Embodied AI Paper List
Paper Reading 之后,重走 EAI。
前沿#
具身智能这一新兴领域发展迅速,汇聚了来自 LLM / VLM / GenAI 等一系列领域的训练技巧与模型架构,在数据匮乏与路线纷争的情况下可以说是百家争鸣,各种技术路线层出不穷,大量方法涌现。然而大多数的方法重复且无趣,或者神似 CV 时代的 A+B 之作。本文尝试大海捞针,从浩如烟海的论文中找到那些代表领域发展脉络的论文,并使用简单的语言表述论文之间的差异,便于读者了解领域发展,并索引且精读自己感兴趣的方向。
VLA 模型#
作为一切的开始以及具身智能中最核心的概念,VLA 显然是最重要的章节。按照更加泛化的定义,所谓 VLA 模型指的是接受 Vision 以及 Language 输入,并且输出包含 Action 的大模型。通常我们认为它们会经过一定程度上的预训练,无论是基于以前的 LLM 或者 VLM 的先验知识,还是现有一些初创公司所闭源训练的,以及未来可能会存在的开源的原生 VLA 模型。
VLM-VLA#
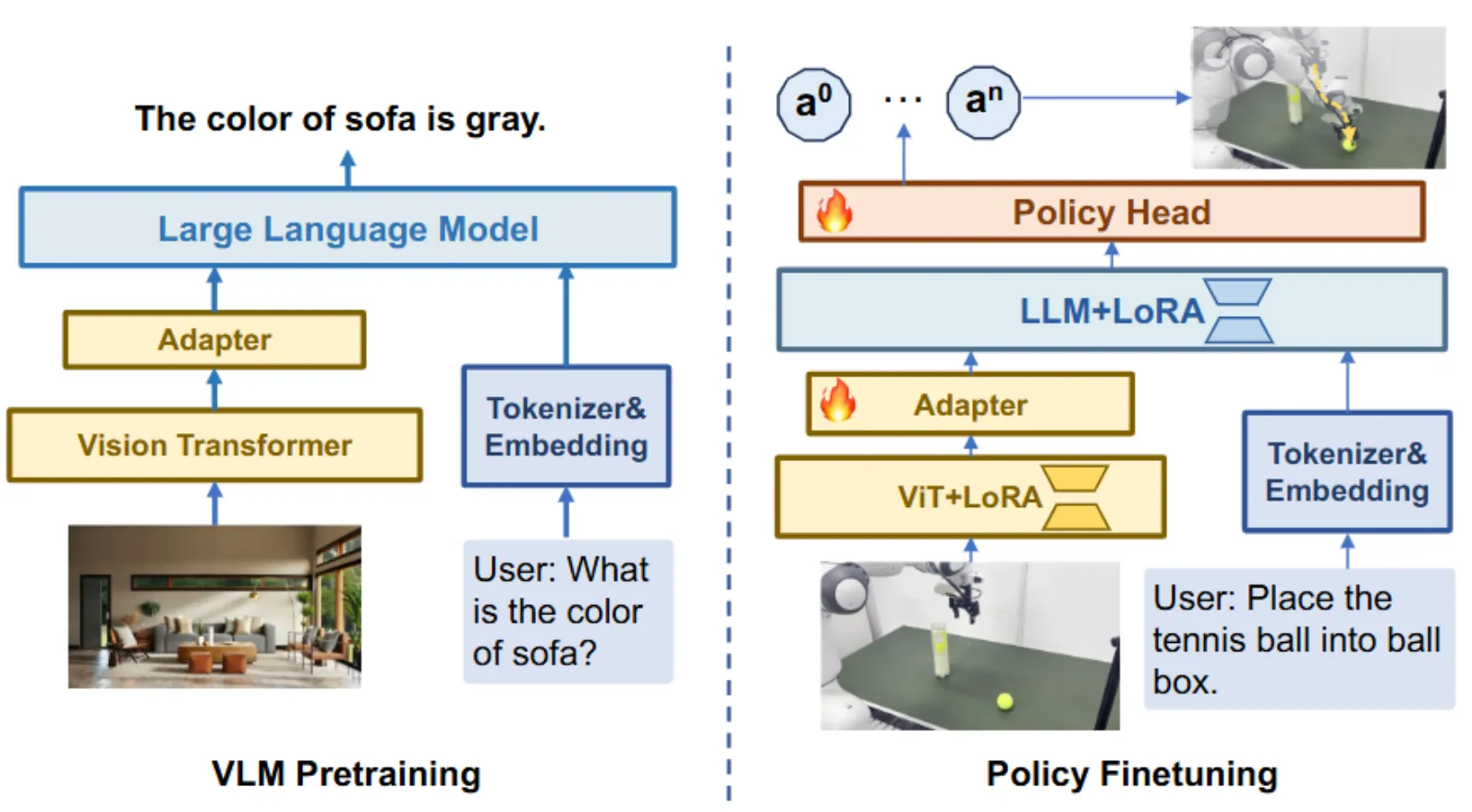
所谓 VLM-VLA,也就是我们常讲的狭义上的 VLA 模型,往往是基于一个经过预训练的 VLM 或者 LLM 作为 backbone 进行设计,并且在 Robot Data 上进行后训练。
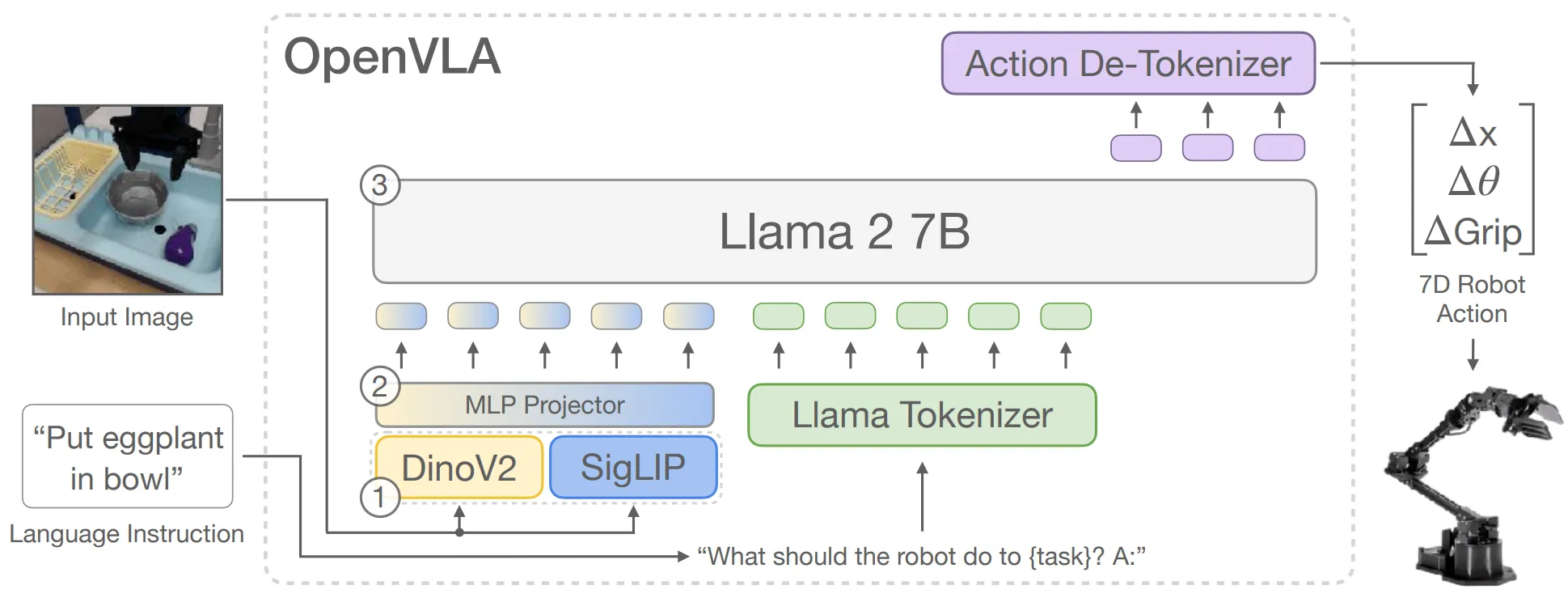
RT-2 以及 OpenVLA 是比较经典的早期 VLA 模型,都是使用预训练的 LLM 作为 Backbone,自己接入了 Visual Encoder,对于动作进行分箱处理,作为 Token 使用,并且直接以 Next Token Prediction 的方式进行训练。
VLA 范式#
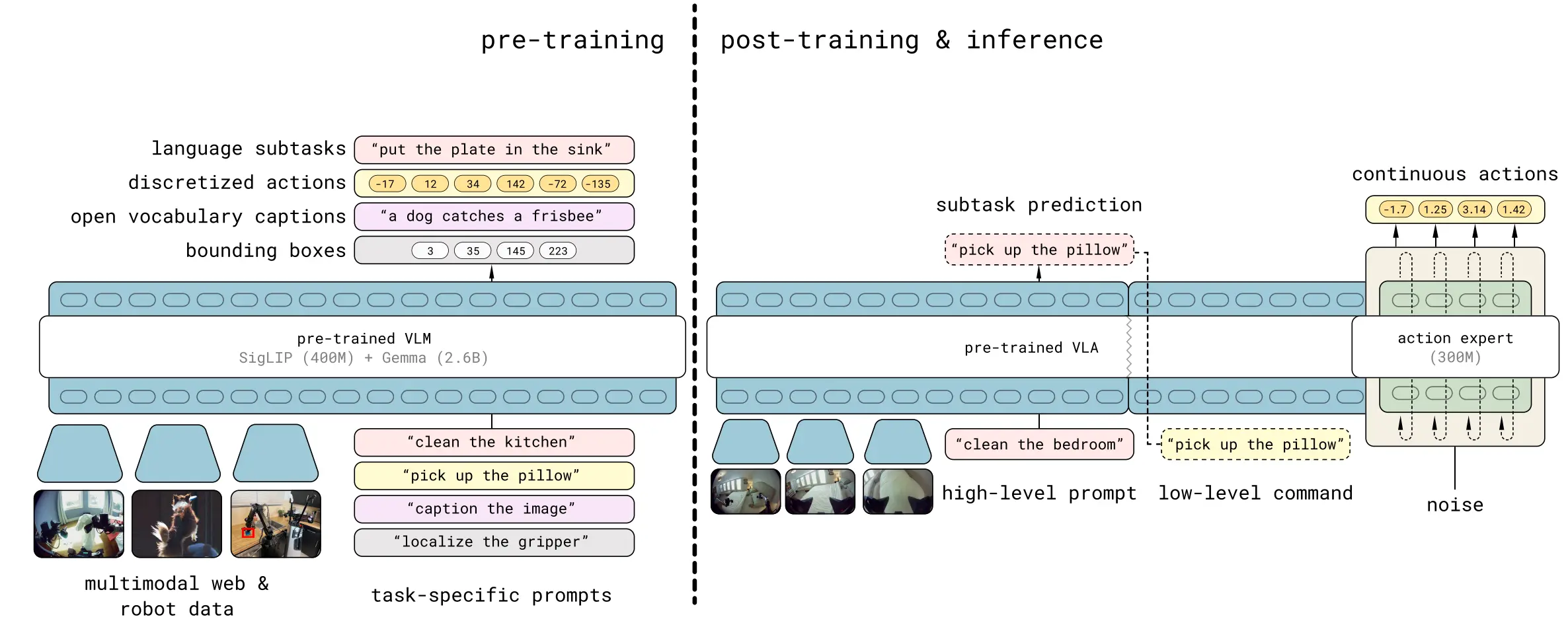
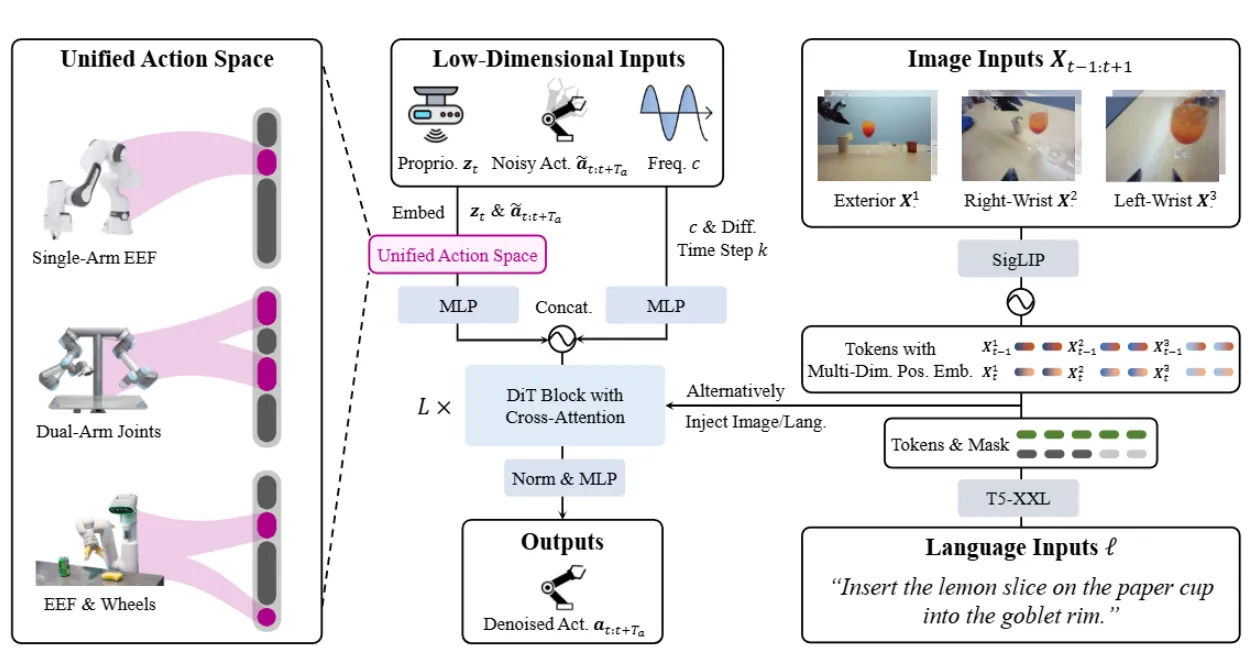
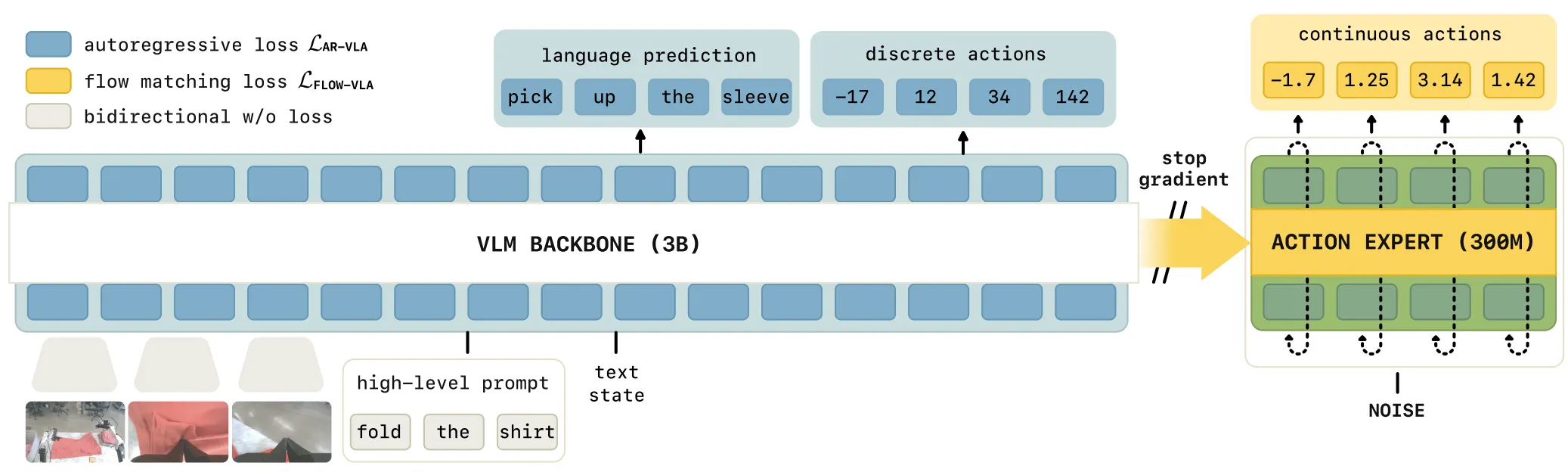
则是继 OpenVLA 这一范式之后的又一经典。 除了本身的预训练效果取得了不错的成果,论证了预训练的模型可以获得更好的性能(在 VLA 领域中,暂时不存在所谓的 Zero-shot 能力,但是预训练往往可以帮助模型在后训练时获得更好的性能),并且在后续作为了经典的 Baseline。同时, 一次性引入了多个在后续被广泛使用的 Setting,当然,这些内容一开始的出处在这里不作考证,包括使用 MoT 进行 LLM 以及 Actor 的交互(见 Bagel),使用 Flow Matching Loss 训练 Actor 以及使用 zero-padding 来进行跨本地的混合训练。
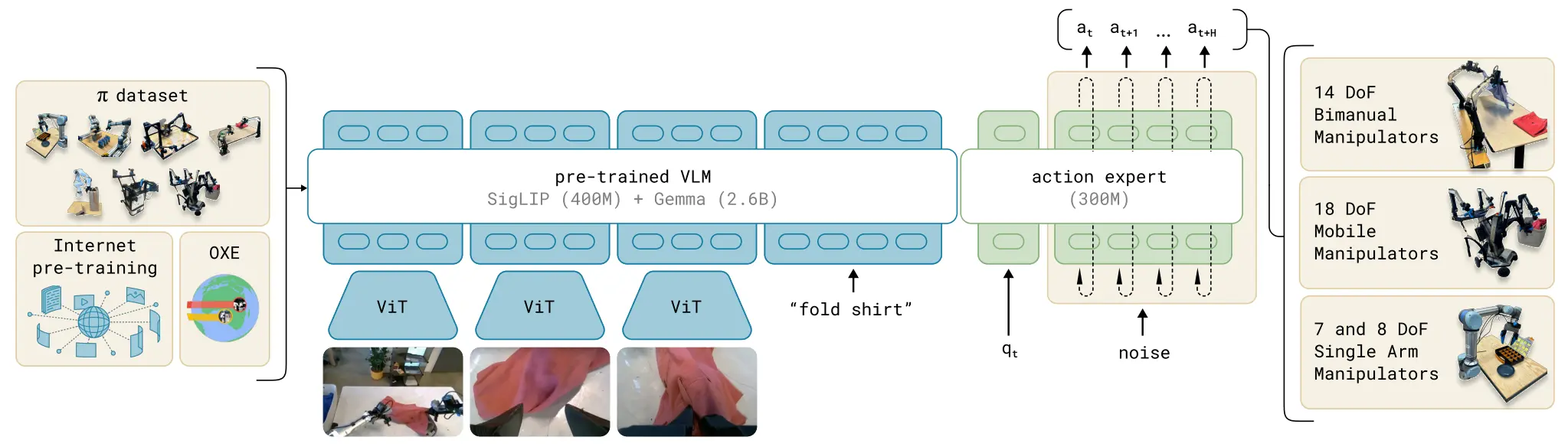
对于 有启发的工作包括 TinyVLA 以及 CogACT 等,他们都使用了 VLM 和 Actor 分离的设计,来避免后训练中对于 VLM 能力的灾难性破坏。在此之后 是 的一个 Follow-up,引入了更加系统的设计,使用 Web VLM Data 以及离散动作进行预训练,并且在后训练中也包括 sub goal prediction 的环节,并且具有了一些 Zero-shot 能力。其中比较值得考虑的是在预训练阶段引入离散的 Action Token,这一设计在后面的工作被 Follow-up。
与此同时另外一些值得参考的论文如下,他们均探讨了 VLM 与 Actor 的连接方式:
| 论文 | 主要贡献 |
|---|---|
| TinyVLA | 首次提出 VLM + Actor 设计,使用 VLM 的 embedding 作为 Condition |
