较符合直觉的工作,使用指令调优(IT)的方法进行训练,也是处理了 OXE 这个数据集。从 Pipeline 也不难看出,LLARVA 是一个比较经典的架构,基本上也是 LLAVA 的框架,训练一个 projection layer 以及后面的 Transformer 做对齐以及模态的融合。

其创新点其实有点 World Model 的意思,通过让模型预测将来的视觉轨迹这种更具细粒度的内容,之后输出 Action,这明显是一个更加困难而且包含了更多未来信息的任务,所以效果会更好也是显而易见的。当然,本身 IT 的方法,自然也可以让模型更好地完成任务就是了。
ATM
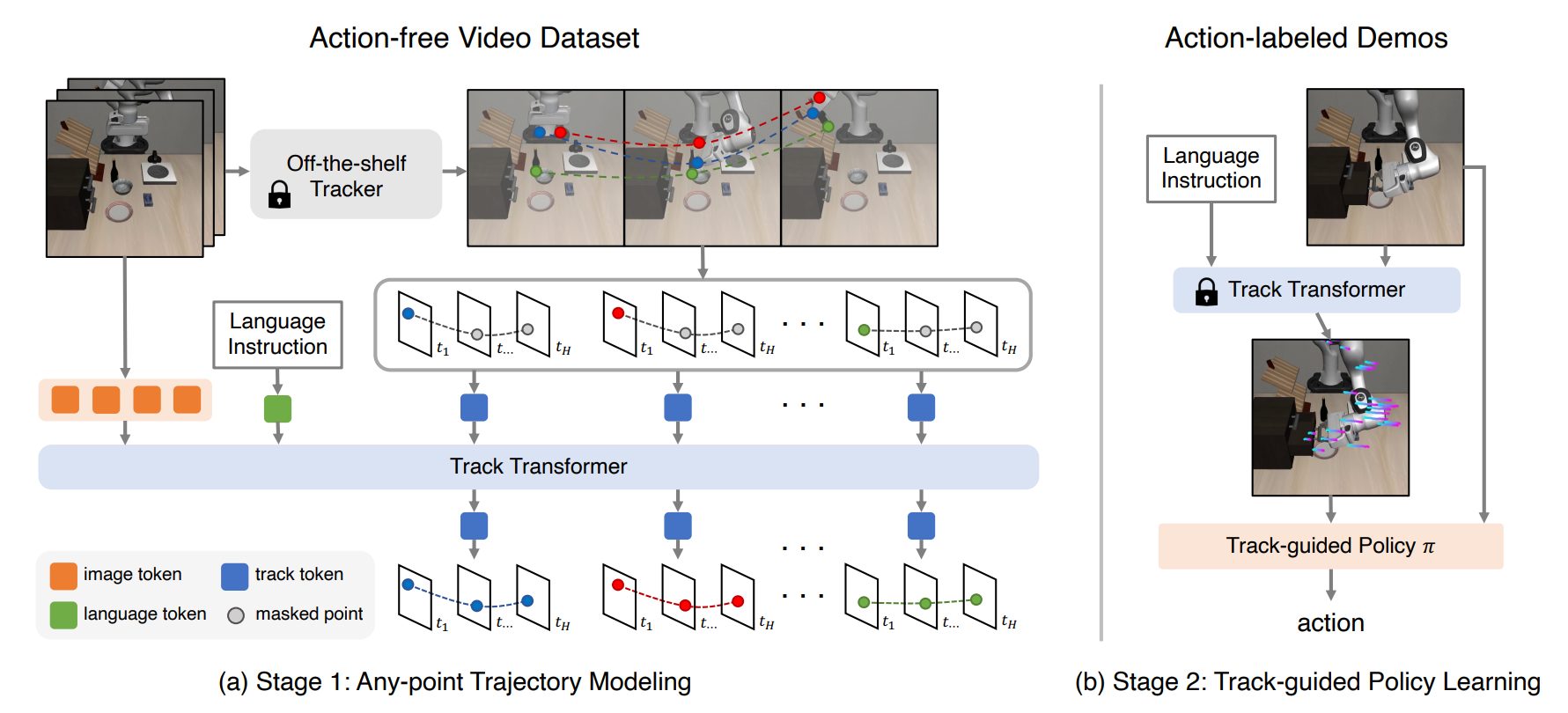
这篇论文可以说影响力还是很拉满的,对于后续的一些轨迹 based 的工作,比如 Im2Flow2Act,明显是有很大的影响的,本身也是拿了 RSS 的满分,不过因为理解了之前的这些论文,这一篇其实很好理解。

本身的话,ATM 没有采取像是 Im2Flow2Act 一样的物体轨迹的预测,这也比较好理解,全局的点一方面或许可以具有全局的动作视野,而另一方面,全局的点也会比较好获取一些。本身的方法就是使用点跟踪的技术对图像里的点进行跟踪来生成数据集,然后让一个 track transformer 来预测点的轨迹。