| CogACT | 使用类似于 BERT 的 CLS Token 的 Cog Token 作为 Condition |
| RoboDual | 快慢系统设计,慢系统预测离散 Action 作为 Condition |
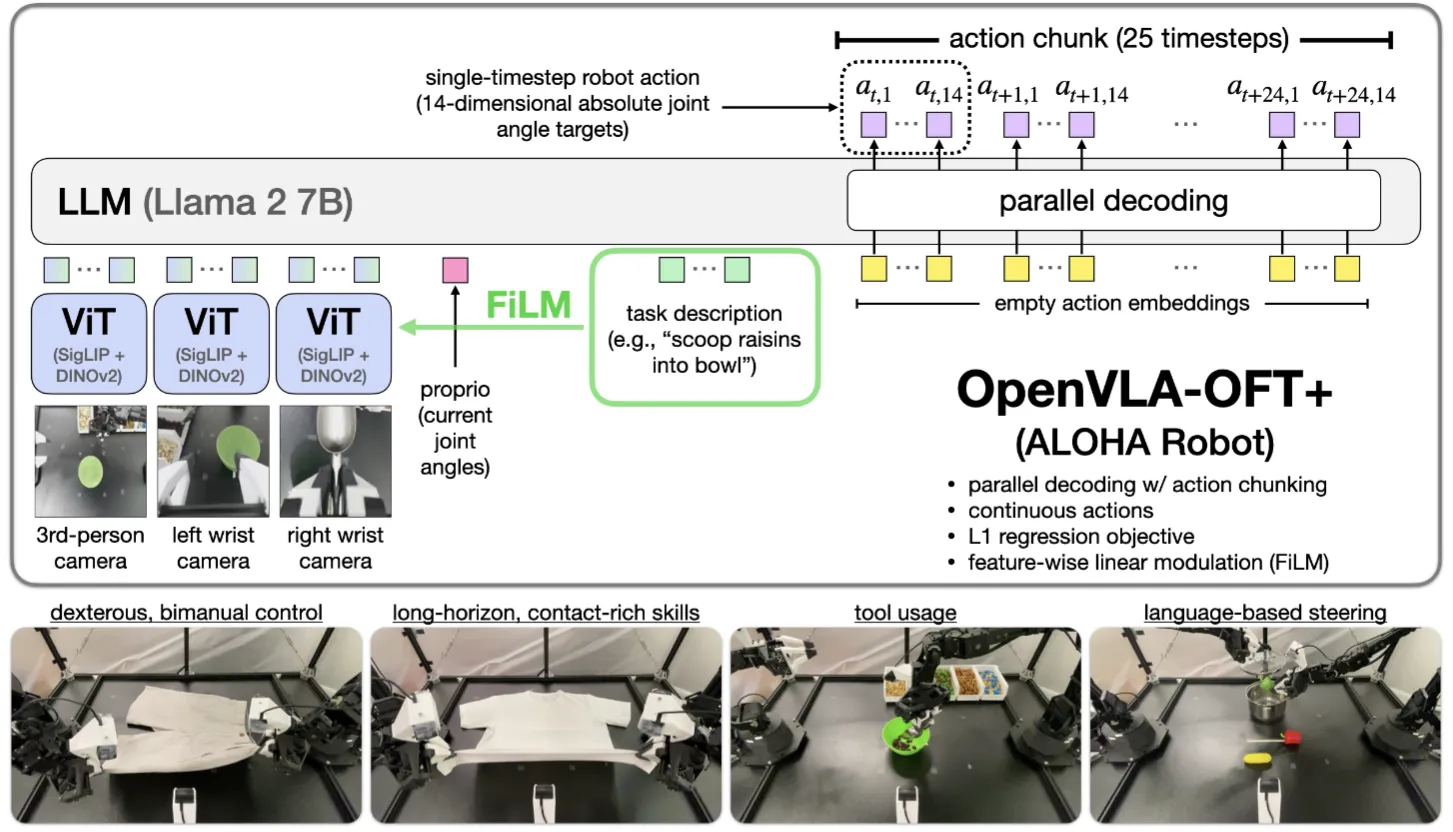
| OpenVLA-OFT | LLM + MLP 直接预测 Action,此方式至今简单有效 |
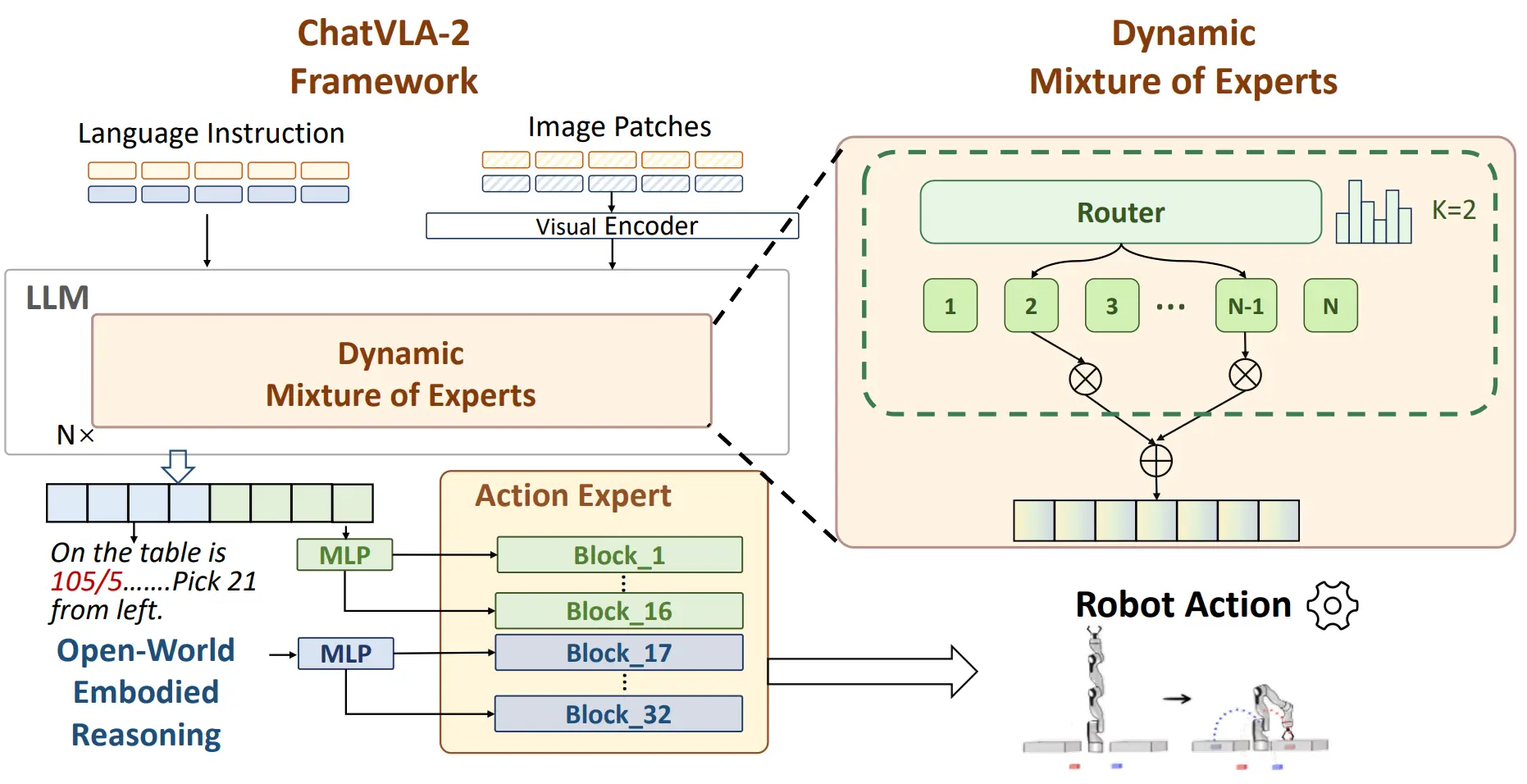
| ChatVLA-2 | 使用 Dynamic MOE |
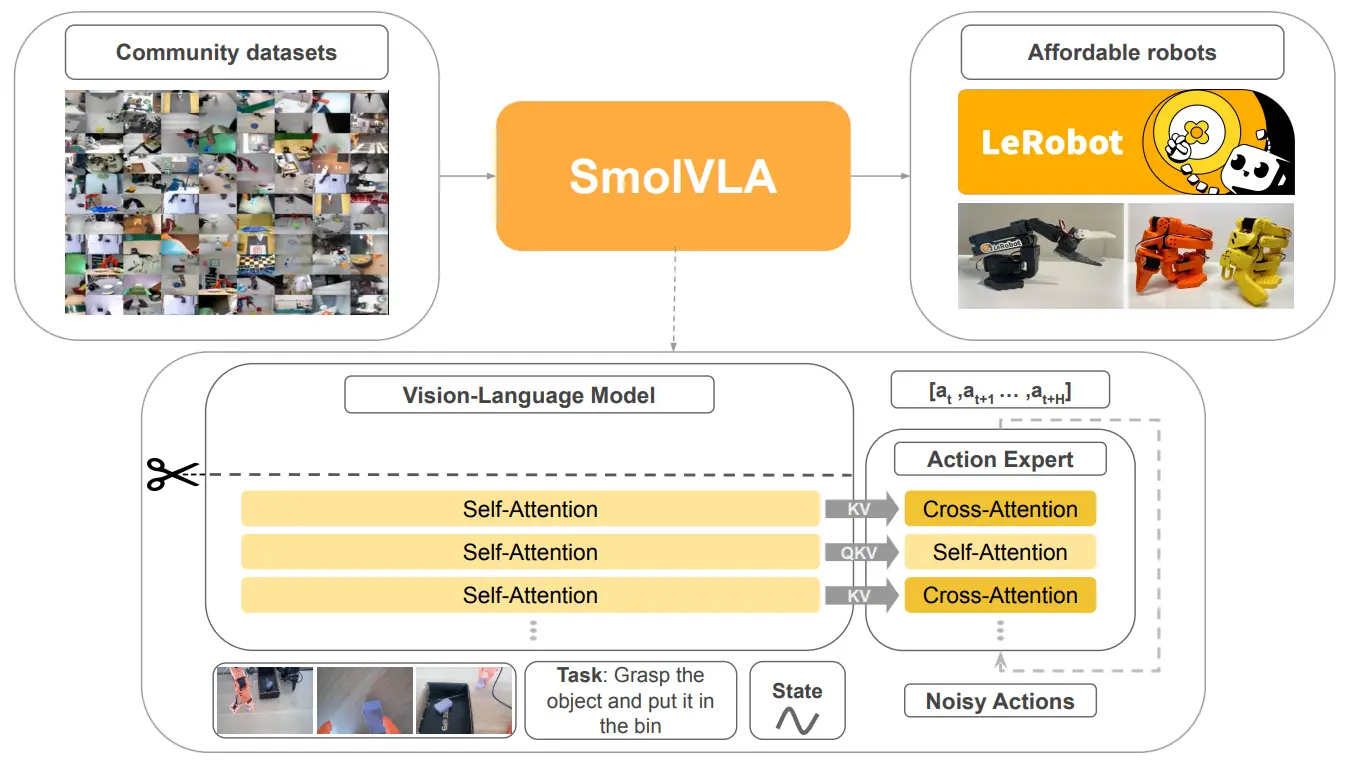
| SmolVLA | 在 Actor 使用了交错的 CA 与 SA,模型更加轻量化 |
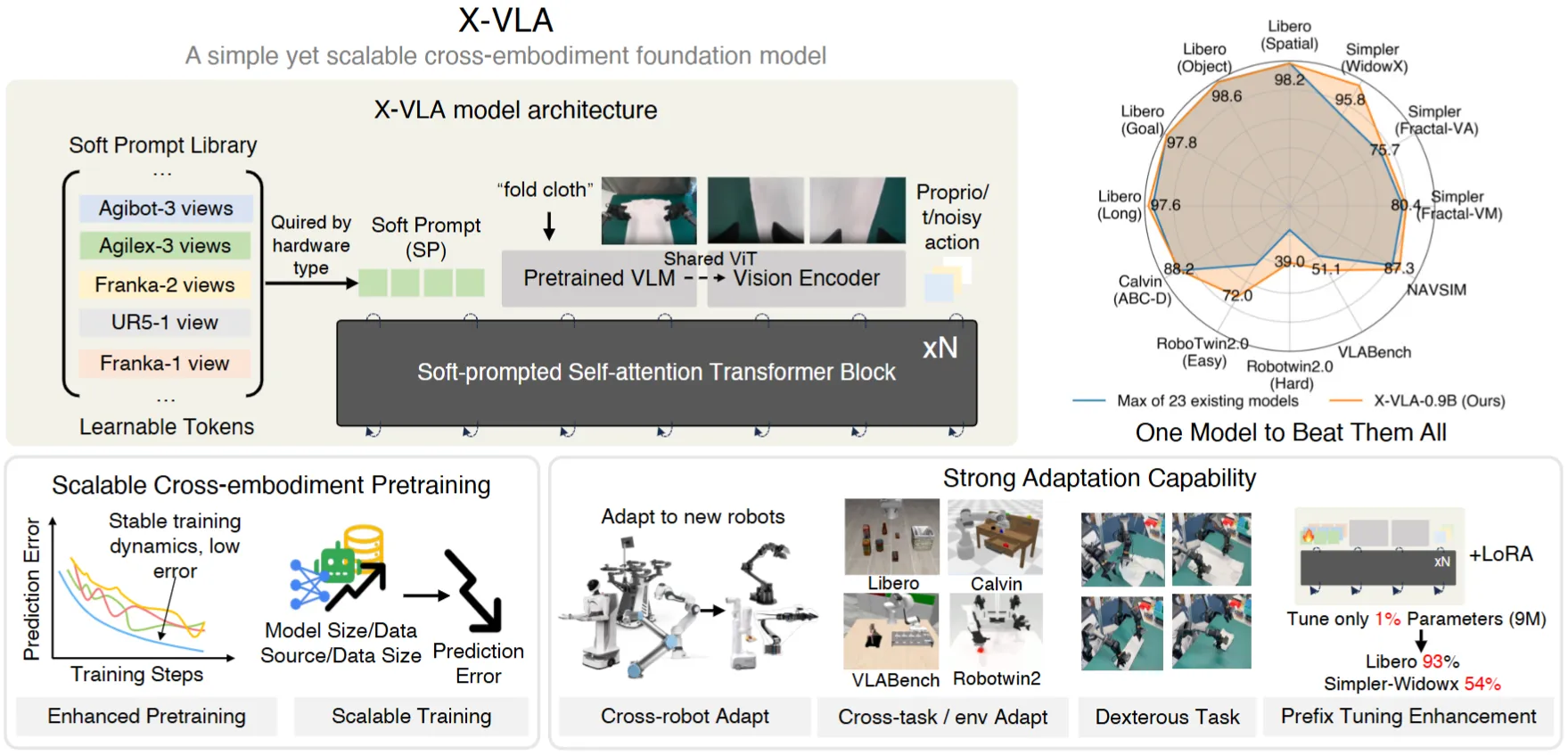
| X-VLA | 使用 soft prompt 混训的轻量 VLA,包括大量调模型技巧 |
| Qwen-RoboManip | VLA 训练的系统工程,详细的数据清洗以及训练,和各类 Ablation Study,Qwen + Actor 的 Pi-like VLA |
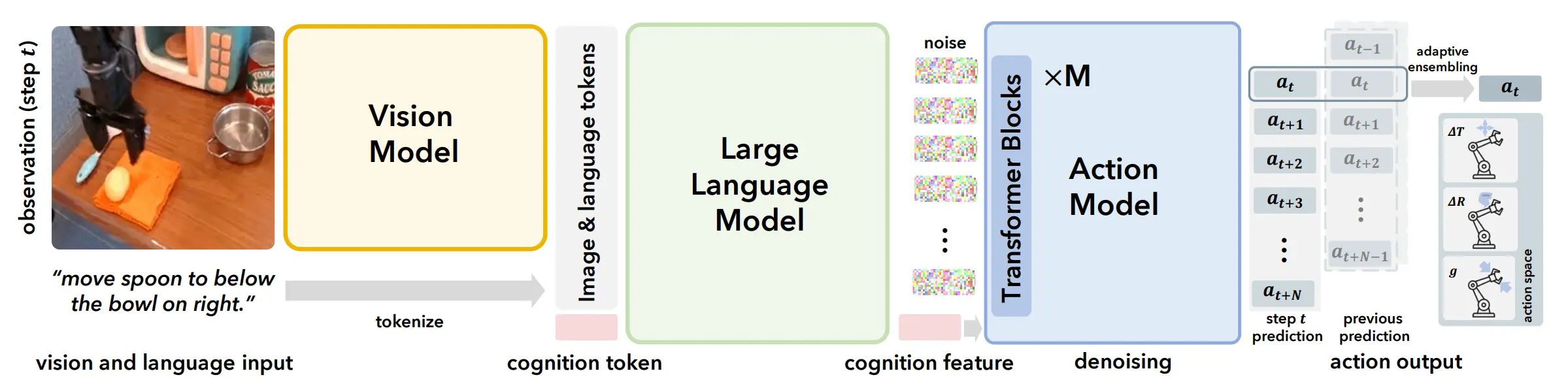
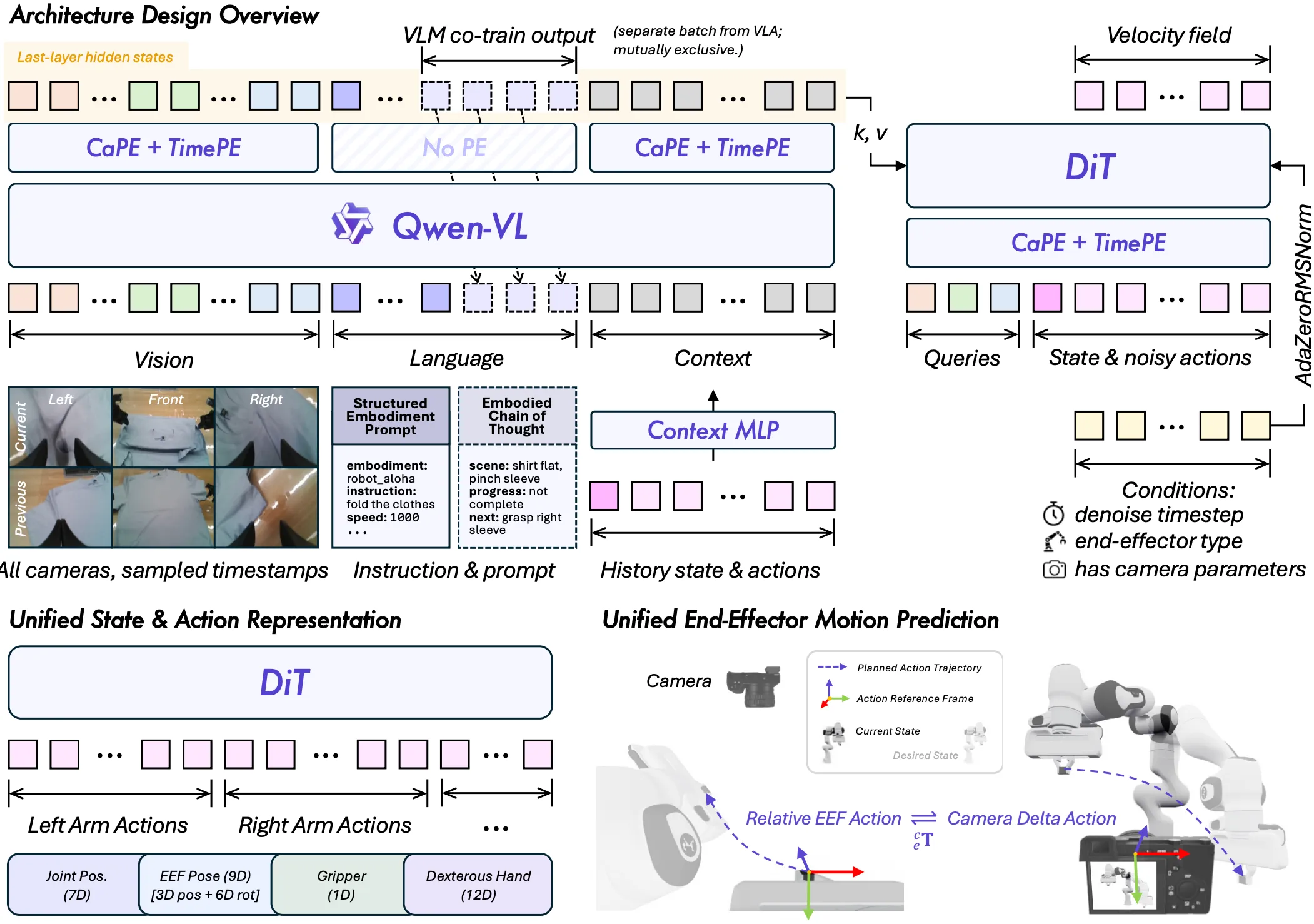
分层规划 / Sub Goal#
在发展的过程中,包括 Sub Goal Prediction 的任务设计,使得一些研究者认为需要 Reasoning 以及 Planning 的能力聚合在 VLA 中,其中一种方案是让模型学习一种 Interleave 的模式。
| 论文 | 主要贡献 |
|---|---|
| OneTwoVLA | 使用 Token(BOR & BOA)在 Reason 以及 Action 之间切换 |
| Inspire | 在模型进行输出 Action 之前增加了几个问题,即相关物体相较于机器人的方位作为 CoT |
| CoT-VLA | 先预测 Future Obs 作为 CoT |
| Vista-WM | WM 预测 Future 作为 System2 输入给 system1 |
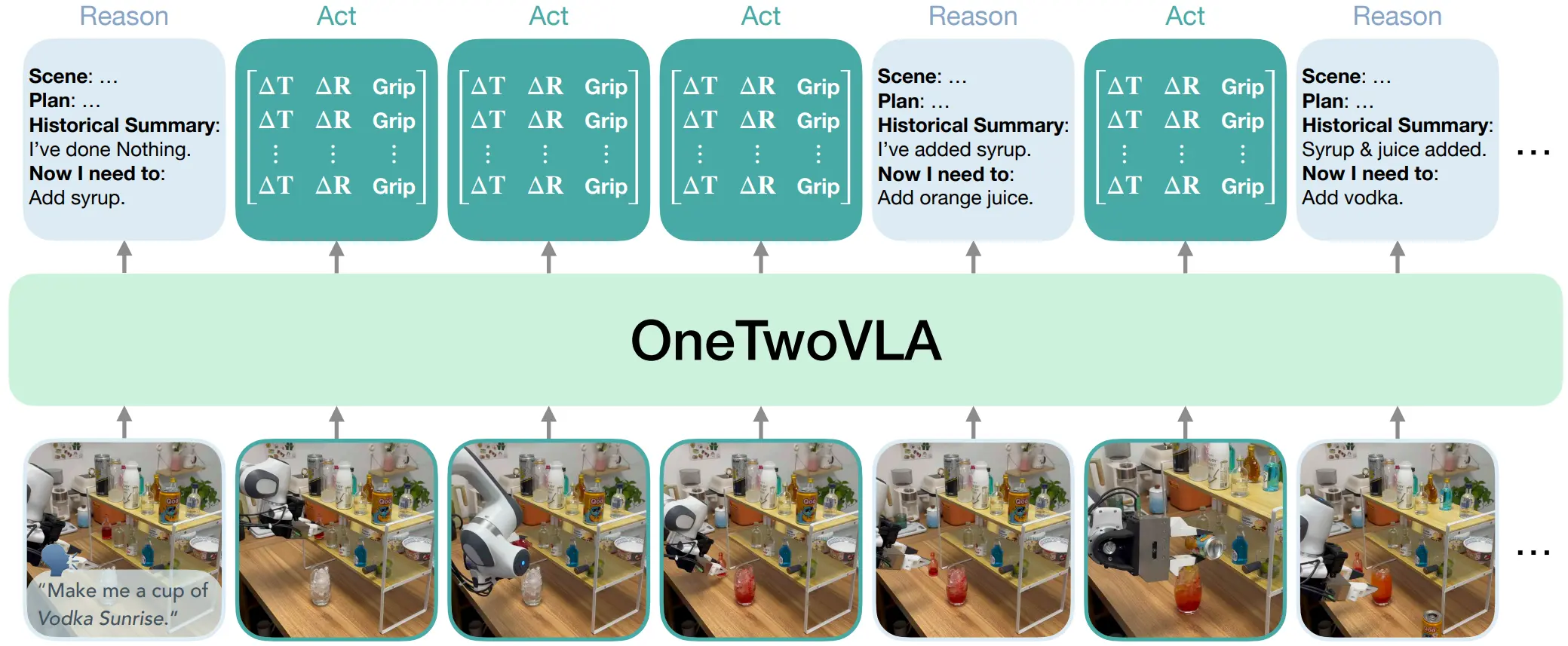
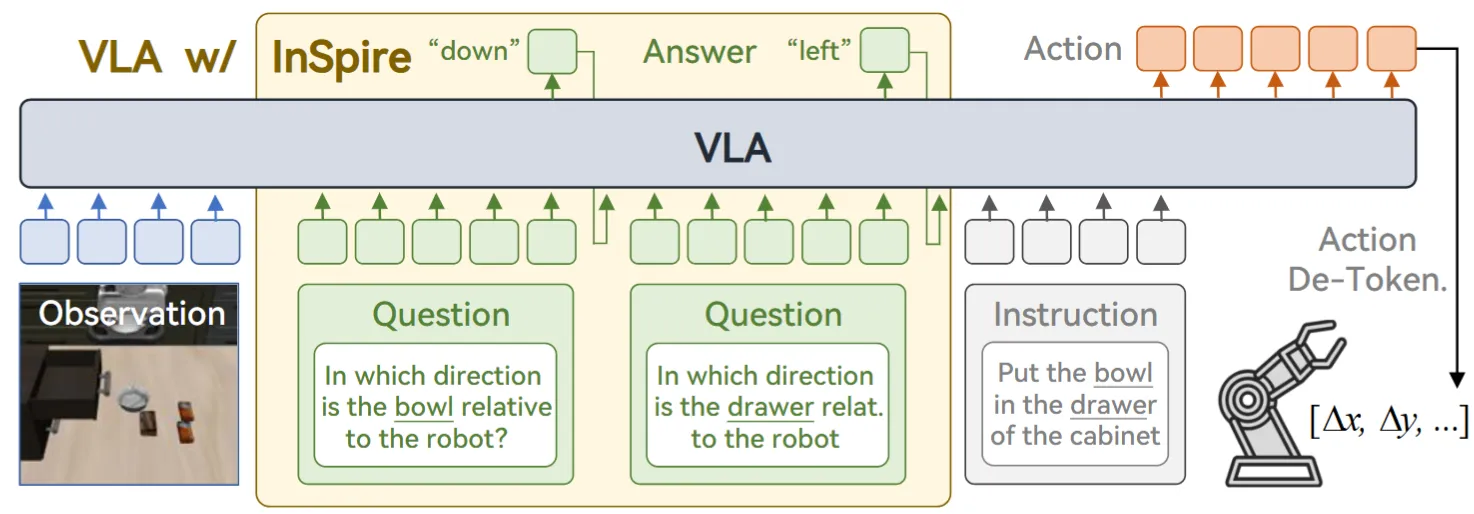

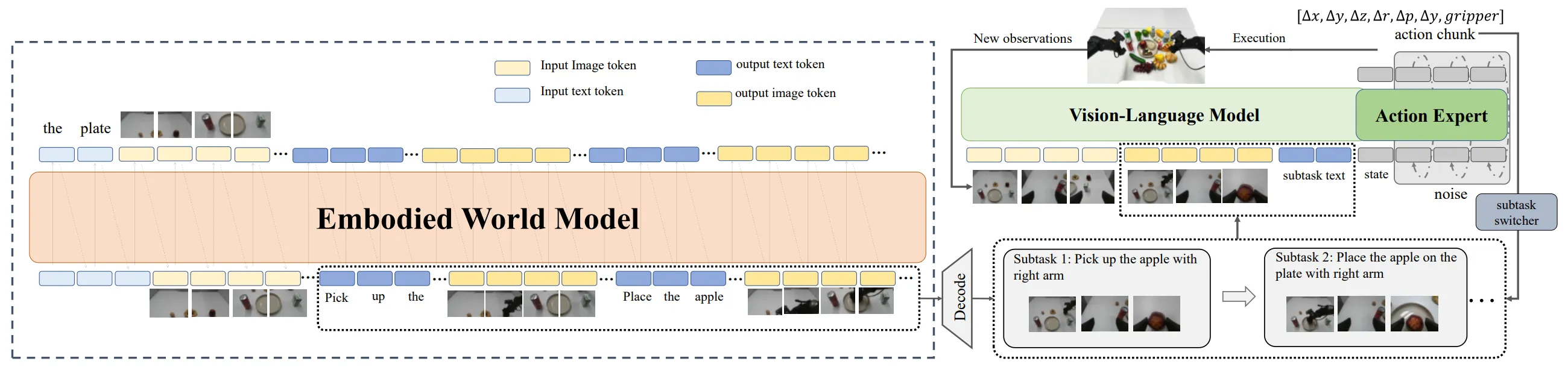
同时,在一段时间的发展之后,业界开始搭建一些更加复杂的双系统结构,来让模型具有记忆能力并且可以完成长时序的任务。这里一个经典且简单的实现来自 MEM,直接使用 VLM 来做长时序总结,并且使用 Video 输入 System1 Policy,来达到短时序能力。
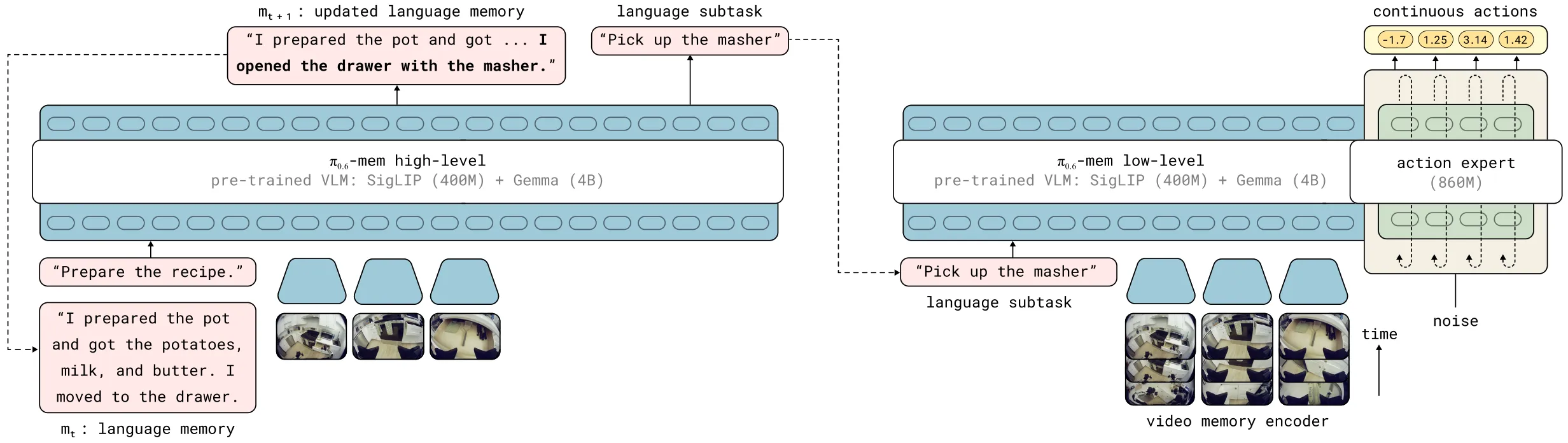
跨本体混合训练#
同时, 使用的预训练中包含多种不同的机器人数据,使得一些研究者开始研究如何进行跨本体的预训练,这其中 使用比较直接的 Zero-Padding 的方案,于此同时一些其他的研究如下:
| 论文 | 主要贡献 |
|---|---|
| RDT-1B | 使用 Unified Action,即将不同的本体的动作分配到一个很长的 Space 上的不同位置 |
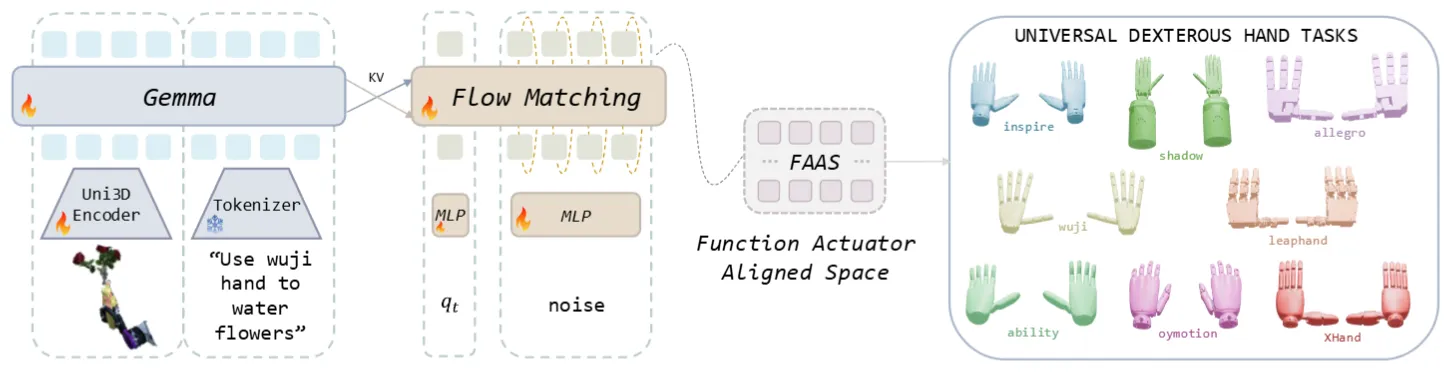
| UniDex | 灵巧手的 Unified Action Space,功能性对齐,即 FAAS,依然是 Pi-like 架构 |
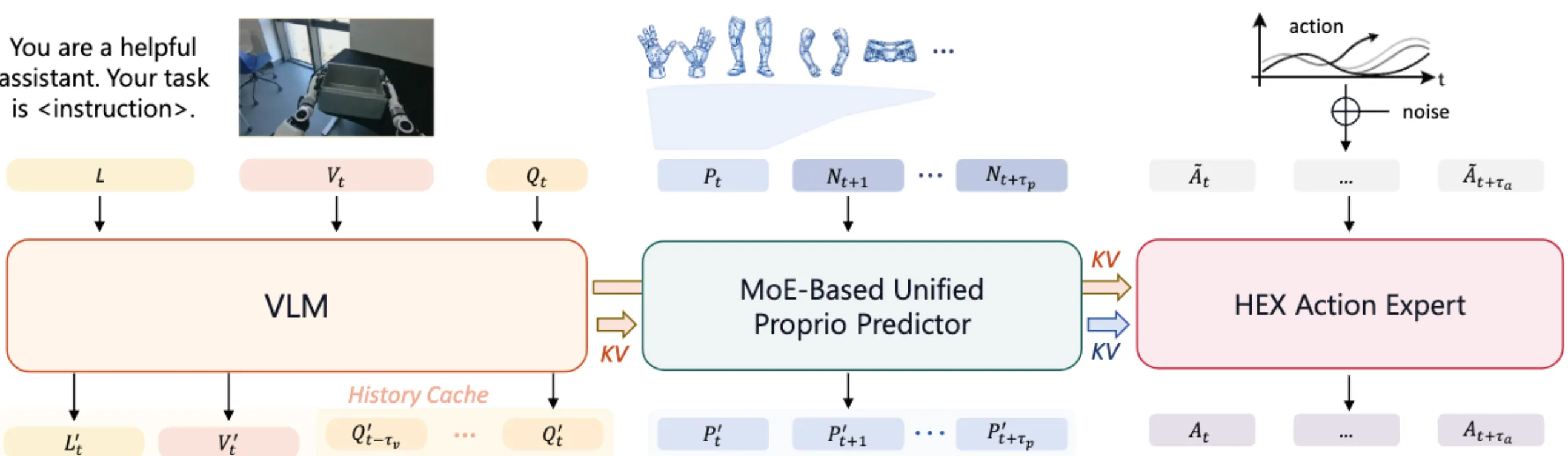