接下来就是一个正常的 Trajectory Conditional Policy,本身的实现,论文里也说了,也是使用 cls token 去做全局表征(ViT like),然后用了 track prediction 去作为额外的 condition 进行 fusion。
从创新点来说,这篇算是开山之作之一了,引入了 Track 作为中间的表征以及条件,并且可以通过数据集的一些生成的技术进行标准的损失计算,因此在监督下训练提升的很好也是意料之中了。一方面增加了更具细粒度的输入,一方面这种细粒度也体现在任务的难度上(hard task),二者共同导致模型的简单易用。
Track2Act
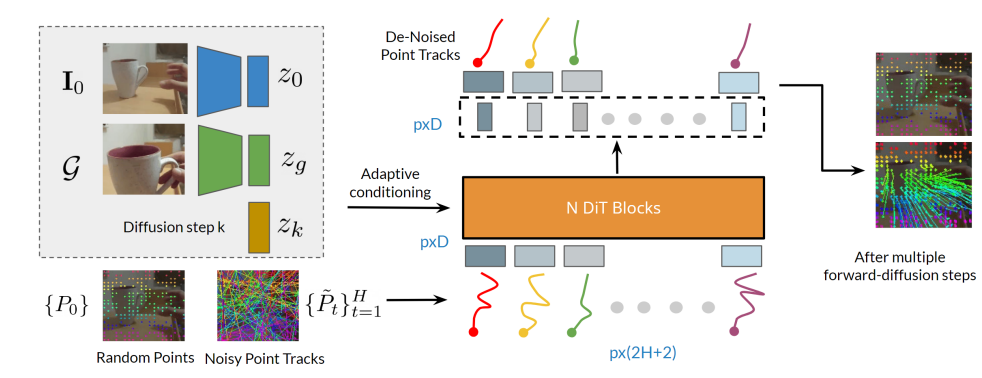
老实说,我并没有感觉到 Track2Act 和 ATM 之间是否真的具有较大的差异,二者的方法实际上是近似的,也就是先预测轨迹,之后将轨迹作为动作生成的条件。首先还是进行点的预测,在这里使用的是 DiT,随机 sample 一些点和轨迹,然后就可以进行生成了,将当前状态、目标以及迭代次数都作为 adaptive conditioning 输入。
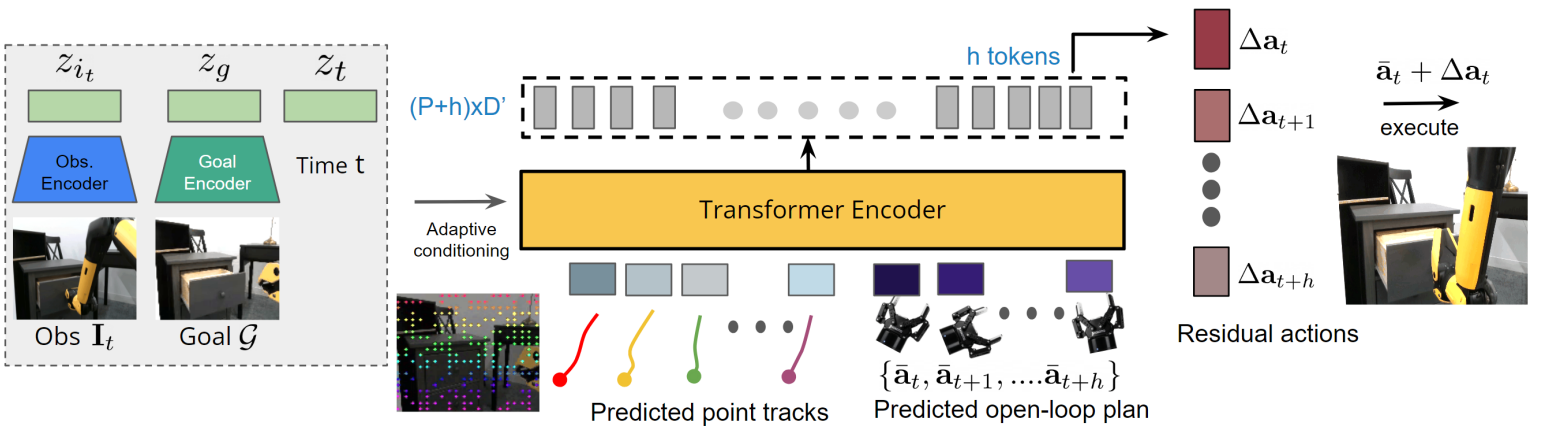
有了这些点之后,就不难给出一个刚性变化了,然而刚性变化注定不太靠谱,于是乎加入了一个残差策略,再用另一个模型的预测来修正之前的结果。按照文章的表述,残差控制可以增加准确度并未首创,不过确实是一个纠正偏差的好方法,前面的轨迹生成并求刚性变化,获得一个变化之后加上残差,这本质上其实和 ATM 直接通过一个模型进行 action 的求解是等价的,毕竟刚性变化同样可以用模型来进行表征。
Extreme Cross-Embodiment
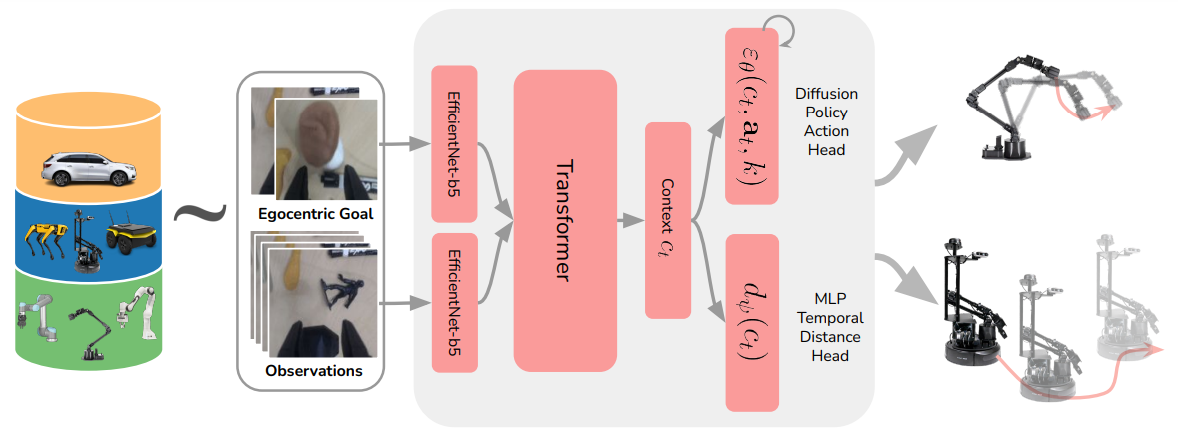
这篇文章的感觉有点野心很大故事丰满但是后继乏力的感觉。基本的故事是说要实现一种跨不同机器人模态的表征学习,但是实际上只是视觉导航以及抓取这两种任务,甚至并不涉及灵巧手,这并不能算十分的跨模态。本身的想法就是说,移动和抓取的本质上都是让相机坐标系发生了坐标系变换,实际上是等价的(虽然其实并不等价,因为机械臂受到物理尺寸限制),所以说可以统一,然后就开始直接训练一个模型,输入是 state 和 goal,之后直接融合,获得两个目标,一个是机械臂的位姿(DiT),一个是距离的预测(MLP),也算是将这两个任务统一了一点。