| HEX | MoE 作为中间件预测未来状态来学习跨本体 Humanoid 数据 |
| ACE-Ego-0 | 用 URDF Encoder 输入 Robot Token 以及构造 Human Token 到 Actor 的 GR00t-like VLA,使用 Unified Camera-Space Action |
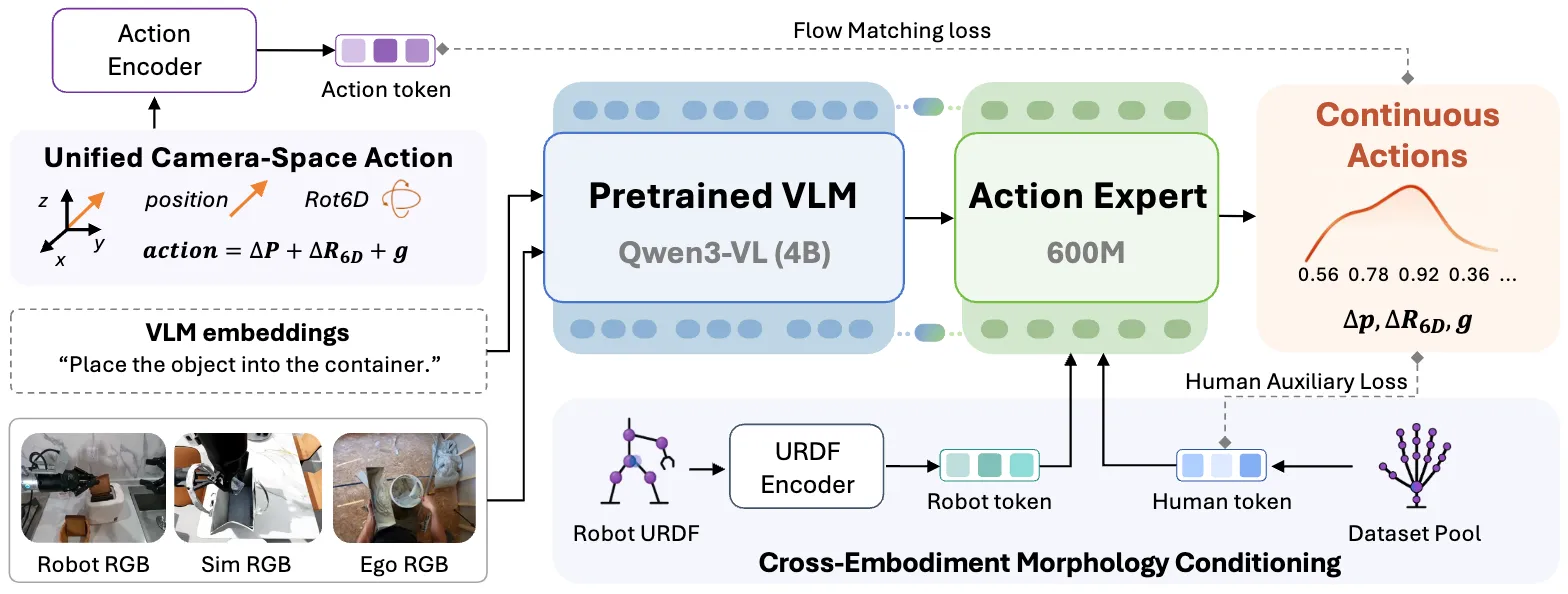
Action Token#
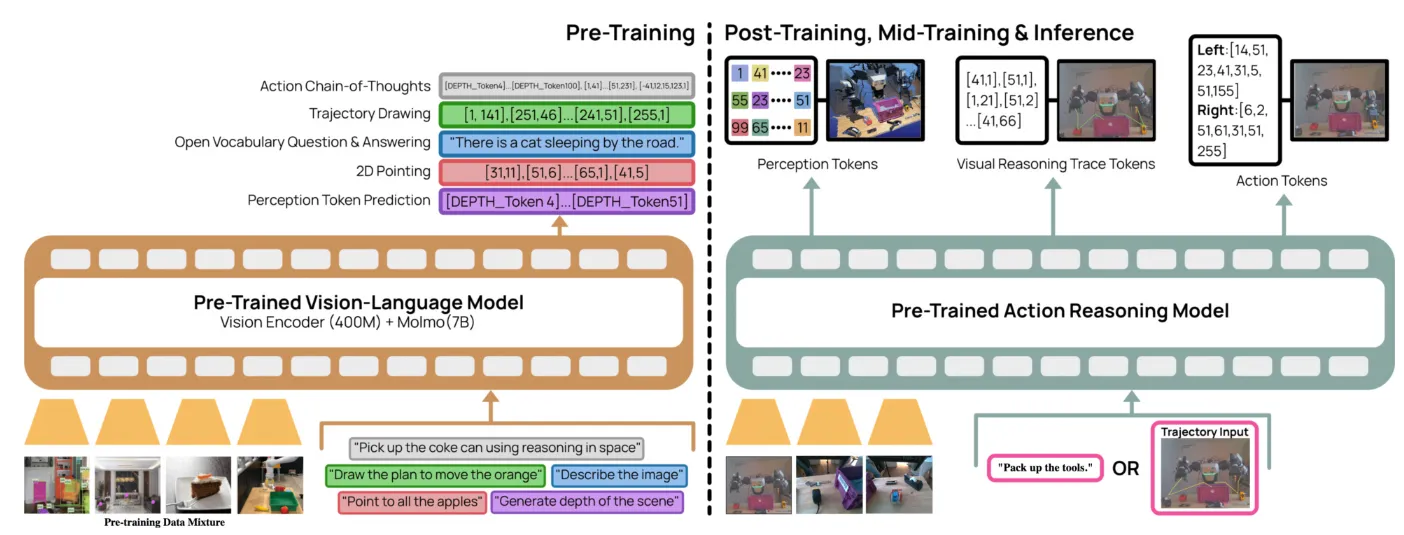
另外,在 中所探索的,在预训练中使用 Action Token,使得一些研究者开始探索动作离散化的方案,这其中 系列中使用的是同样出自 PI 的 FAST Tokenizer;当然,也有一些工作则是纯粹的 NTP 的范式,并且事实上一部分相当不错,主要是采用了更加好的 Training recipe 或者更好的 action token,我们在这里统一总结:
| 论文 | 主要贡献 |
|---|---|
| MolmoAct | Embodied VLM 预训练 + 深度感知 token,轨迹 token 以及 action token 后训练 |
| VLA-0 | VLM 直接输出文本 Action 的 VLA,好玩的尝试 |
| RDT2 | 使用 RVQ + CNN 取得离散 Action Token 作为 VLM 时跨本体训练,之后正常 Pi 范式 |
| RDT2 | 使用 Language 对动作的描述作为 Action Token |
| G0.5 | 使用 Action Token 进行预训练的 AR VLA,可以实现有限的泛化 |
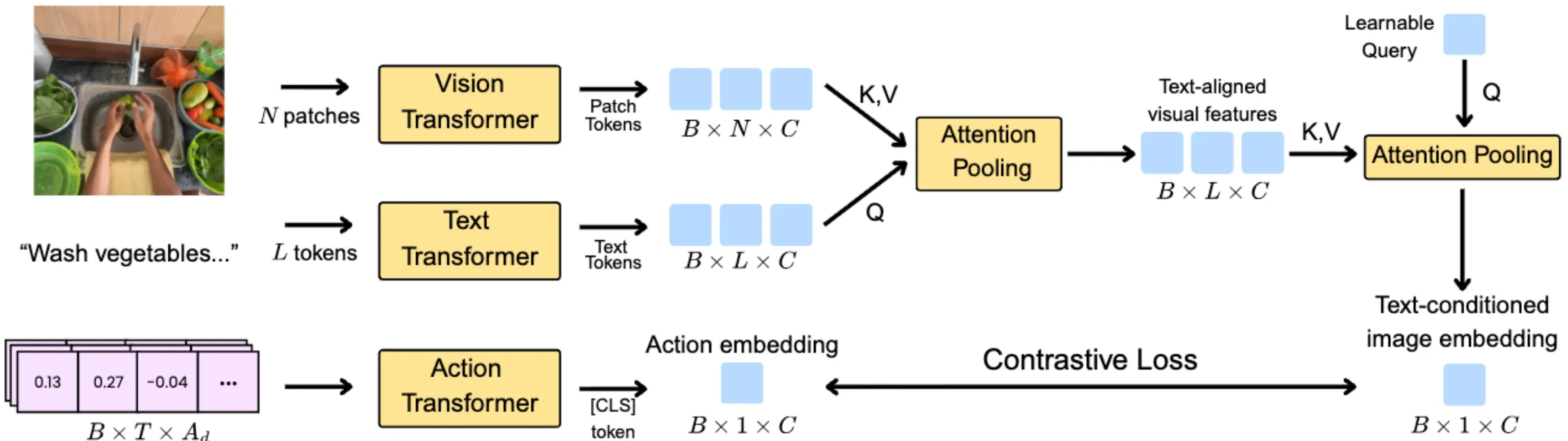
| CAIP | Vision-Action 对比学习构造 Action Token |
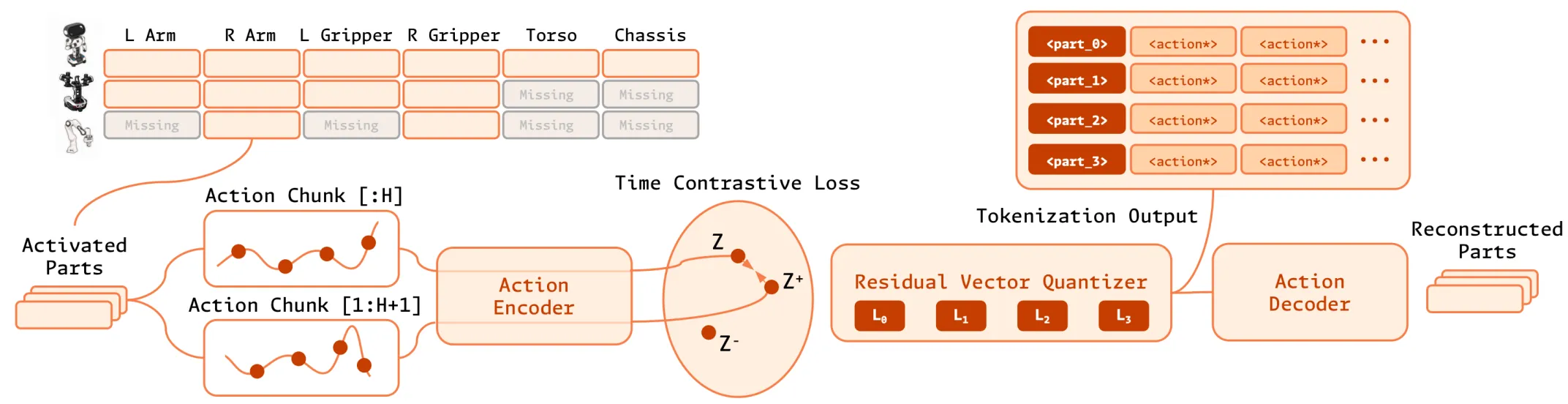
| FASTer | 使用 action patchifier 以及 RVQ Tokenizer |
| Actioncodec | 定义了一些合理的 Training Objective 并且设计了对应的结构 |
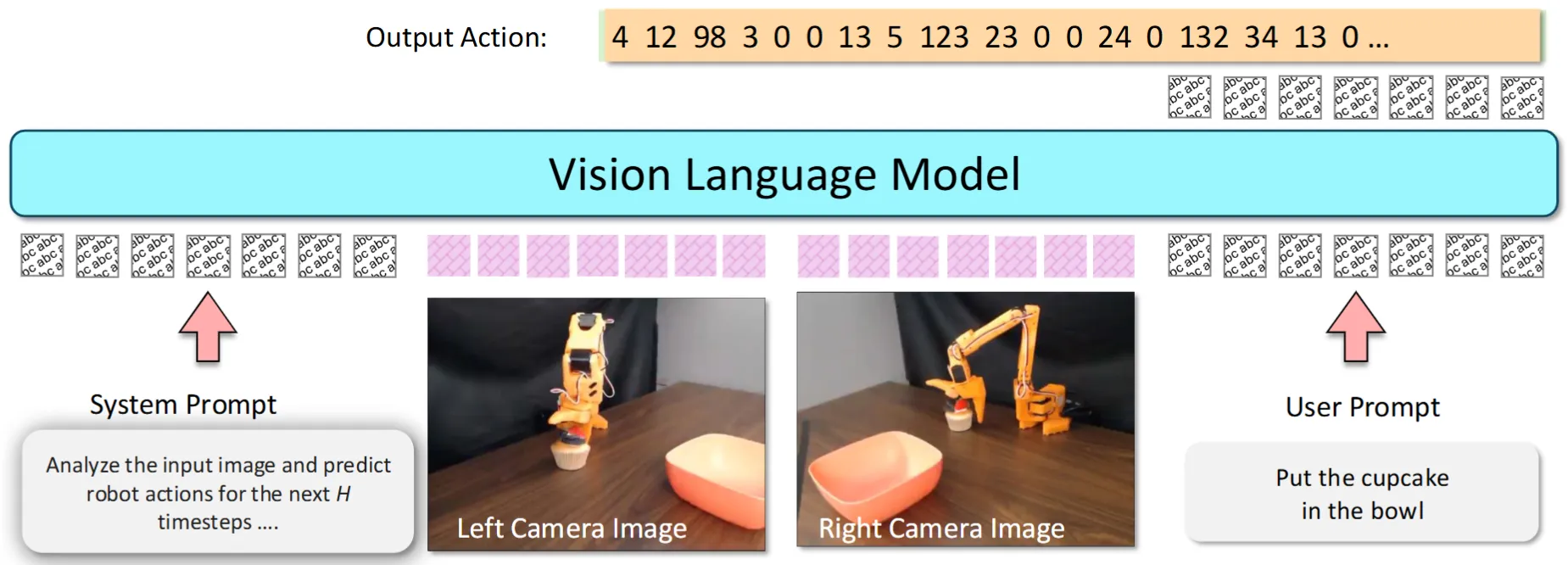

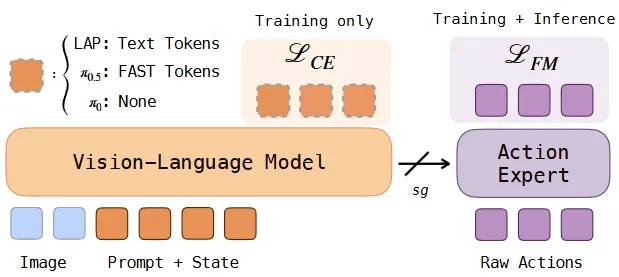
VLM-VLA Co-training#
在这一过程中,从 OpenVLA 开始,VLA 便开始面临一个本质问题,即使用 LLM 或者 VLM 的初衷来自于 leverage 模型的泛化能力,然而在模型的后训练过程中,由于 training objective 的变化以及数据的分布变化,使得模型面临灾难性遗忘的问题,在这方面一系列工作通过不同的角度尝试解决这一问题:
| 论文 | 主要贡献 |
|---|---|
| -KI | 在 VLM 以及 Actor 之间使用 stop gradient |
| InternVLA-M1 | 在后训练阶段依然使用 VLM-VLA 的 co-training |
Latent Action#
GR00t 是 NVIDIA 出品的另一系列的 VLA 模型,本身使用 Cosmos VLM 的 Hidden State 作为 Condition,提供给下游的 Actor。相较于之前的 系列模型,除了连接方式上的差异,GR00t 引入了 Latent Action,即通过 VAE 的方式从视频中提取的一种动态特征,可表征 Action 类似的含义,作为预训练的组成部分。
LAPA 较为早期提出了 FDM 和 IDM 模型的设计以及概念,一个 Encoder 输入 以及 预测 ,Decoder 输入 以及 预测 ,从此我们认为其中的 可以表征一种动态信息,或者说其实本身就是预测光流的表示。