之前的任务,绝大多数都在处理单一的机器人下的任务,一般为机械臂,这篇的创新点也就止步于同时使用两种训练数据了。然而或许可以思考这样一个问题,假如说机器人的种类是可以穷尽的,或者说常见机器人的种类是可以穷尽的,一种 BEiTV3-like 的模型结构或许是可能的,直接在 Transformer 中引入 EMOE(Embodied MOE),然后同时使用这些全部的数据。
ECoT
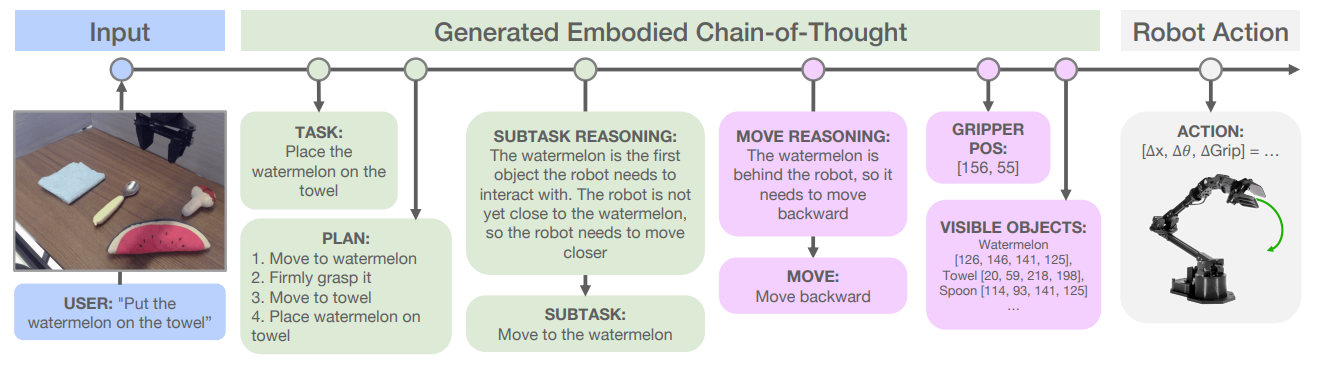
ECoT 这篇文章其实算是中规中矩,就是正常的 CoT,但是加入了 Embodied 的条件,能够 work 也是意料之中,或许其生成 CoT 数据的操作是可以借鉴的吧。
VoxPoser

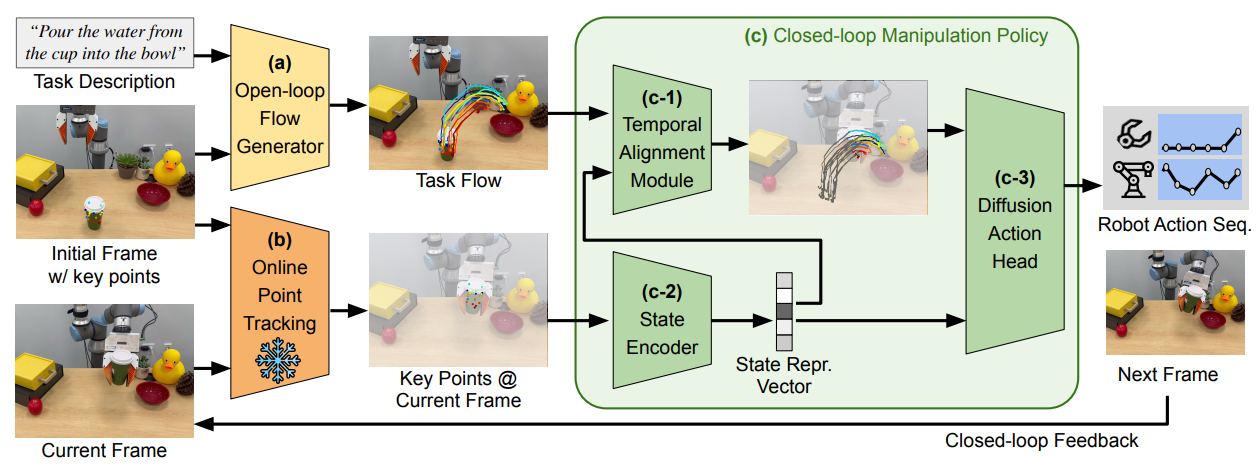
VoxPoser 这一篇其实我不太理解,其本身是通过 LLM 以及 VLM 获取图像以及任务的表征,并且想要输出两张价值图,其中 VLM 是传统的 VLM,类似于开集检测器,可以获得物体的位置,之后 LLM 来去处理这些位置,获得两张价值图,这两张价值图进一步引导模型进行轨迹规划。疑点在于,整个的框架的表征被极大的压缩了,本来丰富的视觉特征被压缩到了必要的物体上,之后被 LLM 处理为了价值图,个人感觉这套体系并不稳定,任何一环出了差错,整体就崩掉了。然而使用价值图作为引导是值得参考的,这为模型的轨迹规划提供了更明确的提示。
MOO
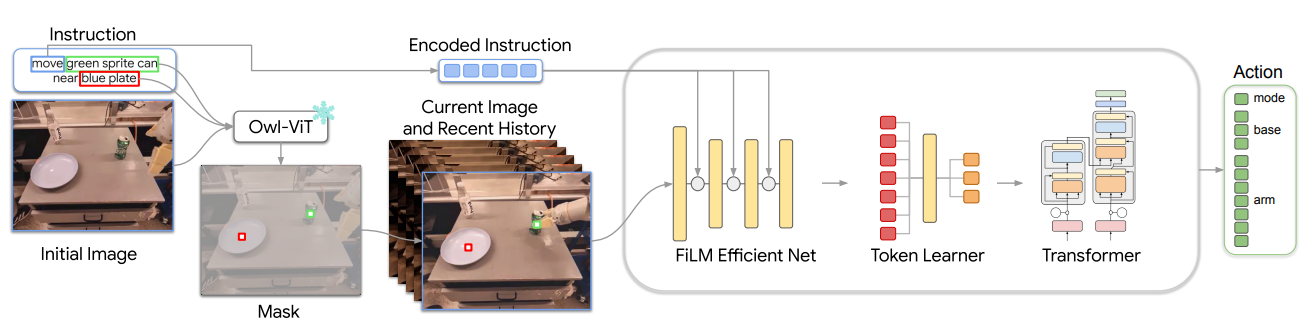
MOO 的 pipeline 也很简单,本身甚至可以说设置了一个 hard task,而这都是为了设置一个通用的接口。因为 MOO 本身使用了 RT-1 的架构,所以可以理解为,其本身对于复杂的语言表征能力有限,而且不同的任务中,这些语言的格式可能也不相同。不过这个接口,我个人感觉就是本身就是 RT-1 已经具备的。
大致的流程就像 pipeline 里面描述的一样,其可以将 Mask 作为一个通道融到图像里面,然后将动词提取出来。一个小的疑惑在于,比如说图中的任务,move 是一个向量,没有语序的话,模型如何理解这种顺序呢?然而这并非这篇论文核心探讨的问题,所以其实也无所谓。
ChatGPT for Robotics
本身可以理解为使用 ChatGPT 去做机器人的一个发散性的思考,同时提出了诸如 PromptCraft 之类的工具。
PIVOT
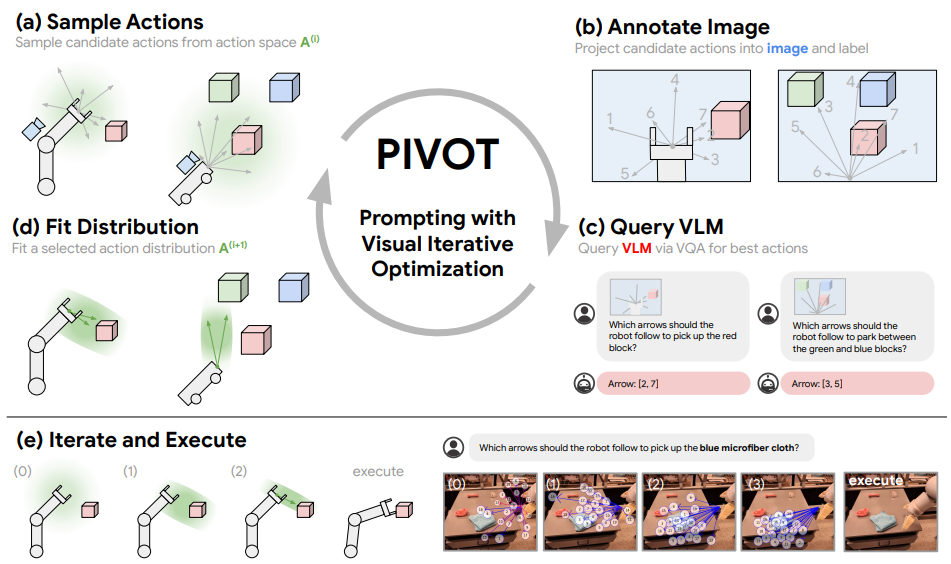
这篇文章的思想还是比较有趣的,也算是充分利用的 MLLM 的 VLM 能力。本身的思路其实在于,让大模型在具身智能的任务中进行生成式不太靠谱,但是去做选择题还是可以的。于是可以先随机 sample 一些动作或者轨迹,之后将这些内容 annotate 到图片上(与 CoPa 同理解,VLM 的 V 更具有空间的表征能力),让模型选择,然后一次次的选择即可。