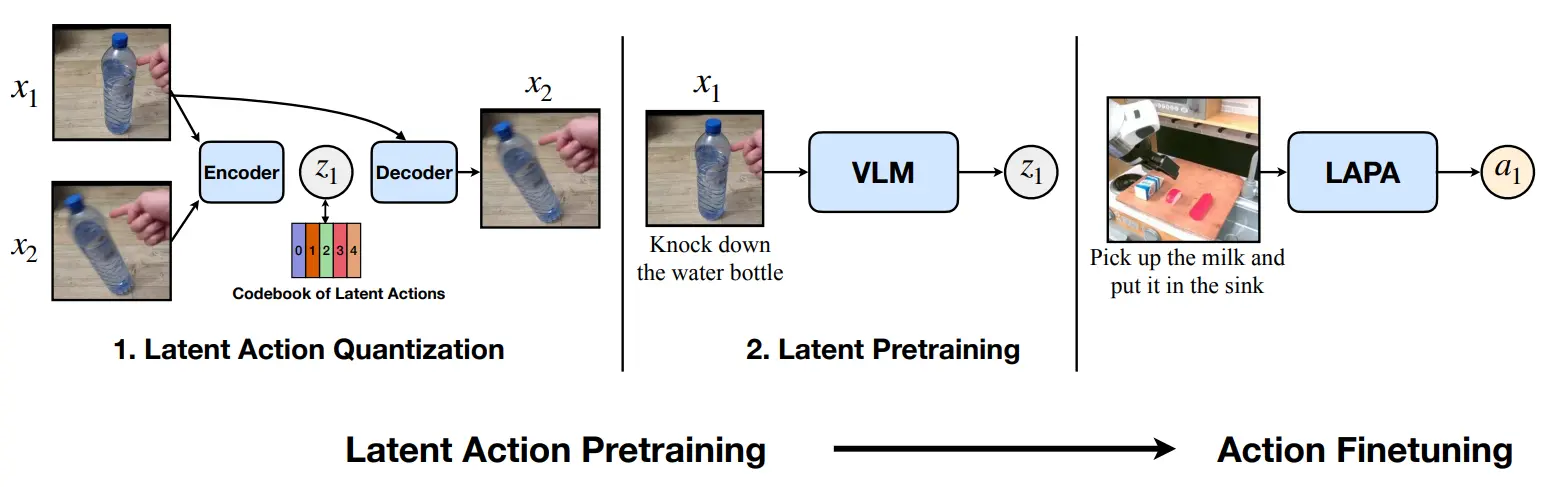
不过 LAPA 的设计存在一些问题,这些画面的变化不止包括动作本身,还有其他因素,因此后续也存在一些 Follow-up 来解决这一问题:
| 论文 | 主要贡献 |
|---|---|
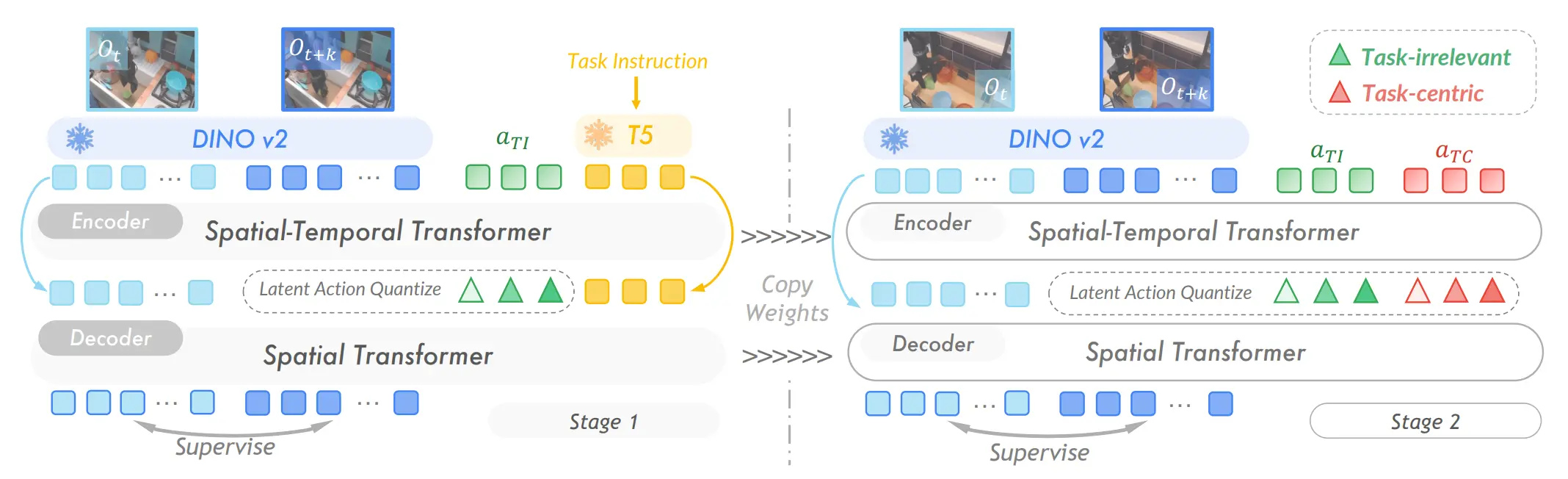
| UniVLA | 提出了一种两阶段的训练来更好地提取 Latent Action |
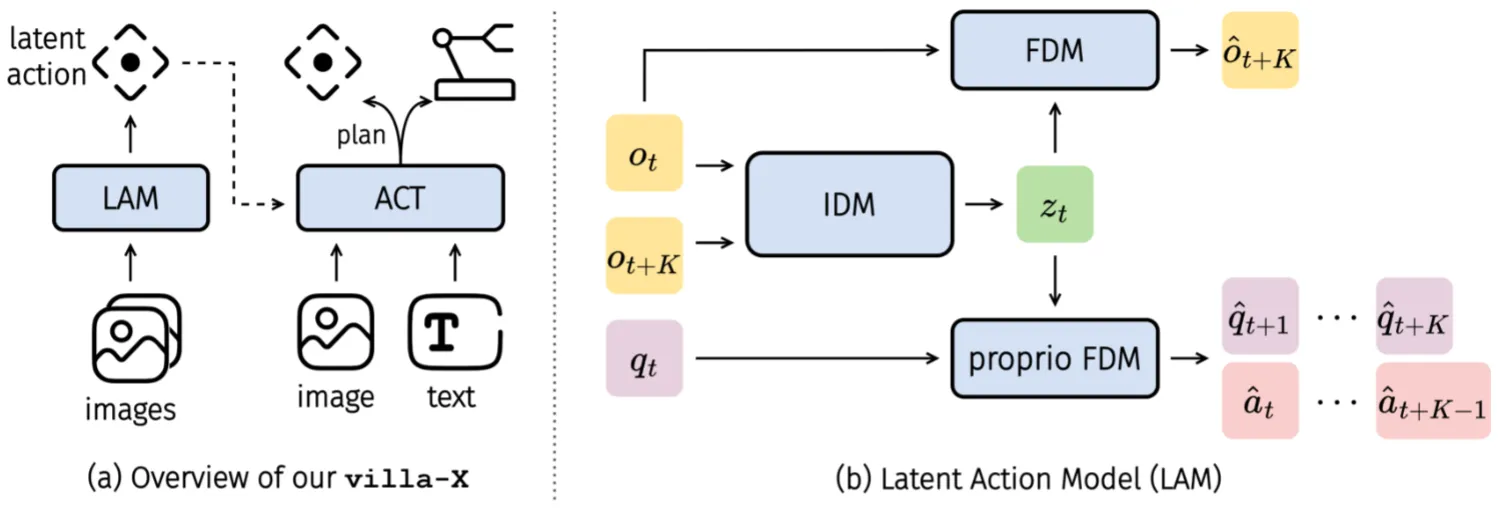
| villa-X | 增加了一组 proprio FDM 来直接基于 z 以及 state 预测未来的 state 以及 Action 来更好提取 latent |
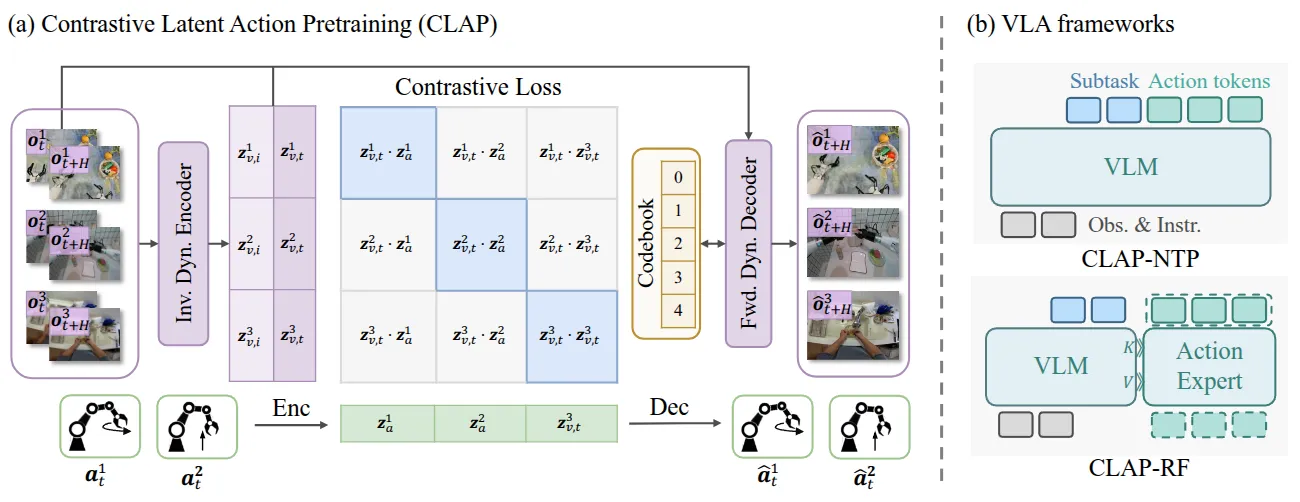
| CLAP | 使用对比学习构造 Latent Action |
Scaling 异质数据#
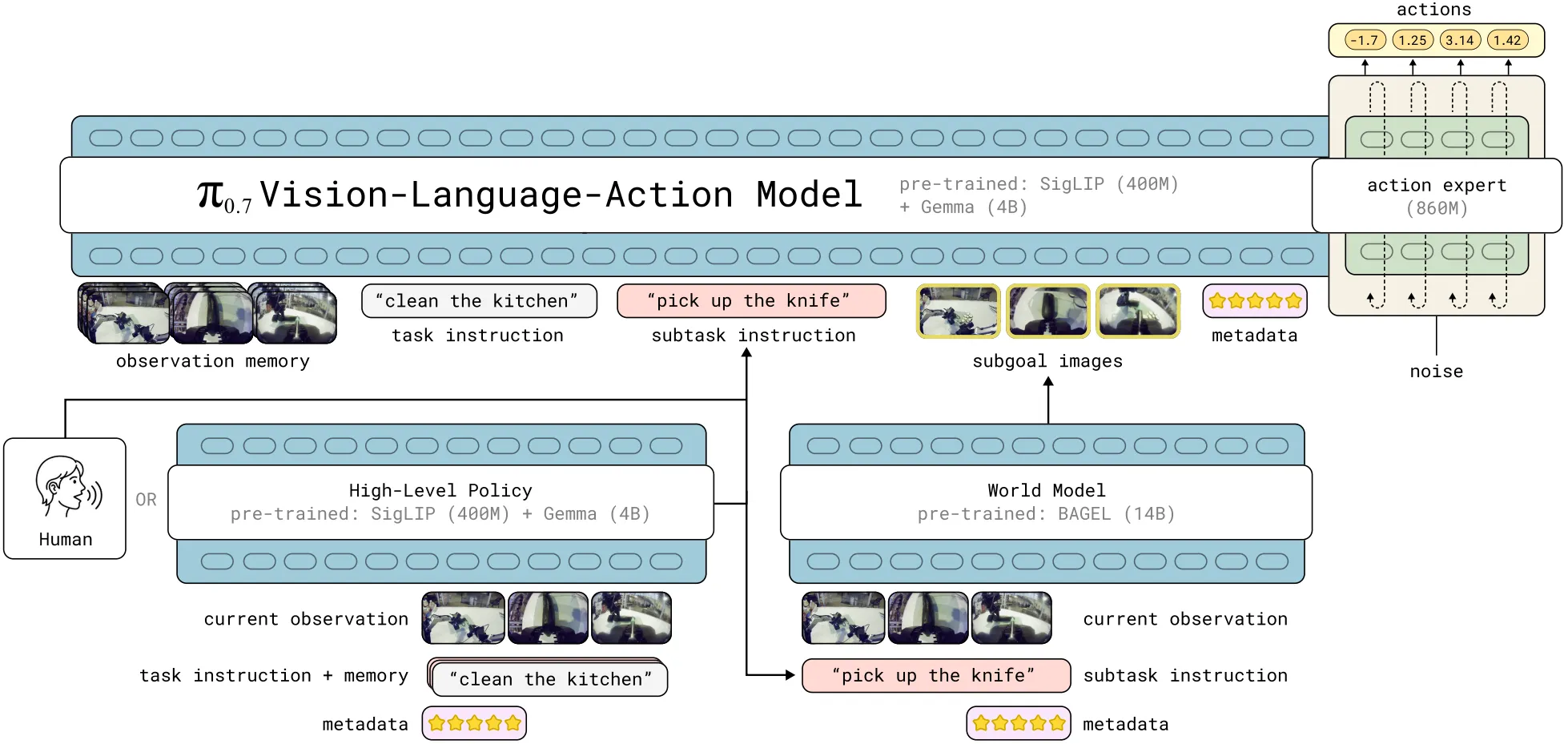
一方面,在训练的过程中,我们希望使用更好的数据进行训练。同时,一个现实在于,大量的数据其实质量参差不齐,并且包括若干失败或从失败中恢复的数据,这些数据同样具有价值。在 中事实上通过输入价值函数的方式来更好地利用那些失败和低质量数据。而与此同时,在 中,抛开蹩脚的使用 Bagel 作为世界模型,其中更是引入了更多的 meta data,这些内容通过文字形式输入到模型中,并且作为模型区分来自不同本体、不同质量以及不同环境数据的凭据。
后续也存在一些 Follow-up 来解决这一问题:
| 论文 | 主要贡献 |
|---|---|
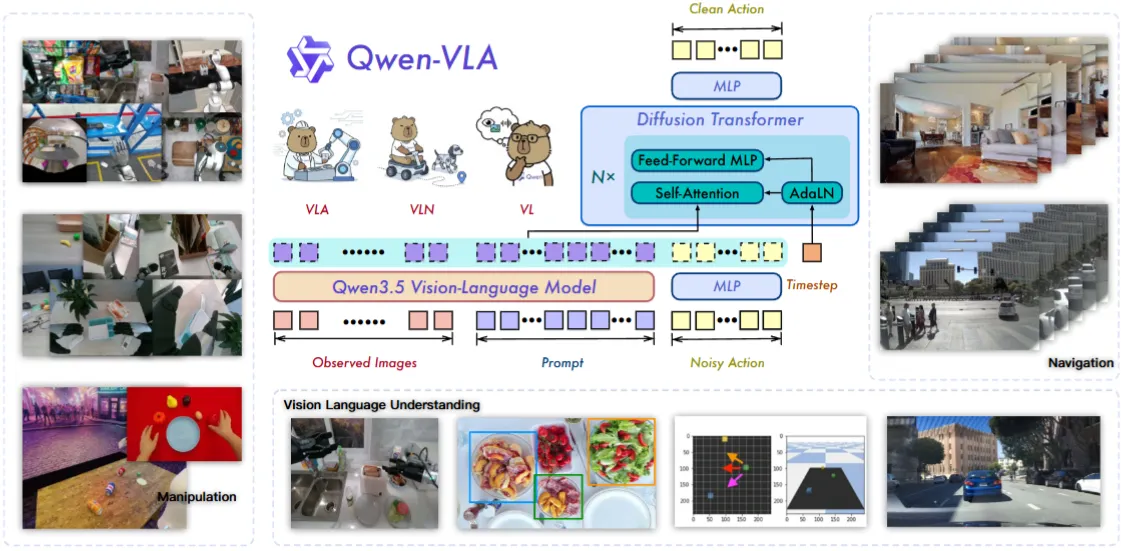
| Qwen-VLA | 使用 meta data 并且进行大规模预训练的 GR00t-like VLA |
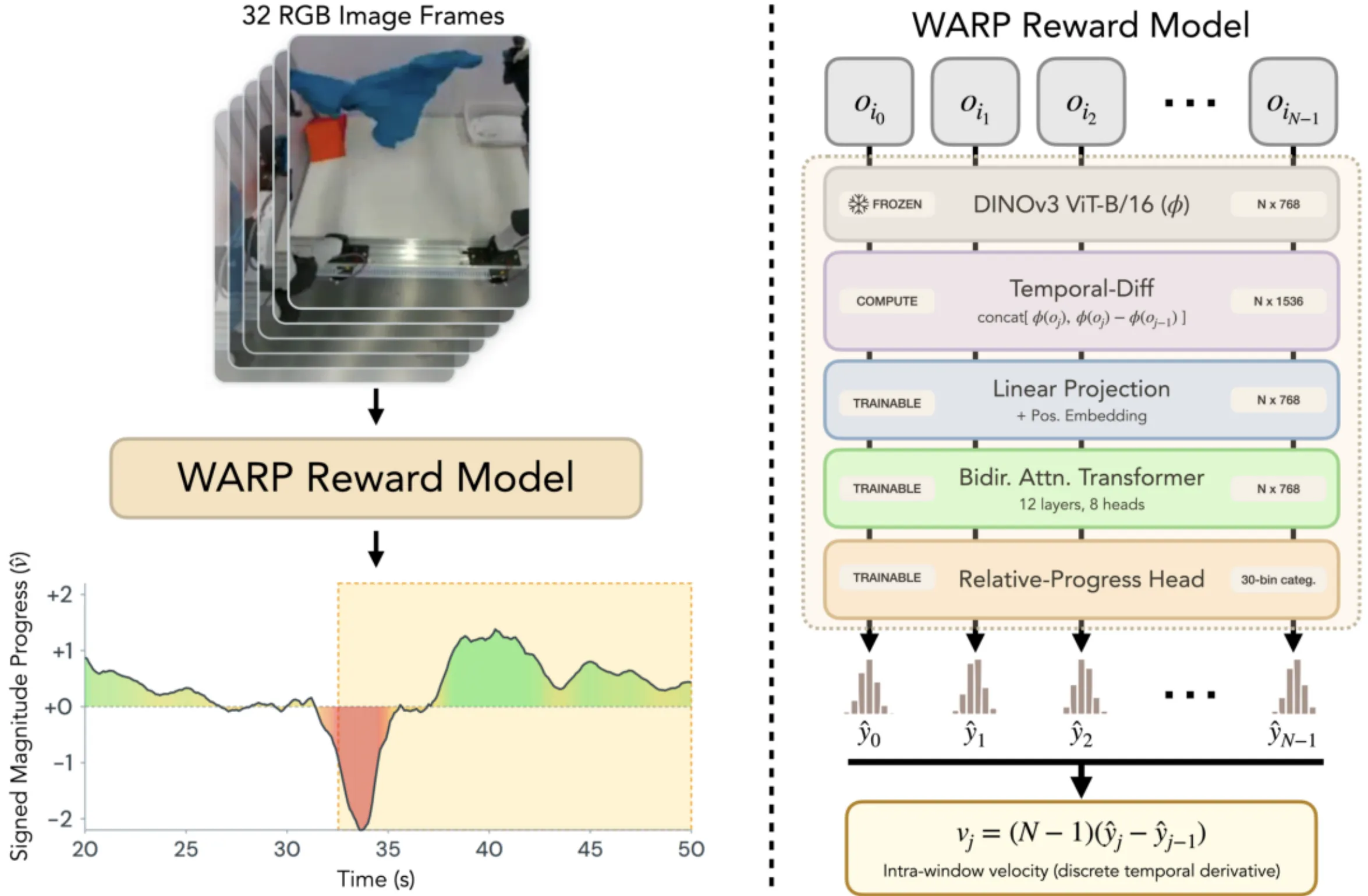
| WARP-RM | 使用不同采样(包括倒放)数据训练相对进度的 RM,并且对于训练数据进行加权训练 |
训练范式#
与此同时,一些工作将更加在领域中前沿的训练范式引入了 VLA 领域:
| 论文 | 主要贡献 |
|---|---|
| VLA-OPD | 在 VLA 训练中使用 On-policy distillation,用 SimpleVLA-RL 作为 Teacher |
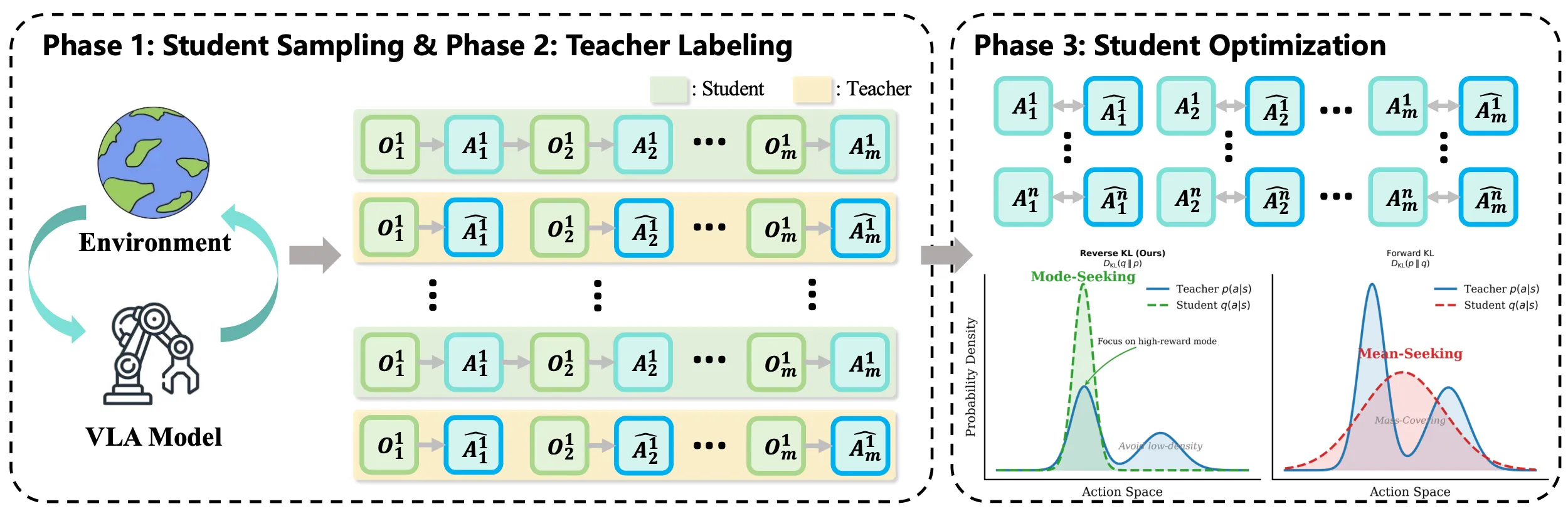
WM-VLA / WAM#
在 VLA 进行长久发展,学界以及业界开始探索另一发展路线,即基于除 LLM/VLM 这一框架之外另一可以 scaling 大量数据并且进行一定程度预训练的预训练模型,即 Video Generation Model,或 VGM,在这一语境下,我们称之为 World Model(事实上在领域中 WM 具有广泛的定义,VGM 是其中一种,但是还有很多其他类型的模型也或多或少称自己为 WM,在这里我们特指 VGM 或者 Action condition VGM 两种)。在这里,另一种常见的称呼是 WAM,即 World Action Model。我们对于 WAM 的介绍会不仅限于那些基于 VGM 的模型,而是对于以预测未来作为模型训练目标的模型的统称。
在比较早期包括一些使用 LLM/VLM 作为 Backbone 的 WAM:
| 论文 | 主要贡献 |
|---|---|
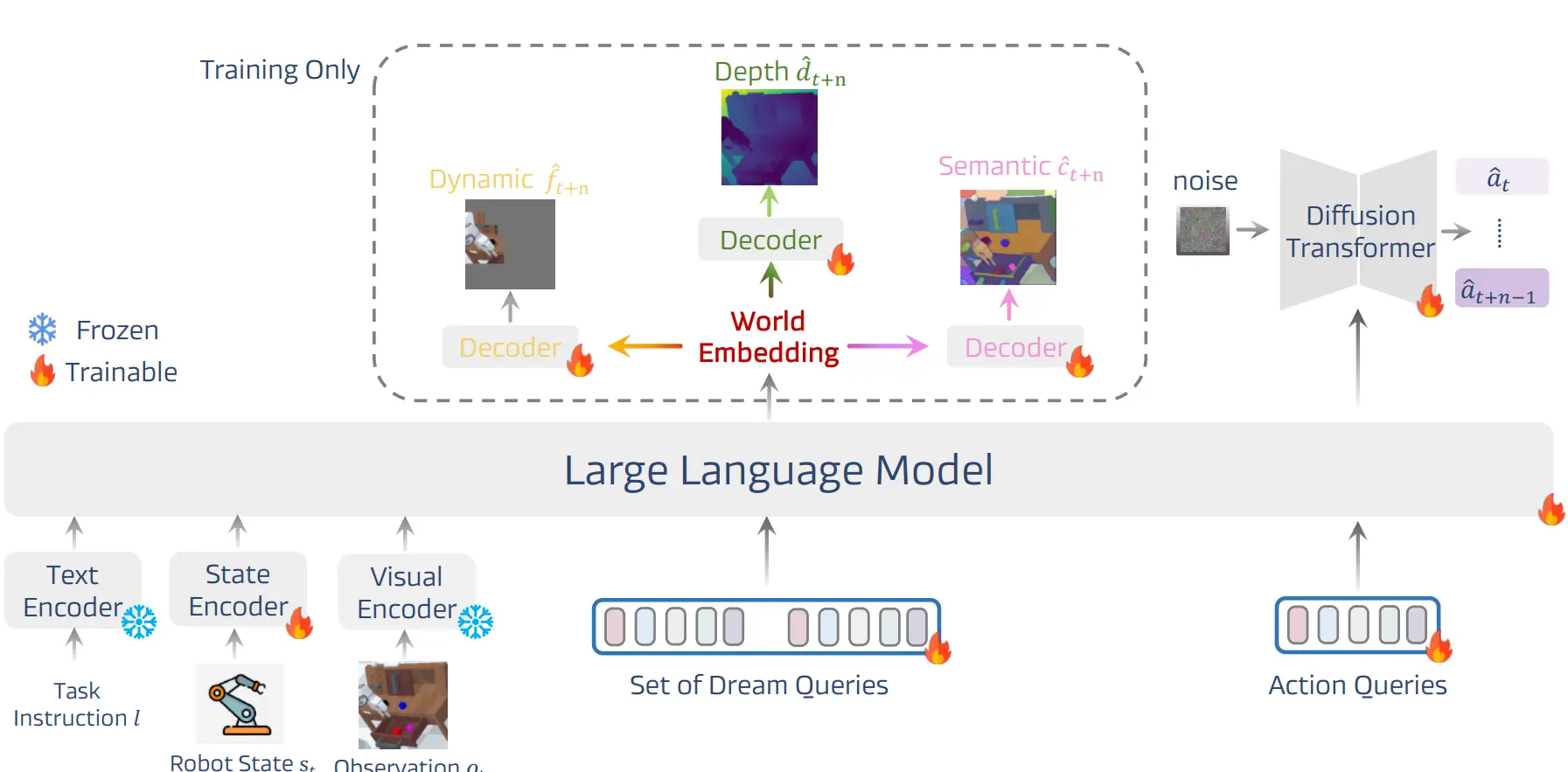