Code As Policies

这篇文章的思路也很简答,就是可以使用代码来控制机器人,这等于可以让 LLM 与环境进行持续且合理的交互。大模型可以通过调用 API 来获取环境信息,比如说调用视觉 API 来获取物体位置,同时也支持了使用一些比如 for 之类的操作,毕竟代码肯定比一次次的生成式更加有条理。
MOKA
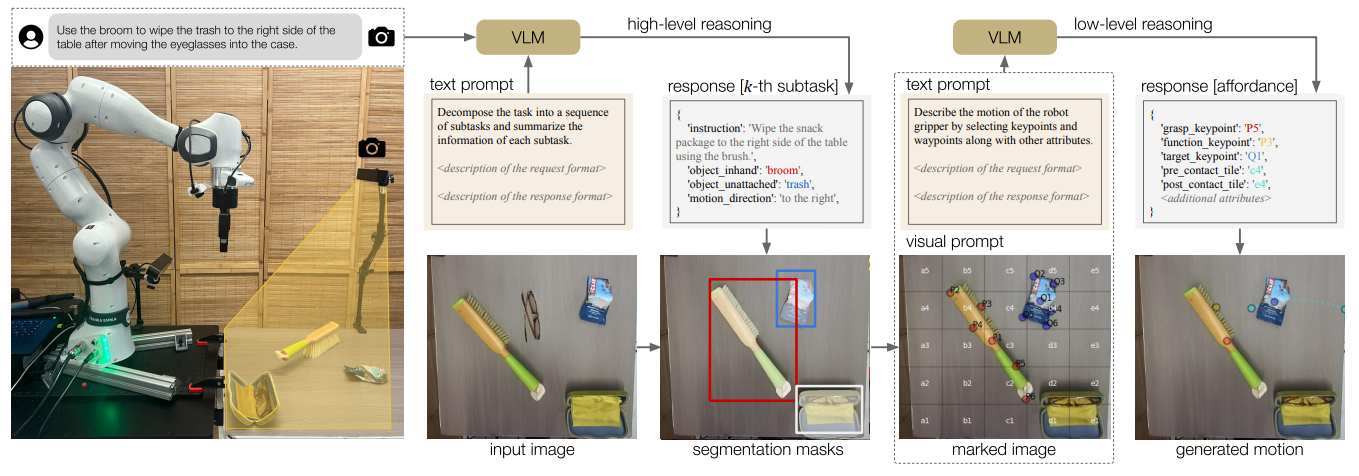
MOKA 的思路其实本质上和 CoPa 以及 PIVOT 是十分类似的,都是使用 Prompt-based 的 VLM,通过将不同的选择 annotate 到图像上,并且让模型进行选择,从而进行路径的规划。MOKA 等于说是希望通过若干的点标注,让模型学会如何去完成动作。所以流程上也是首先先找到需要操作的物体,然后再采样抓握点以及路径点之类的,最后结束。甚至说虽然 MOKA 里面没有明说,但是实际上其对于抓握点进行 filter,并且通过 filter 获得抓握姿态,这个流程实际上和 CoPa 可以说是一模一样,只是说 MOKA 希望通过路径点来完成动作,而 CoPa 则希望通过向量来完成动作。