| DreamVLA | LLM 侧预测 Dynamic/Depth/Semantic 的 embedding |
在此之后出现了一些基于 World Model 的 VLA 模型,一种方案是追求完全的 Unifed 能力,桥接 VLM / WM / Actor,一般直接通过 MoT 进行连接,如比较经典的 Motus。这些设计一方面希望 Leverage 各种模型的先验知识,另一方面也可以尽可能更多地利用更多的数据。
另外一些工作则直接基于 VGM,如 VLM-VLA 的范式一样,在此研究 VGM 与 Actor 的交互方式。NVIDIA 在这方面的一系列探索可以说是相当可圈可点的,基于他们的视频模型 Cosmos,先后推出了直接预测全部复杂表征的 Cosmos Policy 以及在此之后进行了更多的打磨,仅预测世界表征以及 Action 的 DreamZero,可以得到号称 Zero-shot 的能力。
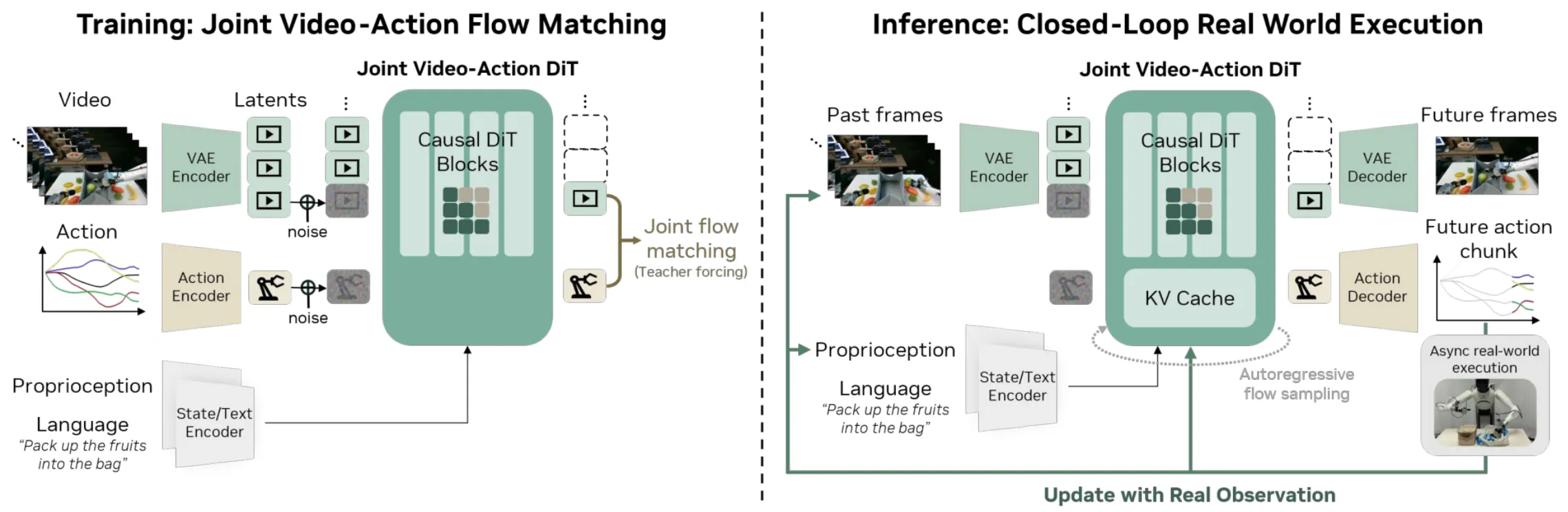
剩余常见的工作在这里列举部分有代表性的:
| 论文 | 主要贡献 |
|---|---|
| Genie Envisioner | 训练 DiT Base 具身 VGM 基模,DiT Latent 作为 Actor DiT condition |
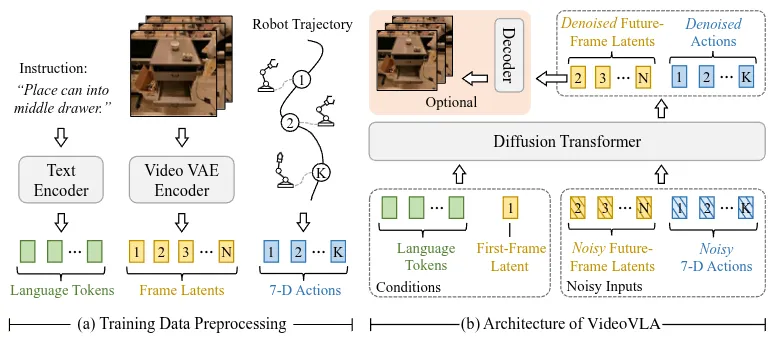
| VideoVLA | DiT VGM 后训练同时预测 Frame Latent + Action |
| InternVLA-A1 | VLM + VGM + Actor 的 MoT |
| LingBot-VA | 解耦 WM + IDM 进行 Casual 预测 |
| LingBot-VA 2.0 | 预训练 VA 模型,MoE Video Model + 正常的 Action Expert,语义视觉动作分词器 + Casual + 前瞻推理 + 多块预测等细节 |
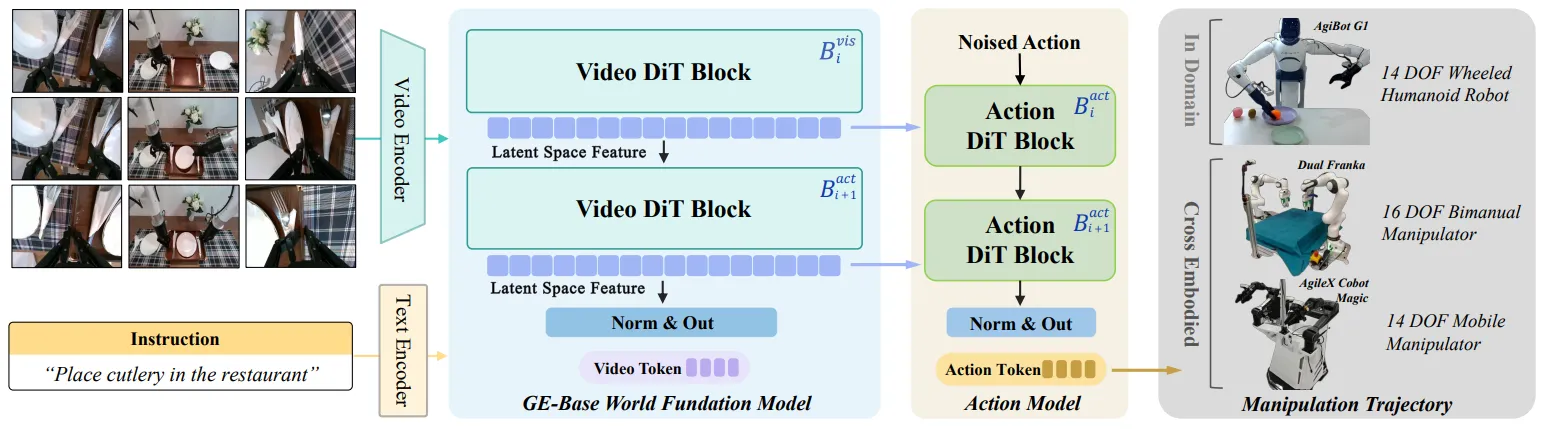
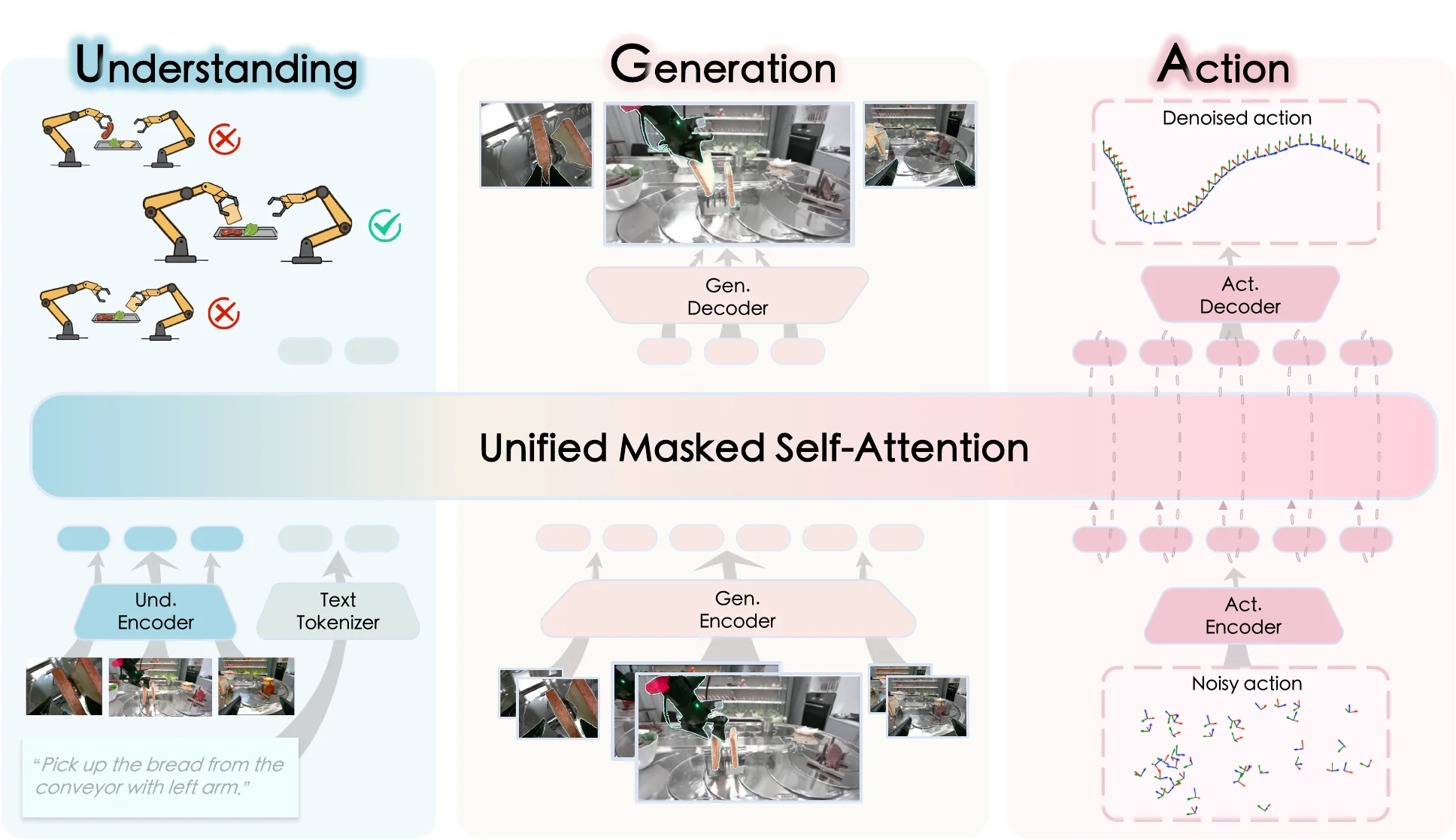
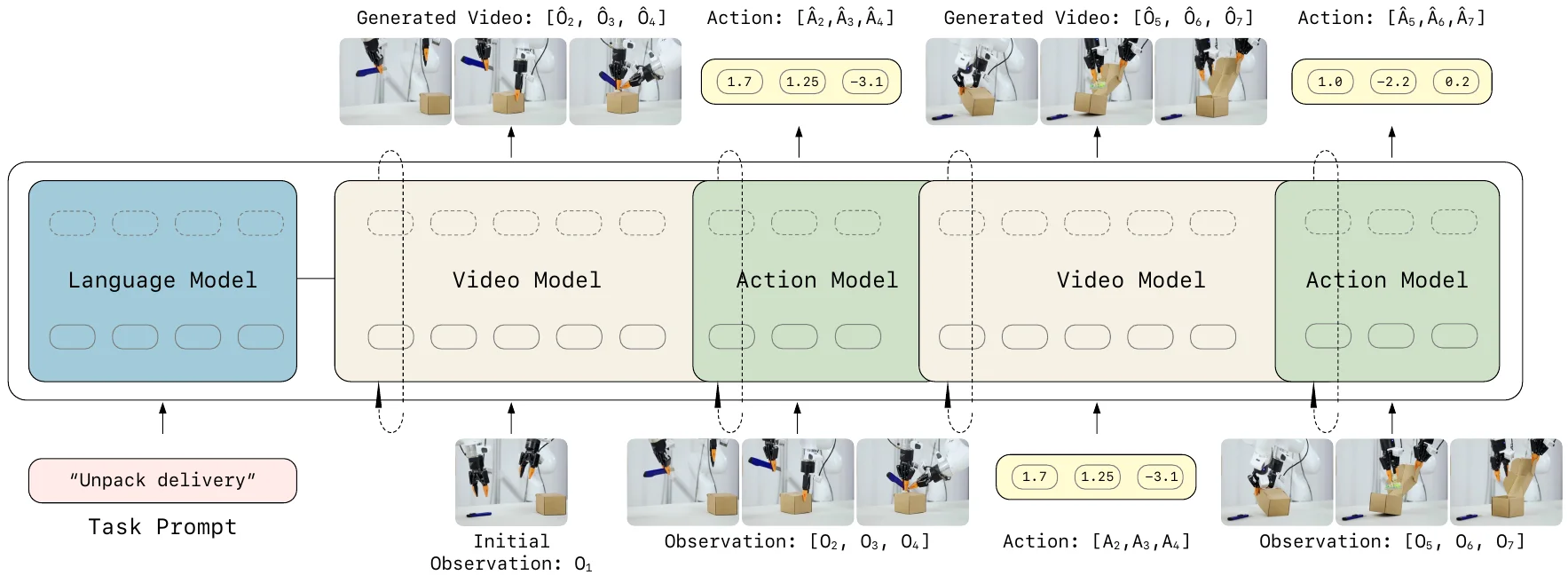
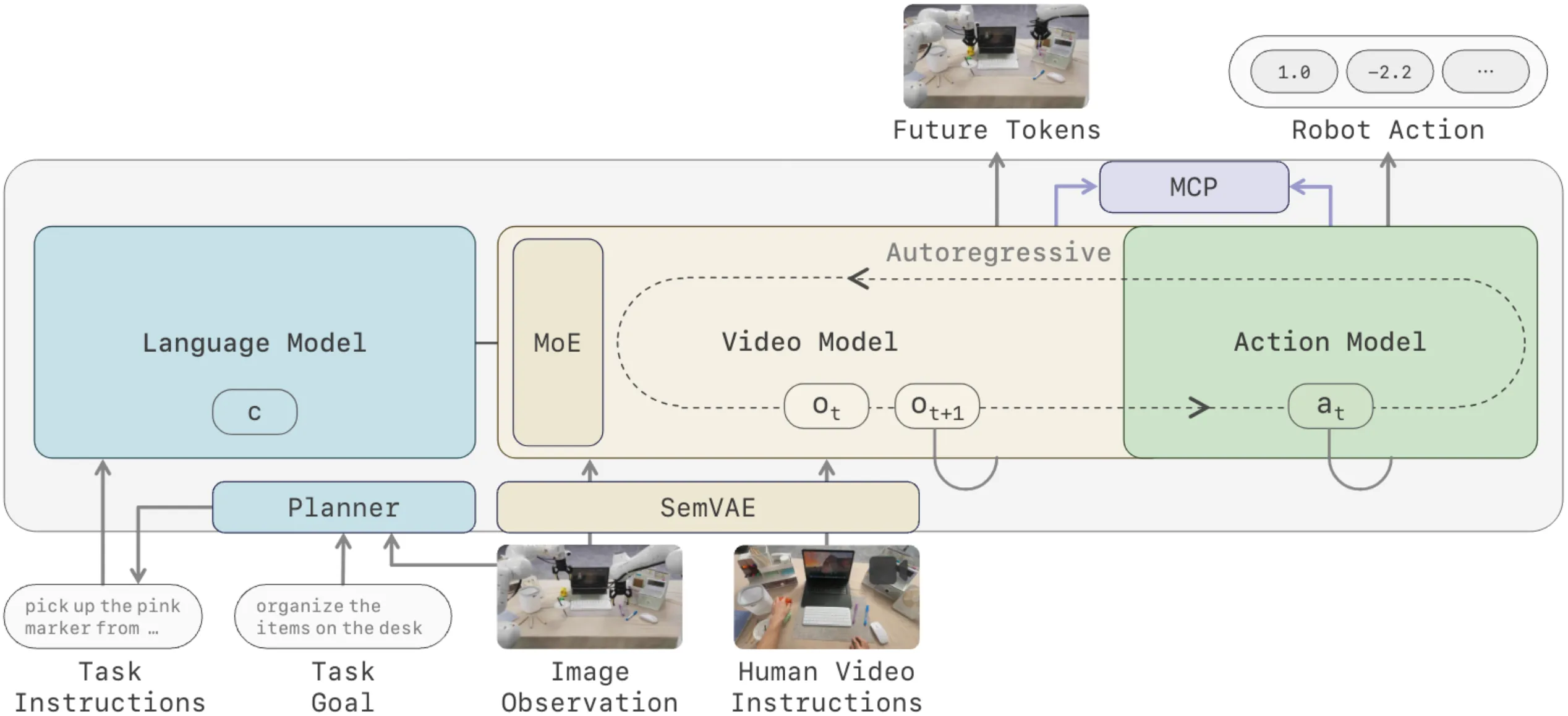
WM as Simulator#
World Model as Simulator 也是在具身智能领域中的另一个
| 论文 | 主要贡献 |
|---|---|
| Ctrl World | 可控多视角 World Model as Simulator |
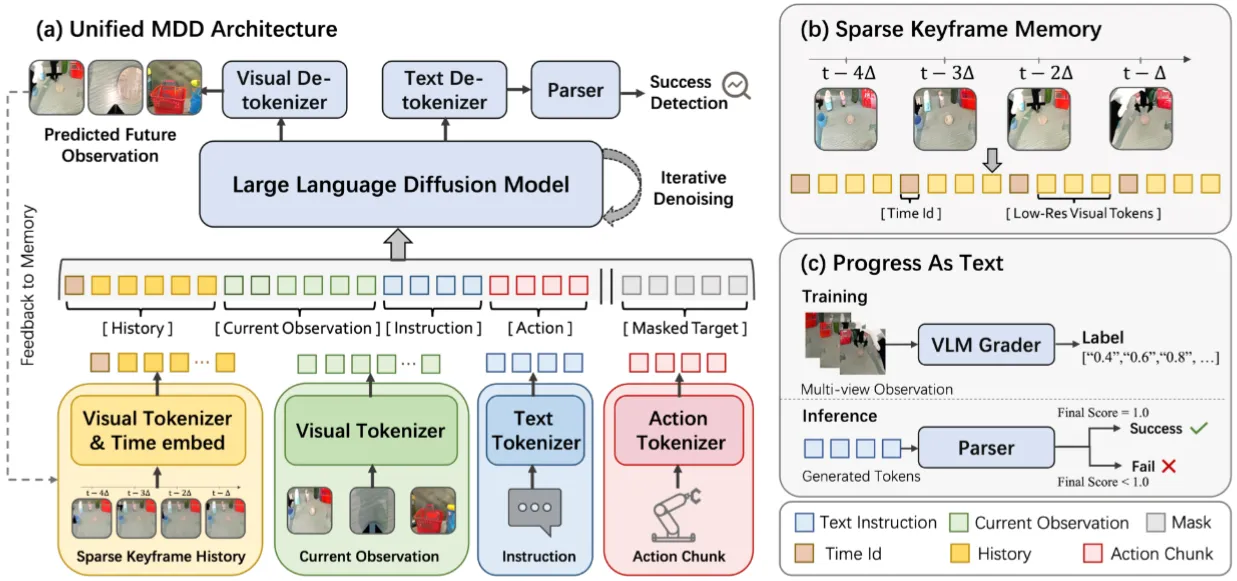
| dWorldEval | 使用 LLaDA 输入 History / Obs / Text / Masked Target,预测 Obs 以及 Success |
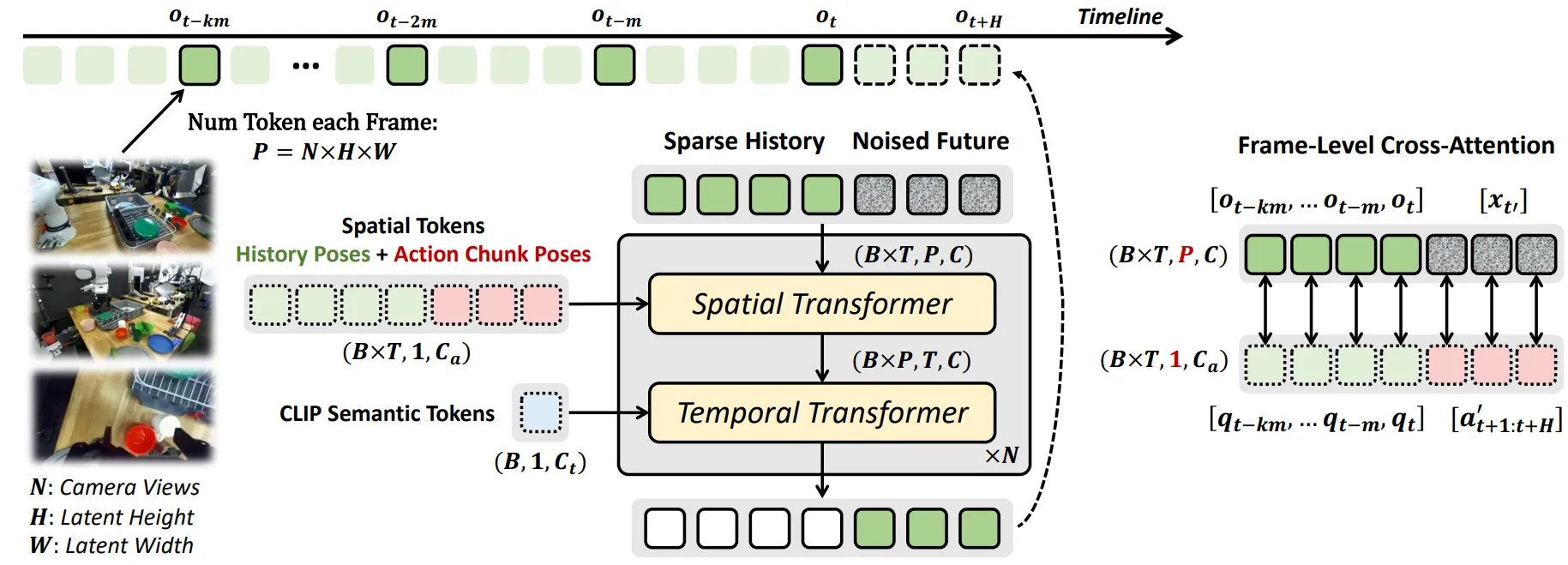
Embodied RL#
伴随着 VLA 技术的发展,在 LLM 以及 VLM 中流行的 RL 技术也迅速涌入了具身领域,在对于 Flow Matching 施加 RL 之前,一些研究先探索了对于 VLM 进行具身导向任务的 RL,比如说轨迹预测等:
| 论文 | 主要贡献 |
|---|---|
| ThinkACT | 对于 VLM 使用 GRPO 训练轨迹预测能力 |
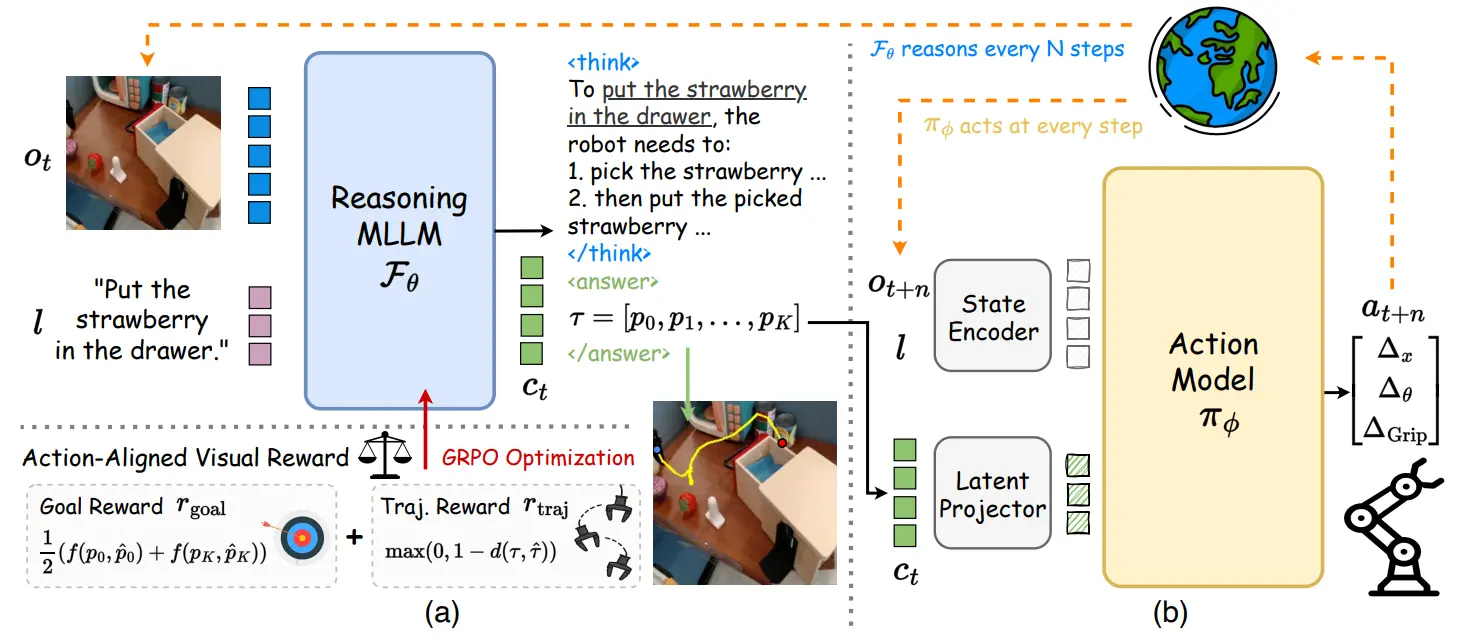
在一些工作在 VLA 领域中进行了一些探索之后,如 等工作开始出现,这些工作伴随一种特性,其中一部分工作试图通过一些方案绕过 RL,而直接在 SFT 中达到类似 RL 的效果,这里如 使用优势值作为模型的输入,本身依然是进行正常的训练,从而可以在部署时,如果输入较大的优势值,则模型趋向于输出优质轨迹,同时在训练中可以 leverage 更多的数据;另外一些工作则进行严格意义上的 RL,通过 online 或者 offline 的方式展开。
以下是一些标准的 RL 训练的工作:
| 论文 | 主要贡献 |
|---|---|
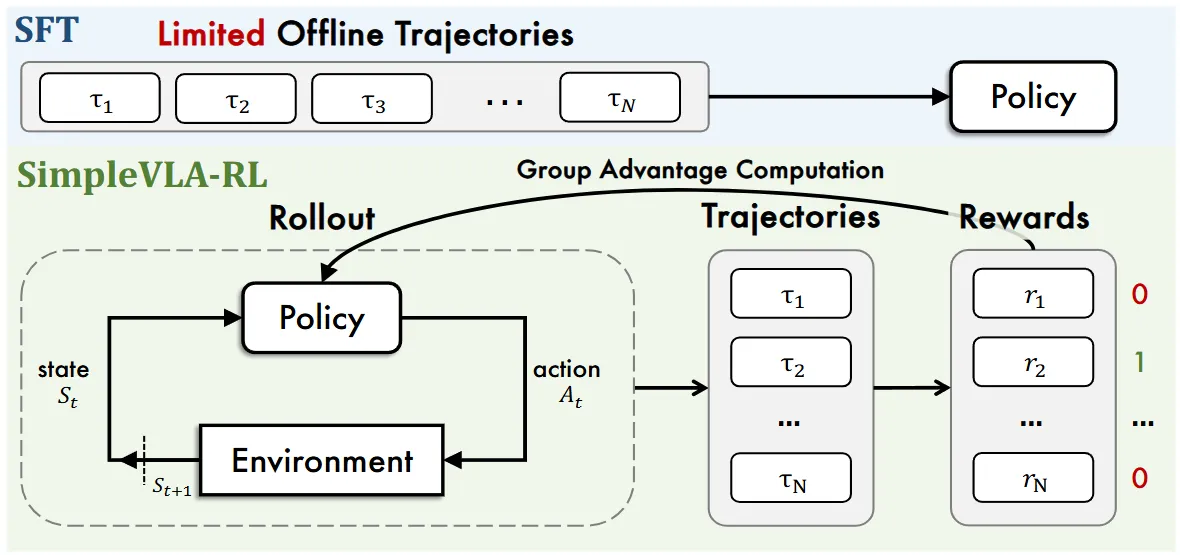
| SimpleVLA-RL | 使用 GRPO 进行 online RL |
| 基于 RLinf 的两种对 Flow 的 RL 策略 | |
| RL-100 | 将降噪描述为 MDP 来构建 RL 并先 offline 再 online RL |
| PLD | RL + 数据回流并通过残差网络学习 |
| GR-RL | 设计并对 Actor 的初始噪声预测器进行 RL |
| OmniVLA-RL | 3D + Text + Actor MoT,用 Flow GSPO 进行 RL |
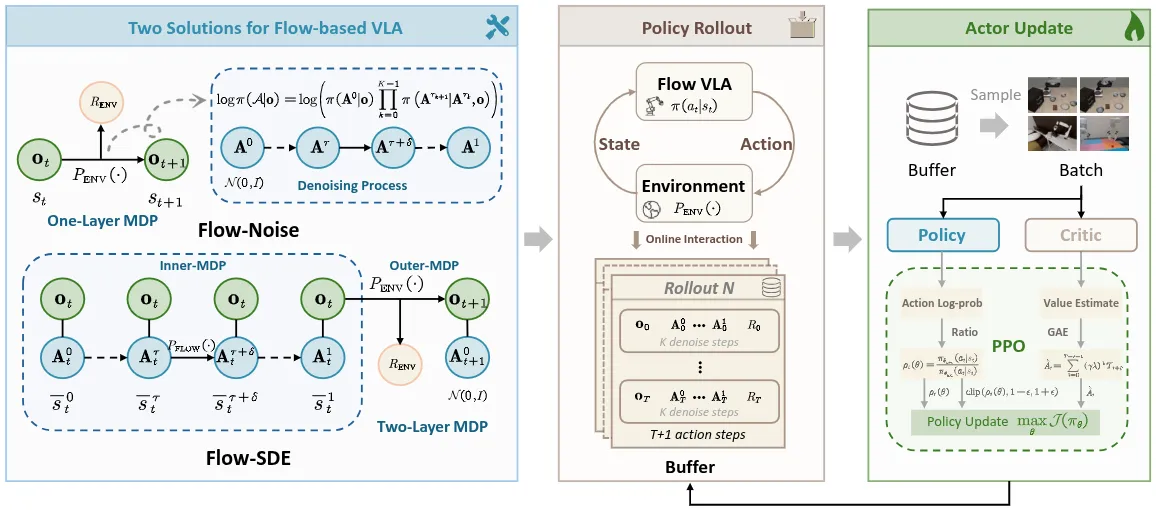
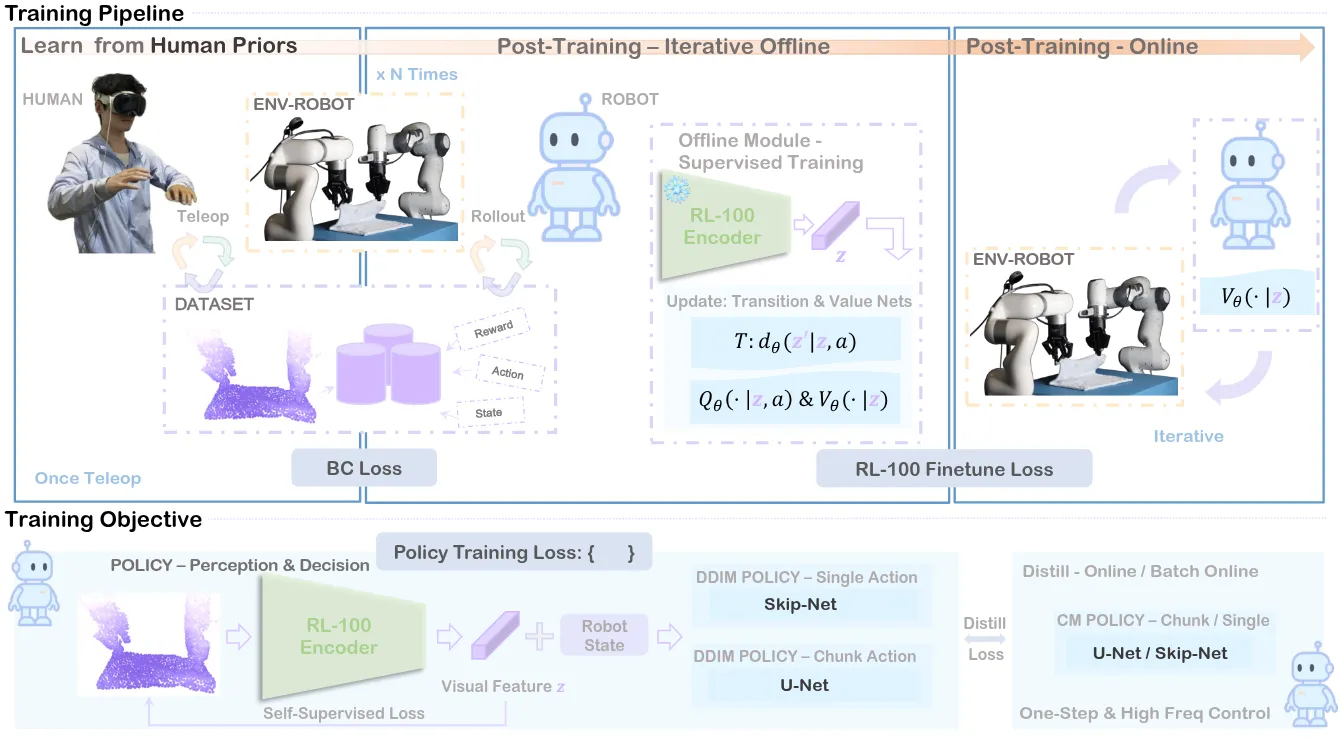
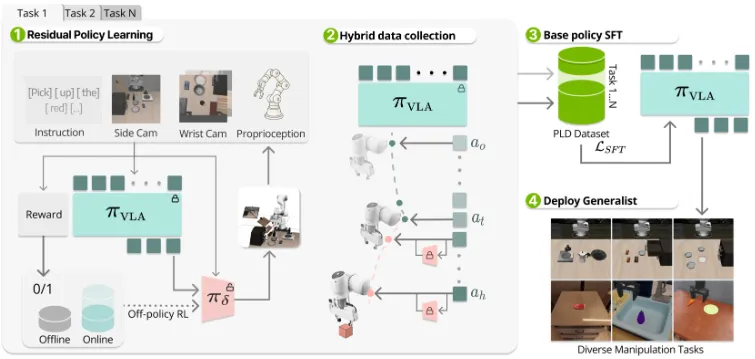
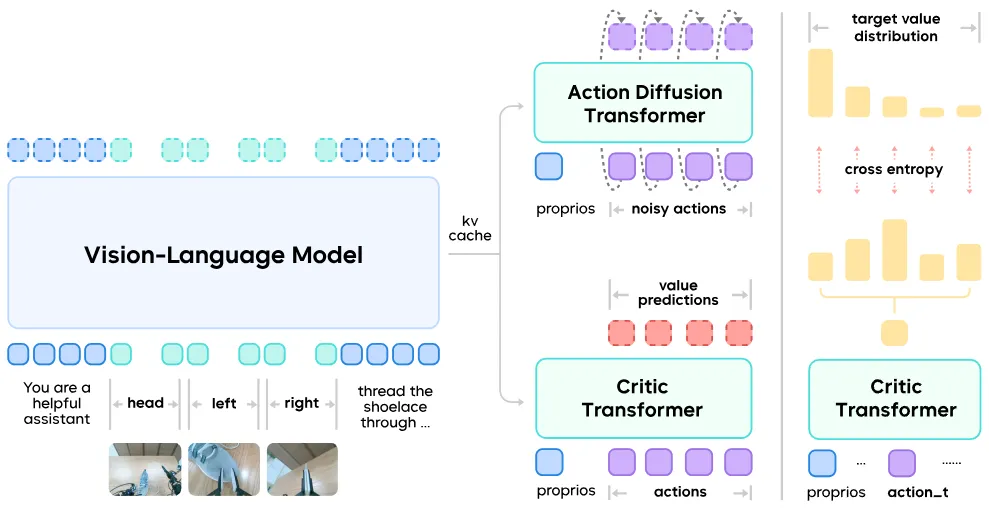
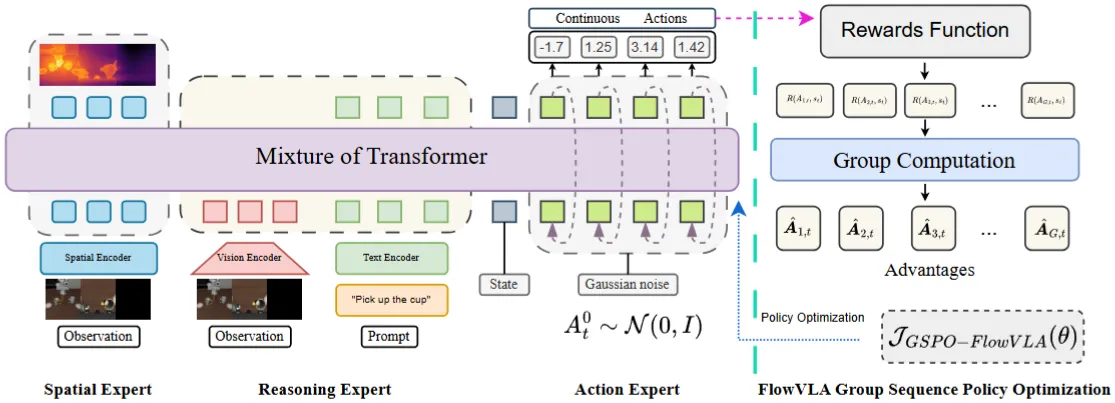
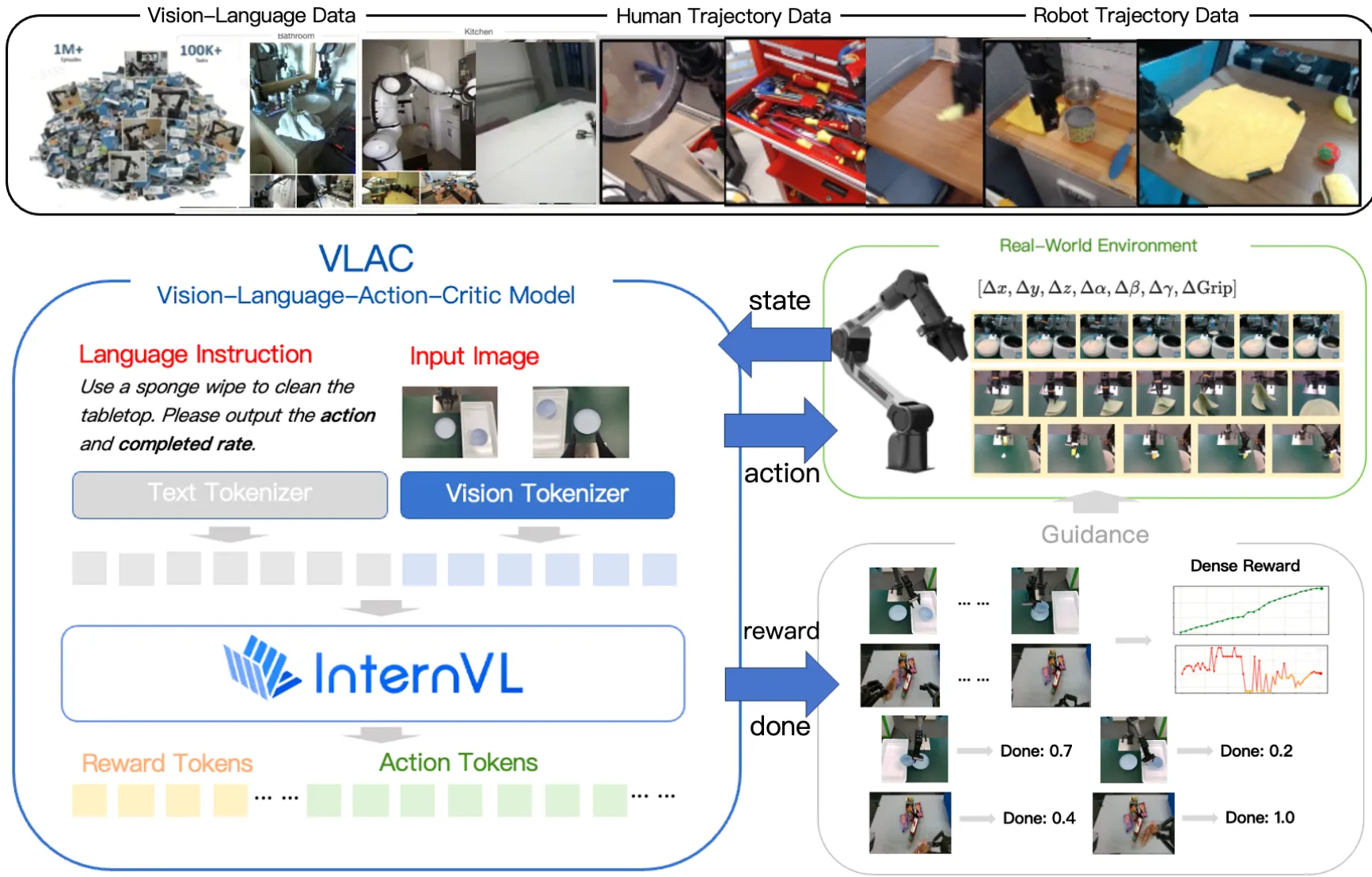
Reward Model#
RL 本身的范式是一个关键,同时,除了通过任务的成功率训练模型,训练一个 reward model 可以更好地提供 dense reward 从而达到好的效果,在这方面一些模型有一些早期的探索。
| 论文 | 主要贡献 |
|---|---|
| VLAC | 从 InternVL 初始化预测 Action 以及 Value |
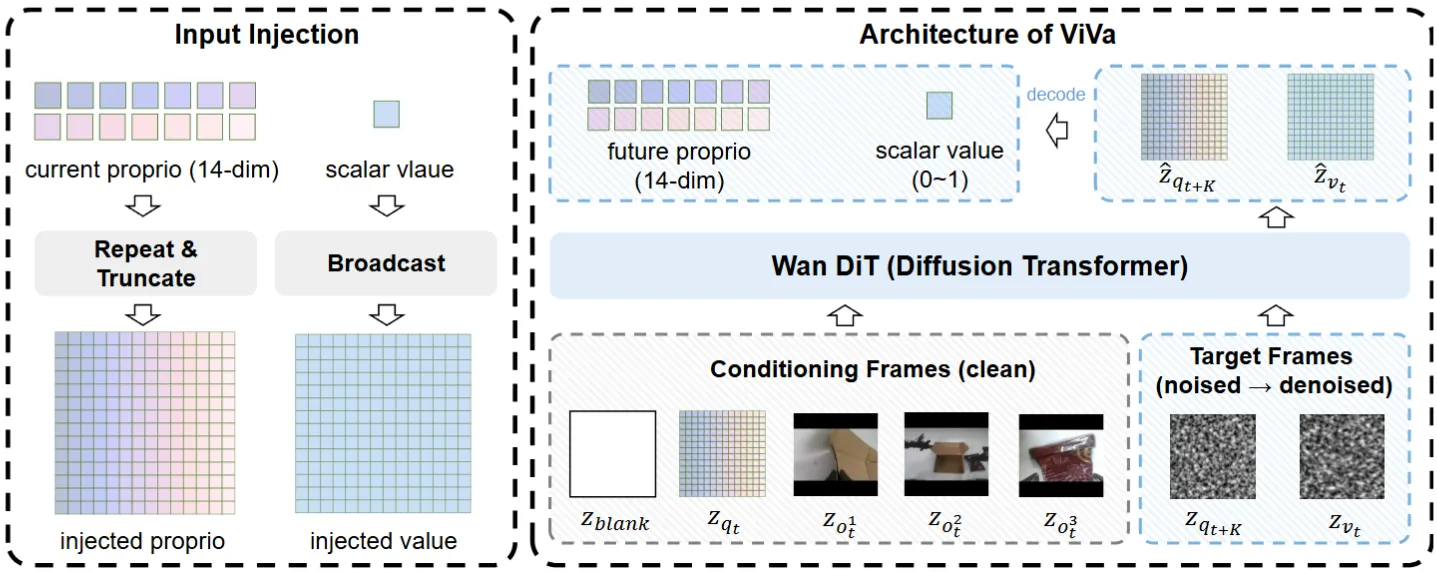
| ViVa | World Model Based DiT 预测 Action 以及 Value |
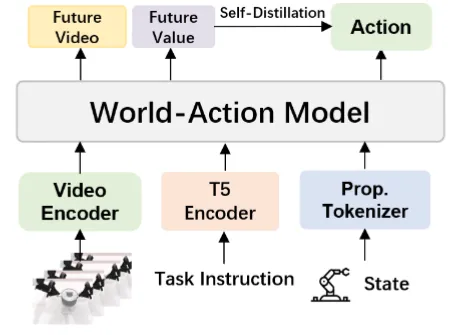
| AIM | World Model Based DiT 预测空间价值 Map,并且在后训练可以直接用 GRPO 自蒸馏 |
杂项#
除了以上的主要命题之外,具身依然包括很多其他的子问题,对于读者来说,阅读这部分的内容并非必须,但是在相关的话题下,或许可以提供一些有价值的参考。
有价值的 Study Paper#
除了对于模型架构以及训练范式的探索,一些对于模型能力以及训练的系统消融也是有价值的,它们与前文介绍的不同方案息息相关,相关结论总结在这里。值得一提,由于领域仍在发展,一些结论具有局限性,不同论文之间也有区别。
| 论文 | 方案 | 结论 |
|---|---|---|
| How Do VLAs Effectively Inherit from VLMs? | 通过 reach emoji 的任务来消融不同训练方案对于 VLM 本身泛化能力的影响 | VLM 的先验是有必要的;LoRA 或者 Frozen VLM 虽然可以提升 SR,但是容易欠拟合;一起训练的问题在于灾难性遗忘,因此 co-training 被验证是有效的。LAPA 类型的 Latent Token 相较于离散 Token 对于训练效果更好。非机器人相关的 VLM 数据也可以 benefit VLA。 |
| Do World Action Models Generalize Better than VLAs? A Robustness Study | 通过使用 LIBERO 以及 RoboTwin 的扰动版本,测试不同的 WAM 以及 VLA,并且比较二者的差距 | WAM 普遍对于扰动更鲁棒,VLA 想追平需要更大、更杂的 robotic 数据;混合 video prior 的 hybrid 方案落在中间 |
| Multi-Camera View Scaling for Data-Efficient Robot Imitation Learning | 从提升相机视角数量的角度来 Scaling 并且训练模型 | 不同视角一起训练可以使得模型的注意力 focus 在目标物体上,并且具有更强的性能以及视角鲁棒性 |
| StarVLA- | 在全部流行的 Benchmark 上系统 Study 不同的模型训练 setting | 基于 StarVLA 这个很好的 Infra,消融了模型结构、预训练、一些 trick、Batch size、Model size 在内的大量内容在单一 Benchmark 以及跨本体多 Benchmark 混合训练的现象,非常值得一读 |
| FineVLA | 对比使用细粒度指令与正常指令 | 即使对于目标级任务,细粒度指令仍然可以提升性能 |
| LA4VLA | 在预训练阶段加入细粒度的 Language-Action 数据并在下游 Benchmark 验证预训练效果 | 加入 LA 对于 VLA 预训练有好处,可以促进 VLA 下游表现 |
VLA Infra#
在 VLA 为时尚早的发展中,因为模型的体量较小,但是同时数据种类也有所区别,面临着不一样的模型生态,也存在不同的社区以及工作,尝试搭建 VLA Infar,并且发表他们的 Tech report。
| 论文 | 主要贡献 |
|---|---|
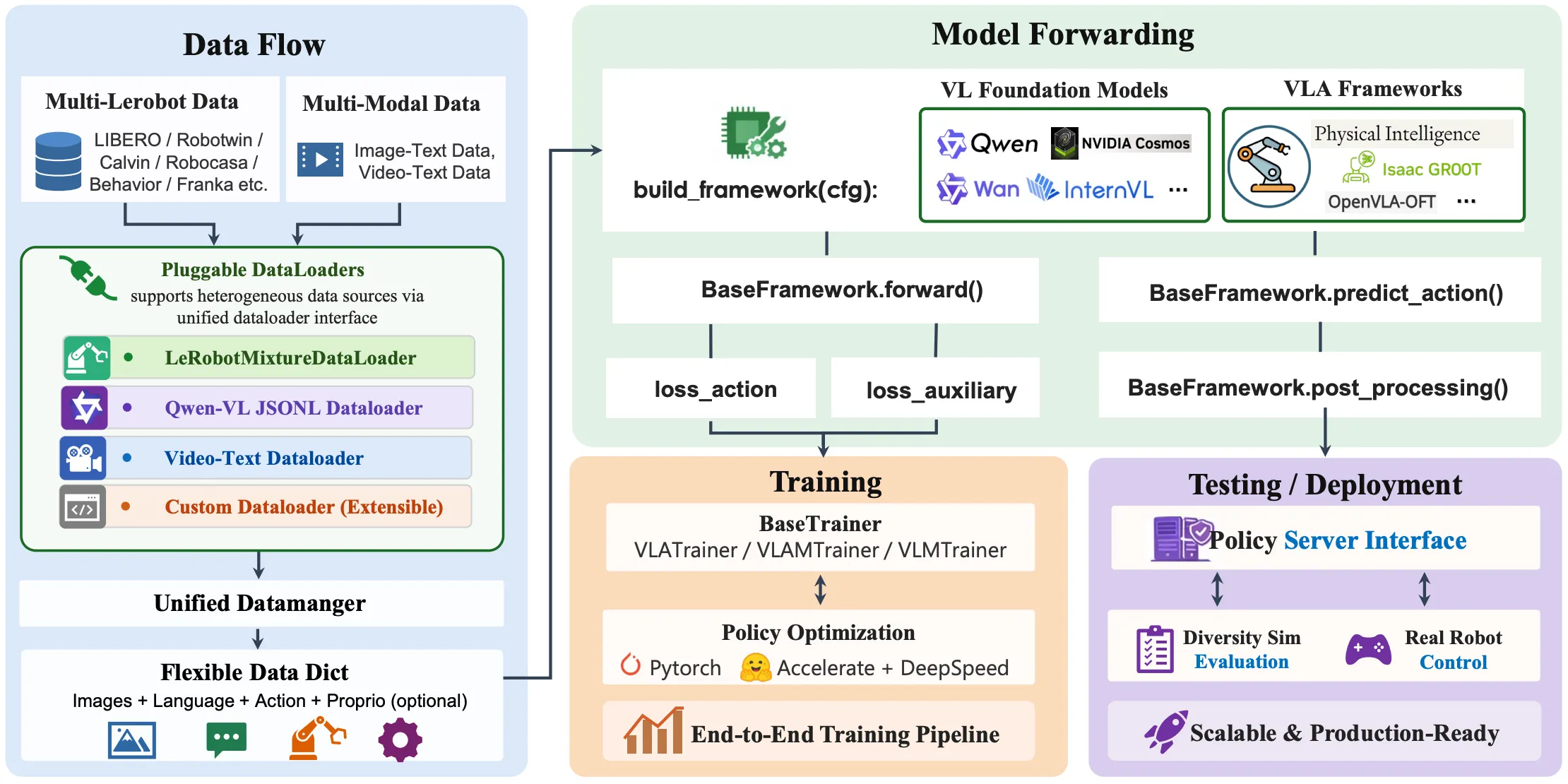
| StarVLA | VLA 模型训练框架,训练测试一体,支持很多内容,目前算是最流行的框架 |
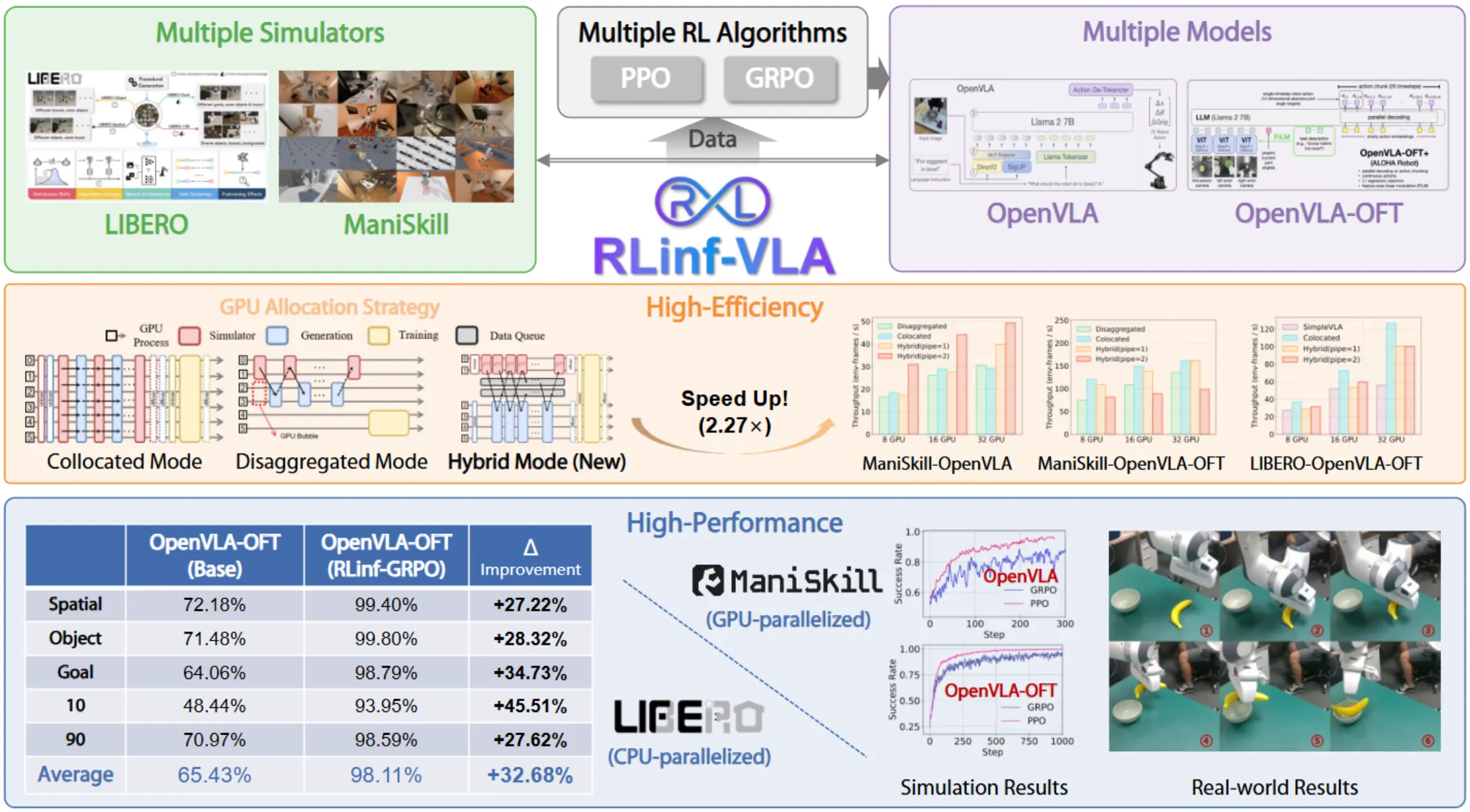
| RLinf-VLA | RLinf RL 框架 |
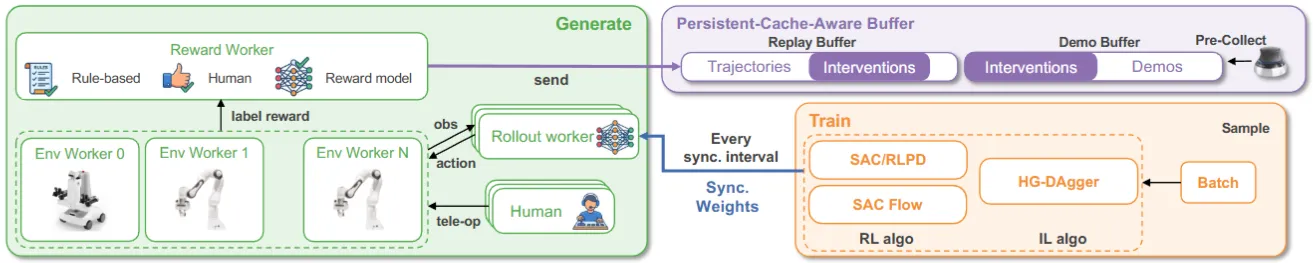
| RLinf-USER | RLinf 的真机 RL 基建 |
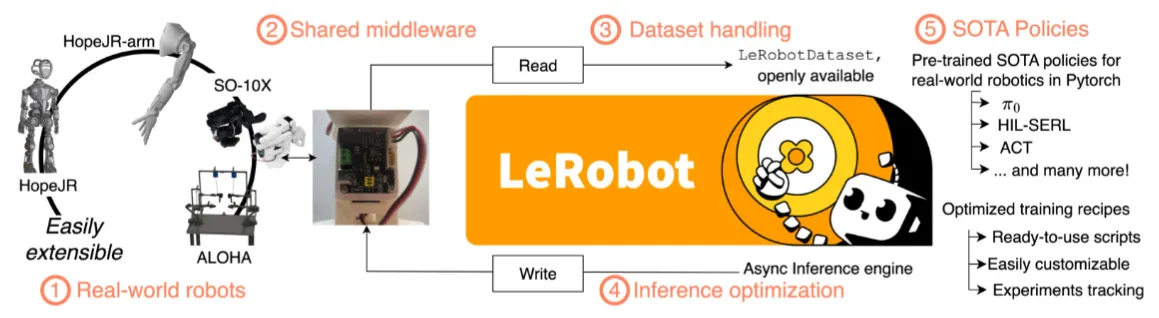
| LeRobot | HuggingFace LeRobot 技术报告 |
| LWD | SII + Finch AgiBot 出品的离线 + 在线强化学习框架 |
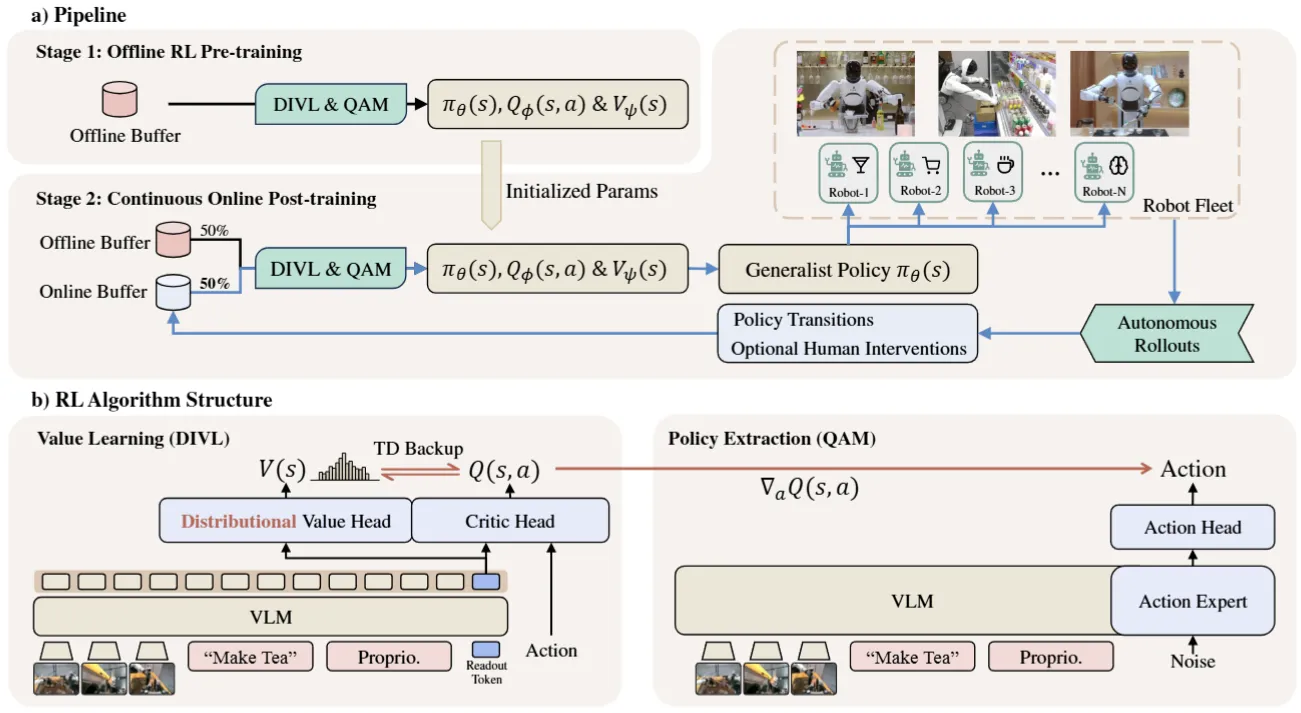
触觉/力控模型#
一些模型在使用 VLA Data 之外,也尝试引入更加 Rich Annotation 的数据,其中比较在机器人学中热门且被认为有效的就是使用触觉数据,在这方面也有做出相当可观的探索。
| 论文 | 主要贡献 |
|---|---|
| FD-VLA | 在训练时从图像 + 状态蒸馏出 force token,可无力传感器部署 |
| TacVLA | 紧凑触觉 token + 接触感知 gating 的 PaliGemma VLA |
| ForceVLA2 | Cross-Scale MoE + 力 prompt 引导任务分解的 hybrid 力位 VLA |
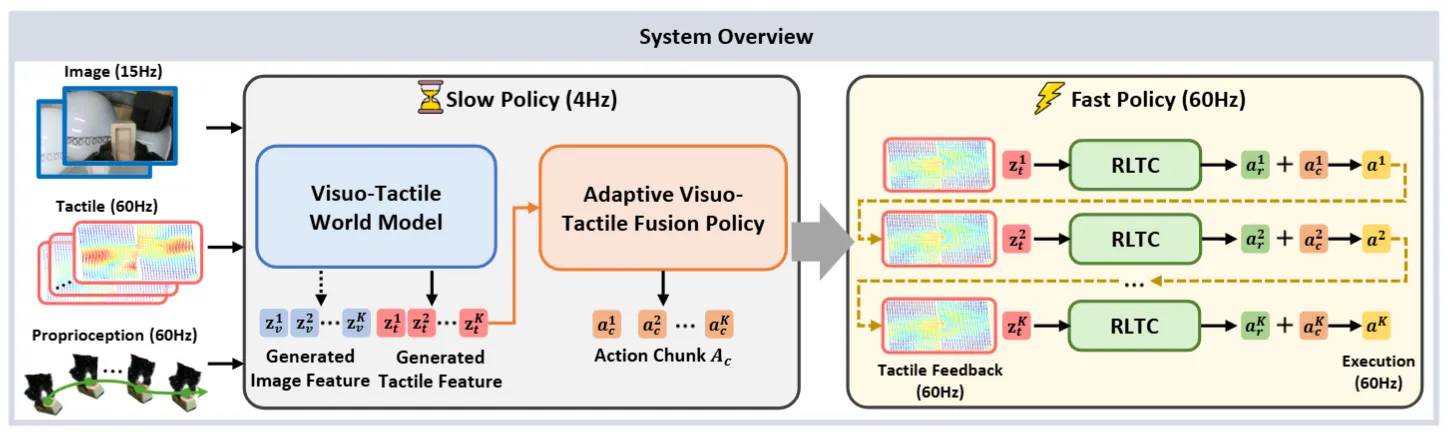
| OmniVTA | 训练 Tac Encoder,于慢系统 WM 同时预测 Visual 和 Tac,接 DiT,下游小模型快速纠正动作 |
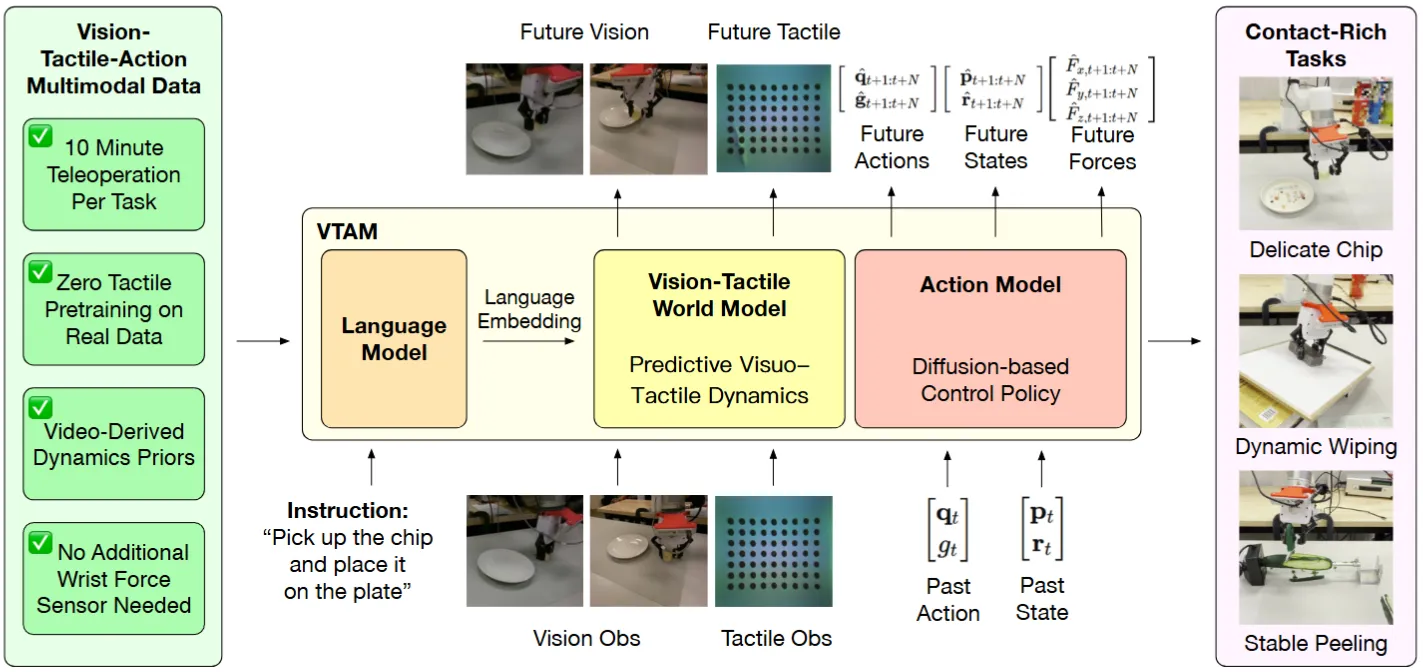
| VTAM | 使用 LM 输出 Embedding 之后 WM 预测 Visual + Tactile 接 Actor |
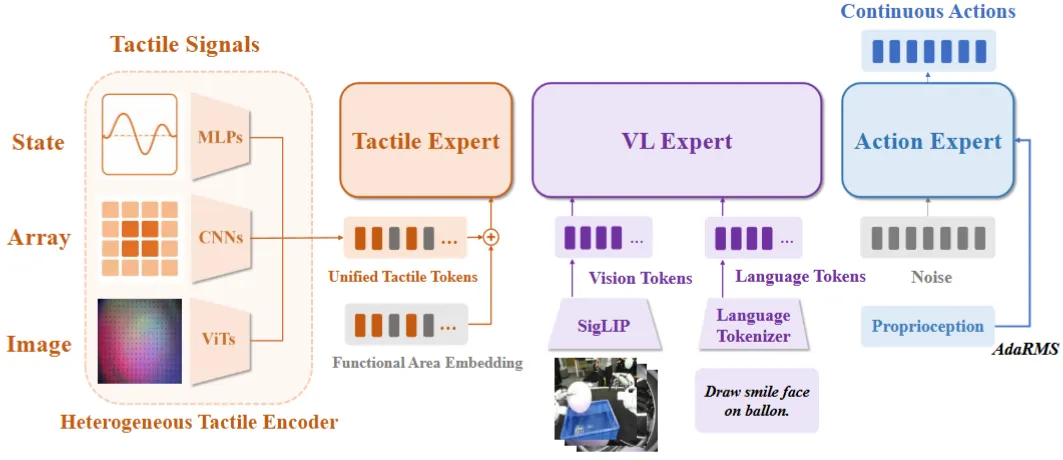
| FTP-1 | Tac Expert + VLM + Actor 的 MoT 预训练触觉输入模型,以及触觉数据集 |
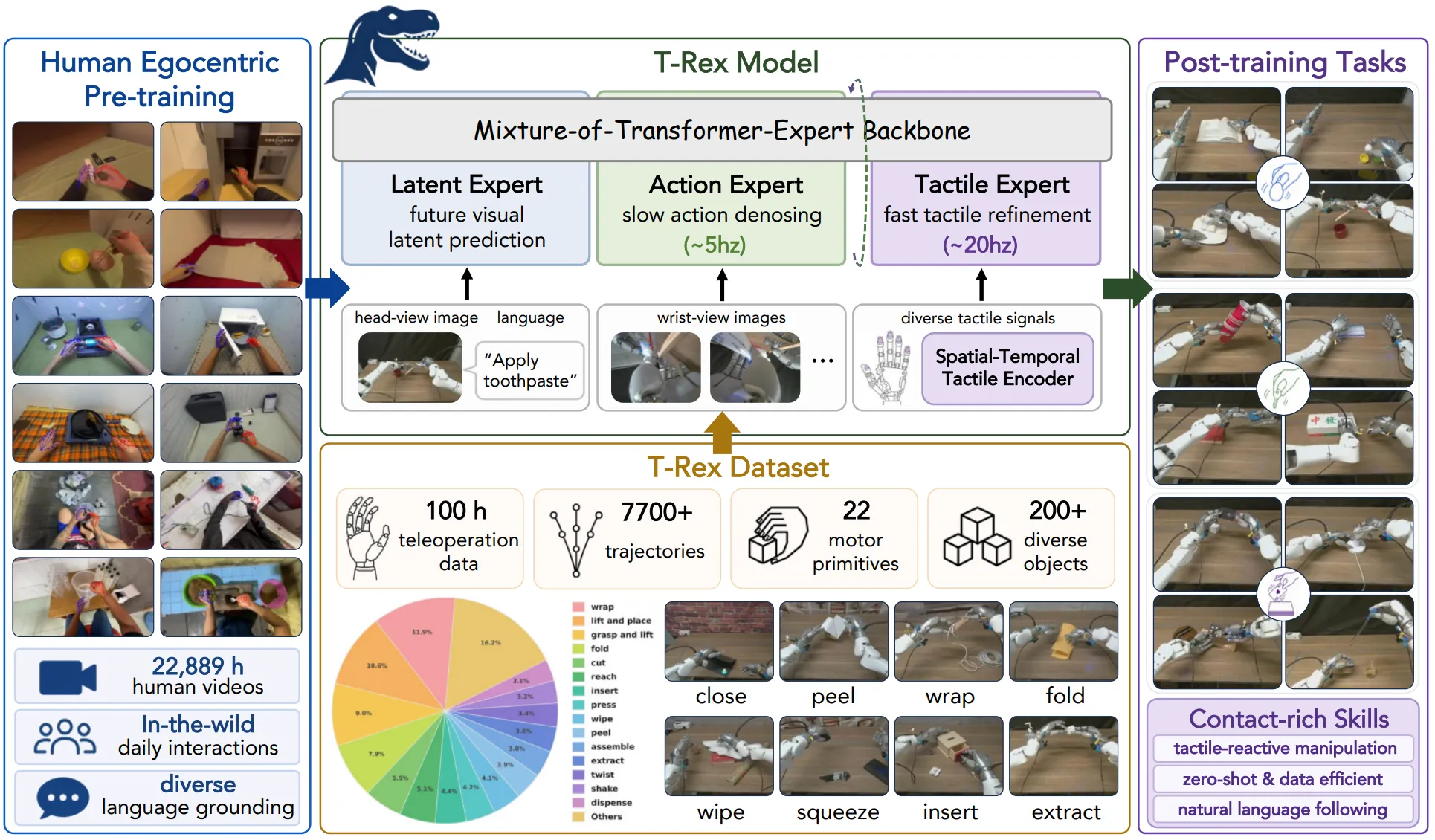
| T-Rex | Latent WM Expert + Slow Actor + Fast Tac Expert 的 MoT 预训练触觉输入模型,以及触觉数据集 |
| TouchWorld | WM 预测 Goal Image + Tactile 的 System 2 + VLA System 1 + Tactile System 0 |
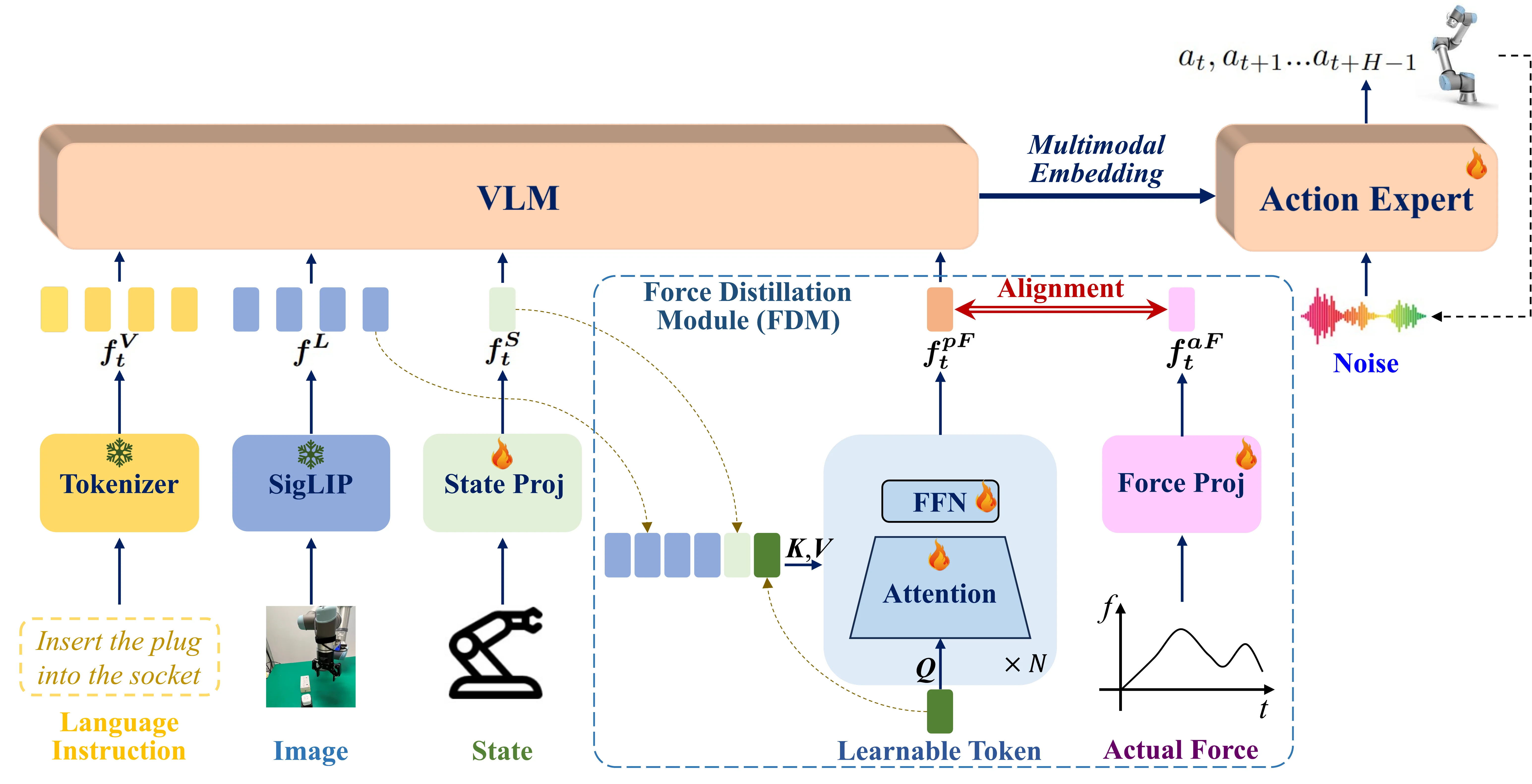
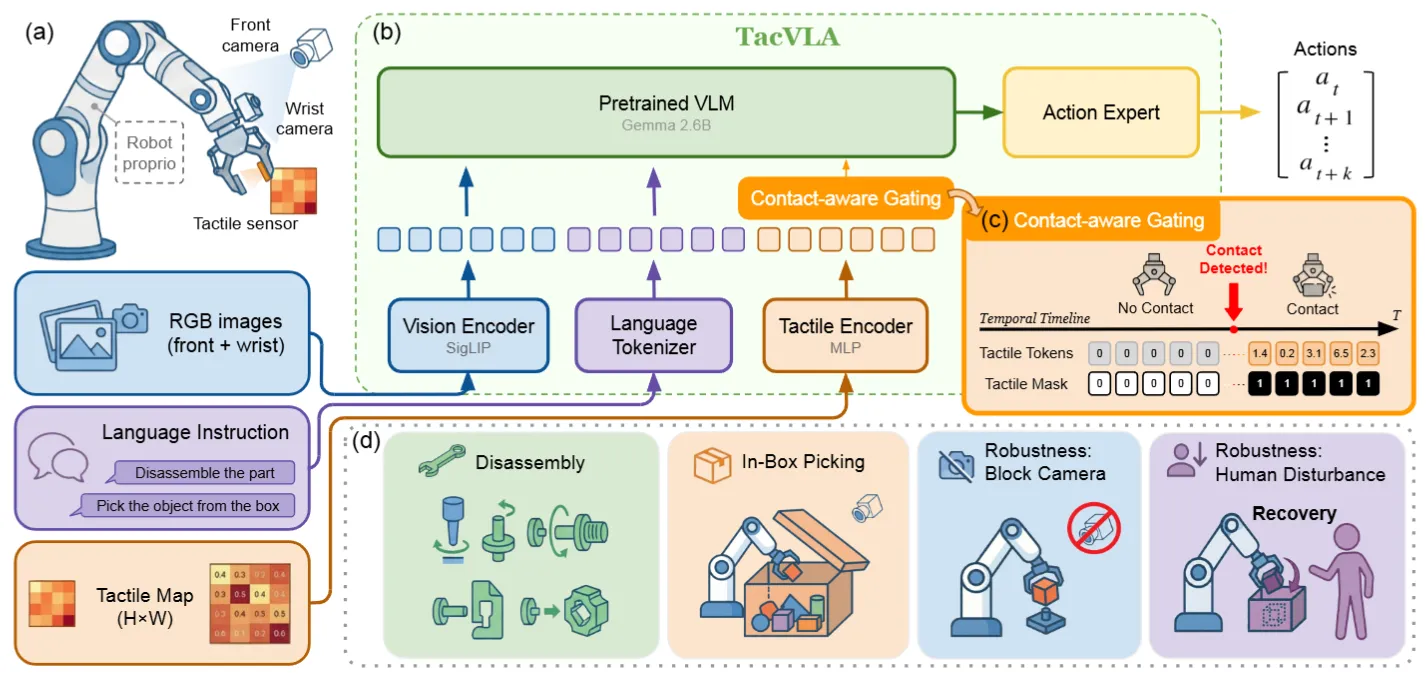
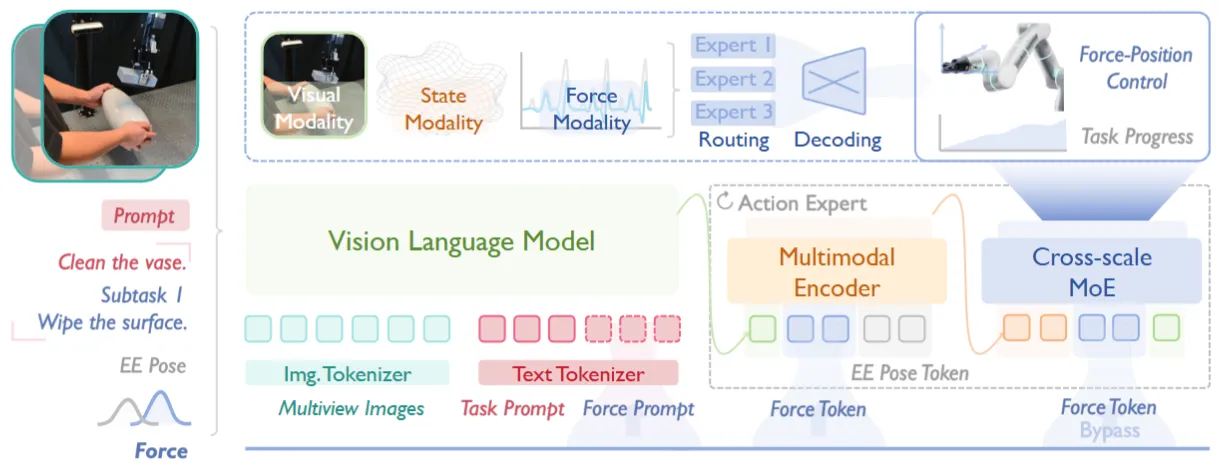
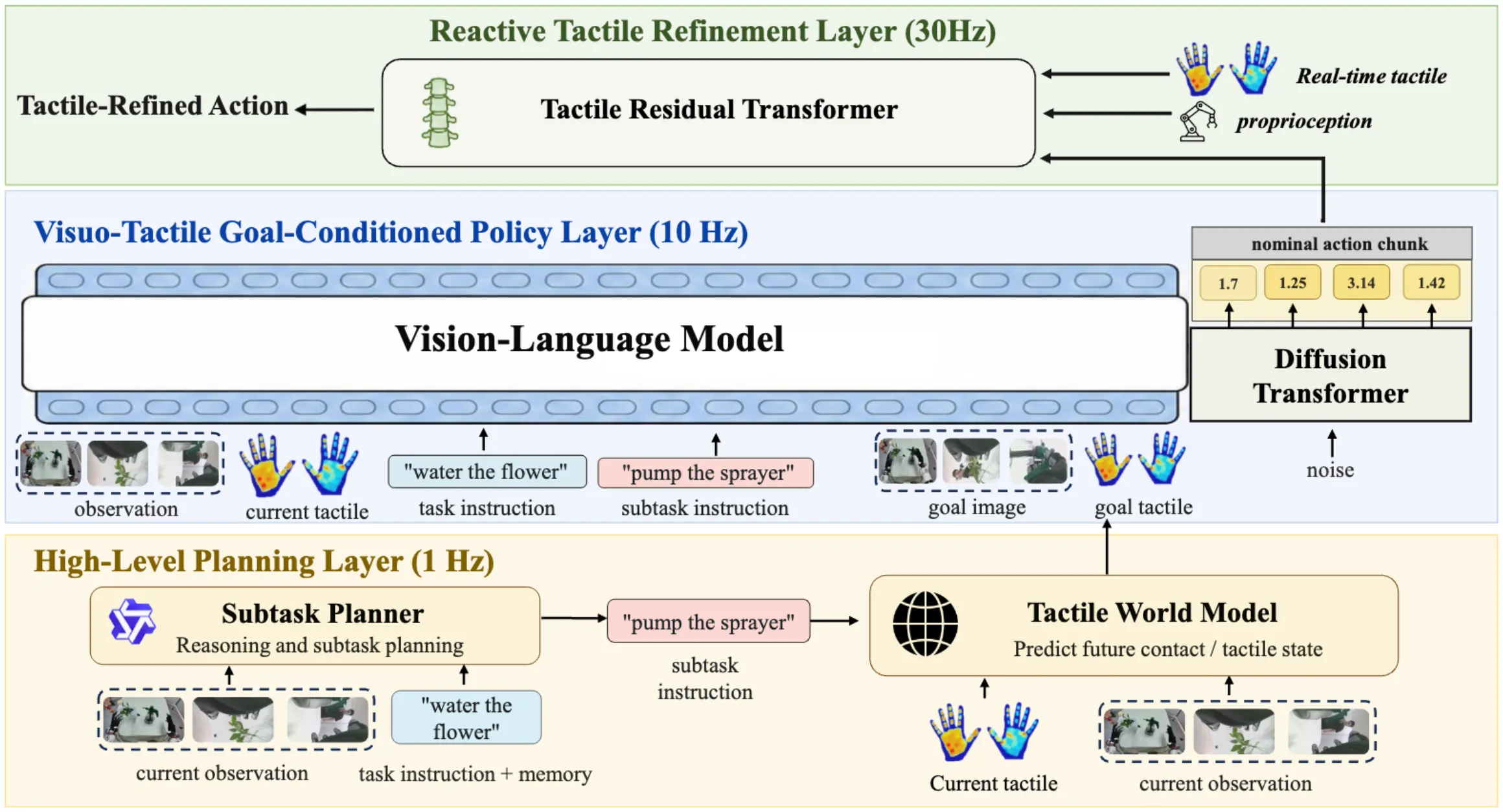
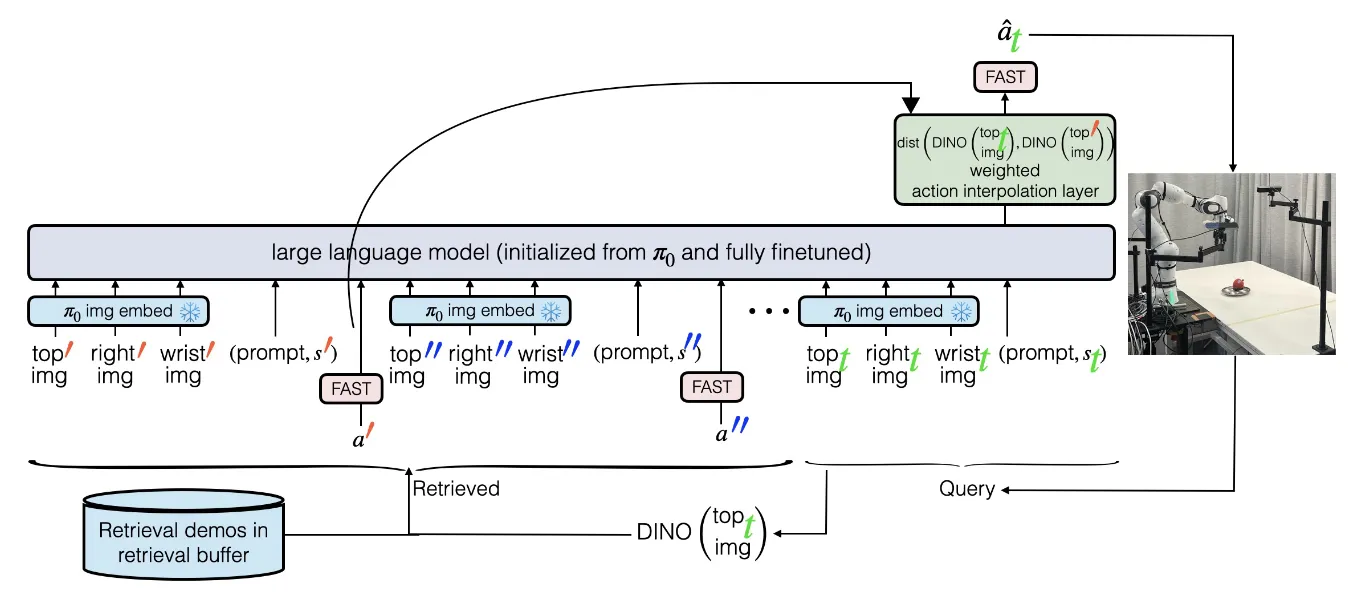
In-context Learning#
In-context Learning 是 LLM 中一个非常重要的能力,在 VLA 领域中,是否存在 In-context Learning 的能力也是一个非常重要的问题,如果真正存在 In-context 能力,那么意味着存在一个通用的 one-shot model,这同样是令人振奋的。
| 论文 | 主要贡献 |
|---|---|
| RICL | 使用 DINO 相似度对于 context action 和 VLA output 插值,较为原始的探讨 |
空间表征#
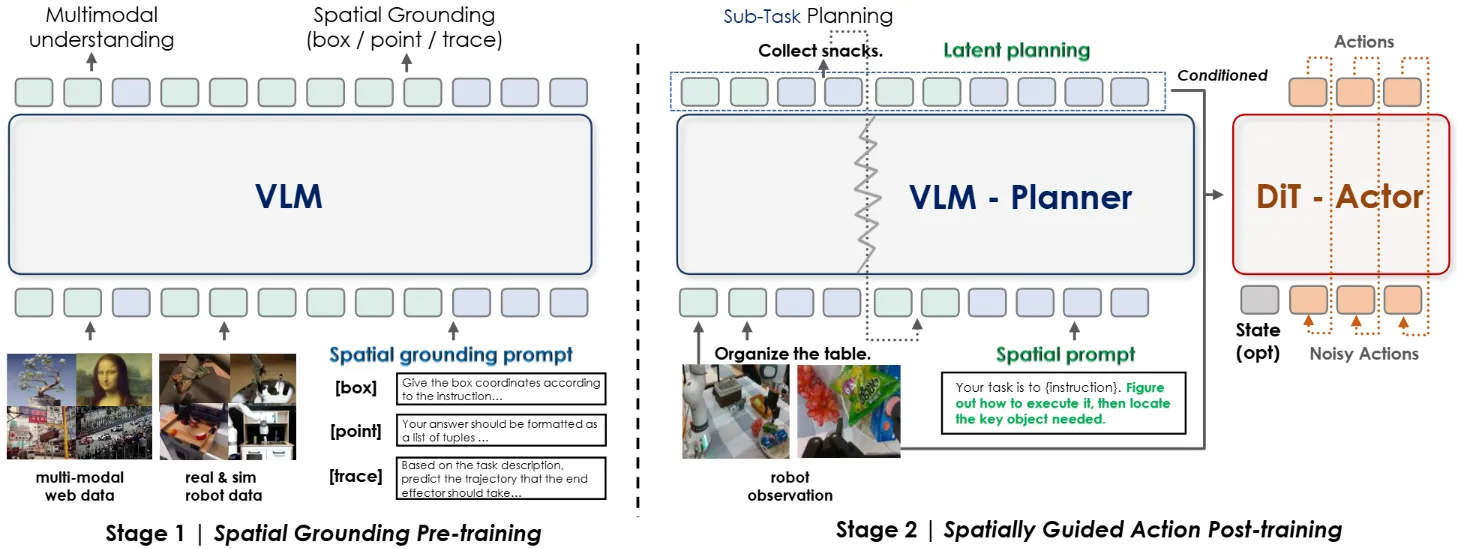
一些论文讨论如何将空间表征加入到 VLA 里面,这对于空间智能这一具身智能的姊妹命题是一种阐释:
| 论文 | 主要贡献 |
|---|---|
| FiS-VLA | 通过在 Condition Concat 引入 3D Token |
| SpatialVLA | 使用 semantic embedding 以及 depth 来投影得到 Spatial Token |
| Evo-0 | Fusion image encoder 以及 VGGT |
| 使用 Trace 作为表征训练 VLM + Trace Expert,之后 VLM + Trace Expert 用 GR00t-like 接到 Actor 上的类 WM 模型 |
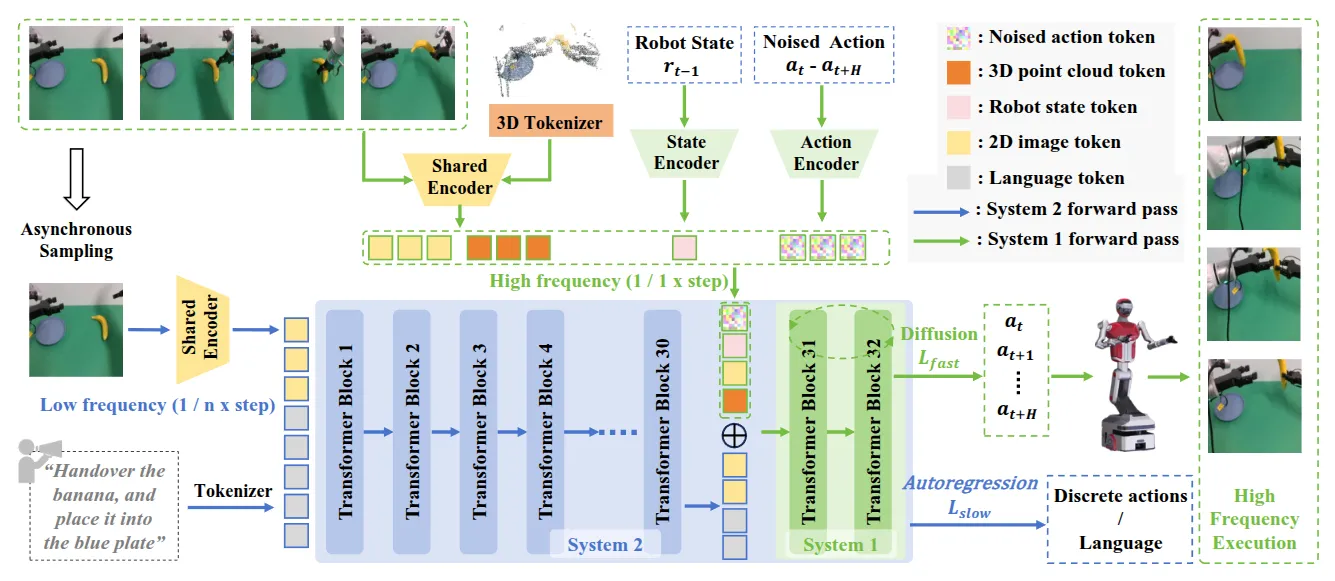
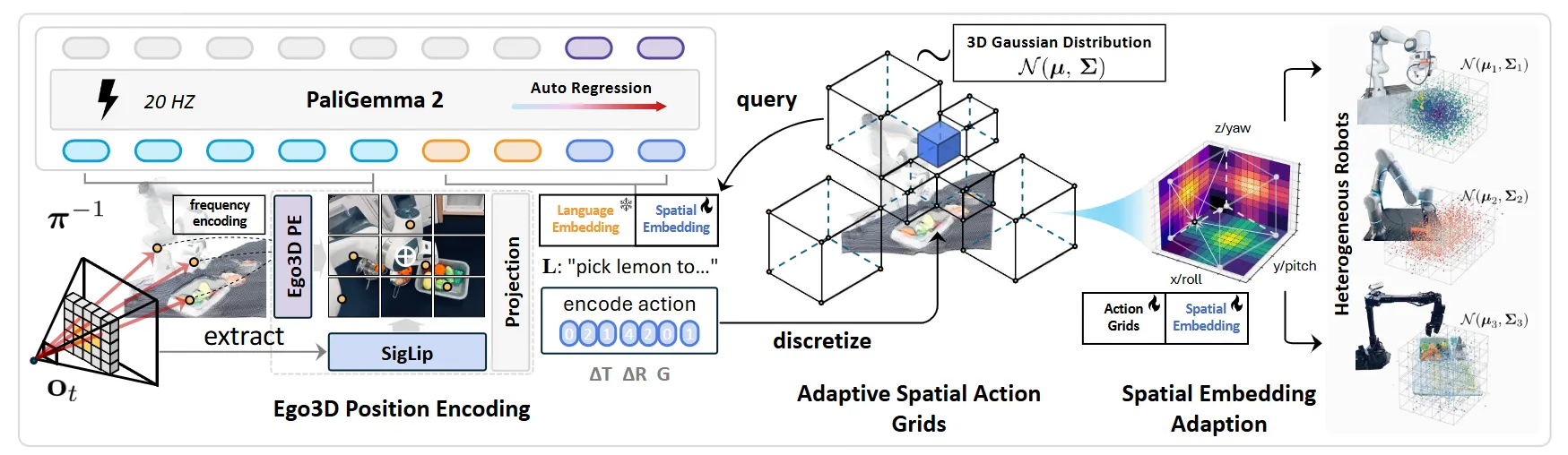
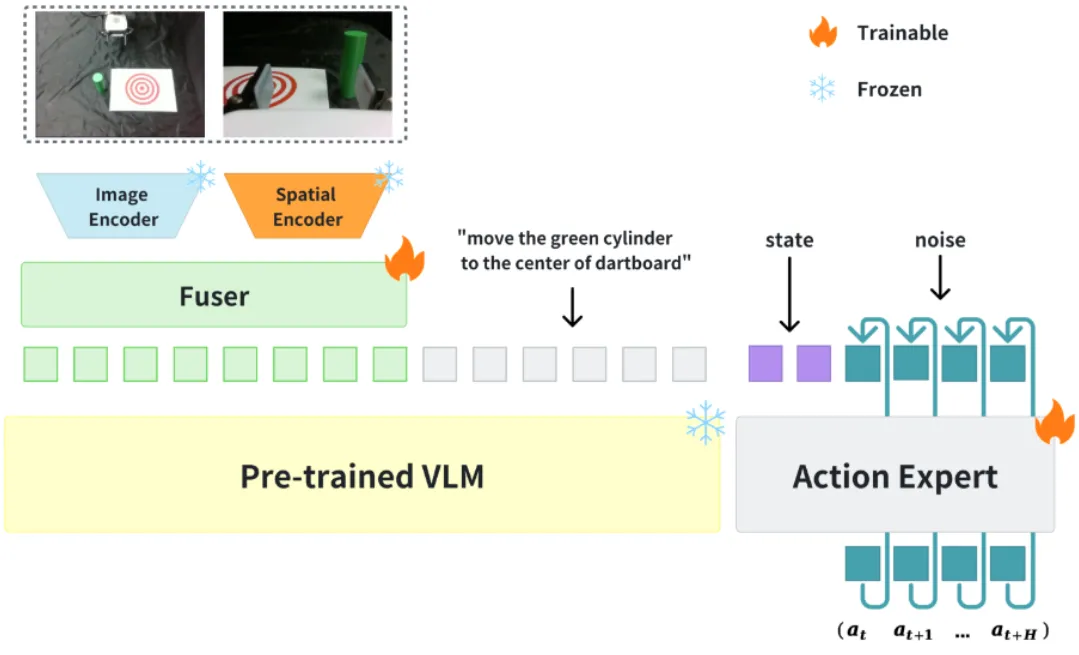
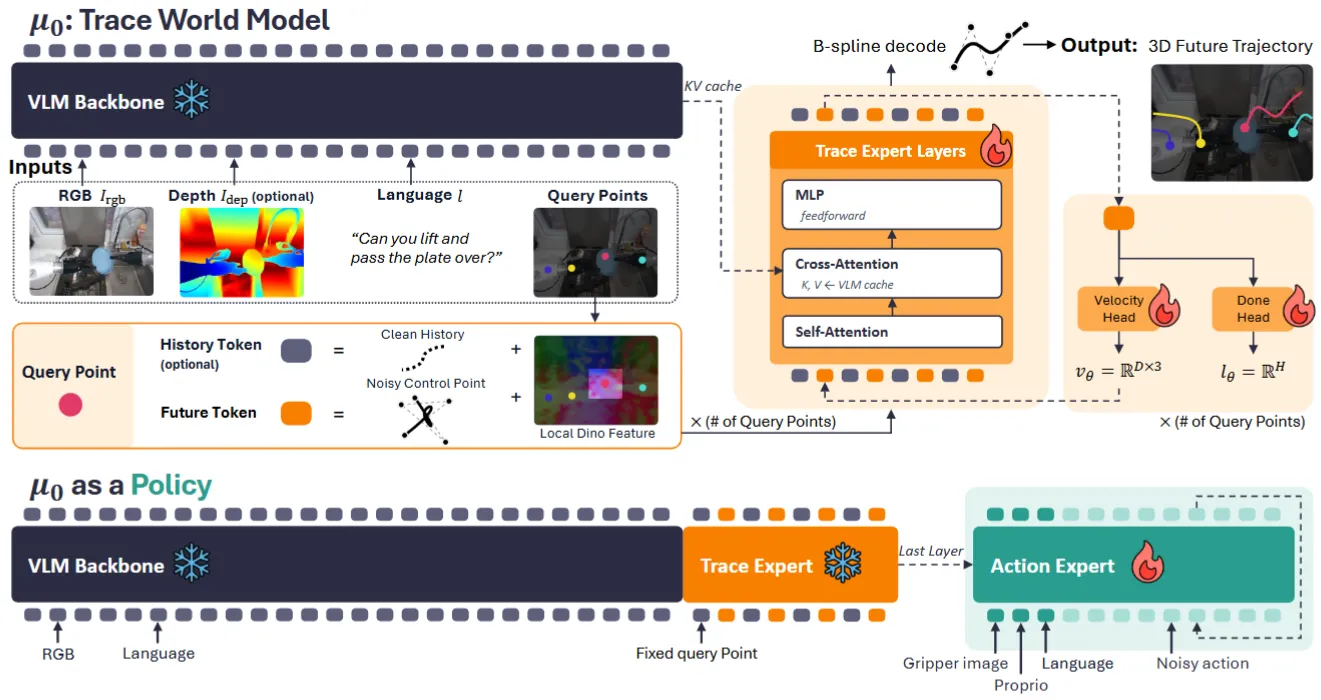
Visual Prompt#
一些工作认为对于 VLA 来说,在图片上标注一些信息,可以帮助模型获得更好的性能,这些信息即 Visual Prompt:
| 论文 | 主要贡献 |
|---|---|
| TraceVLA | 在图片上标注历史动作轨迹 |
| Spatial Traces | 在深度图上标注历史动作轨迹,即“时空”轨迹 |
| VP-VLA | 把目标物体 / 终点 render 成 visual prompt 作为 Obs 输入 |
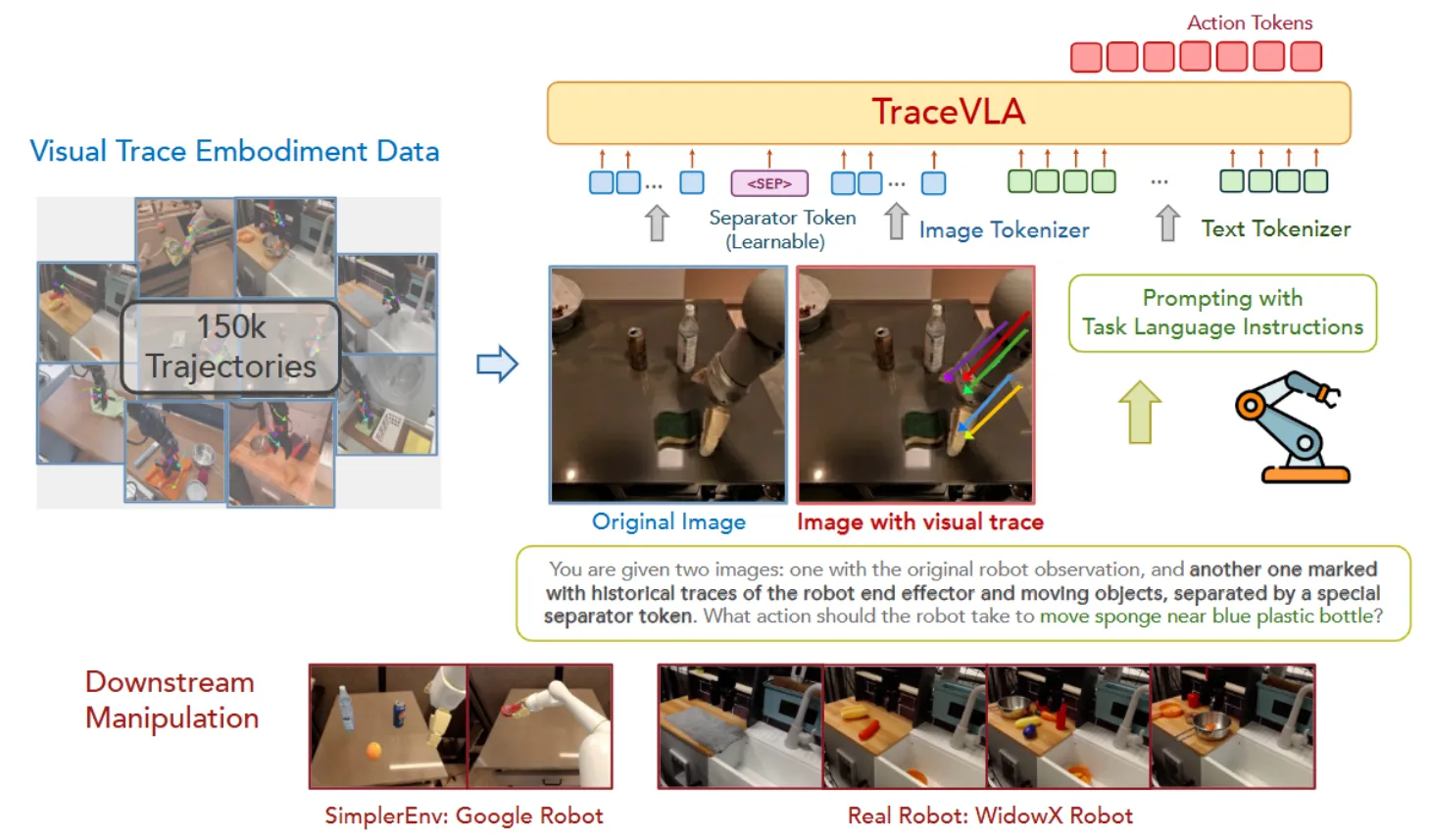
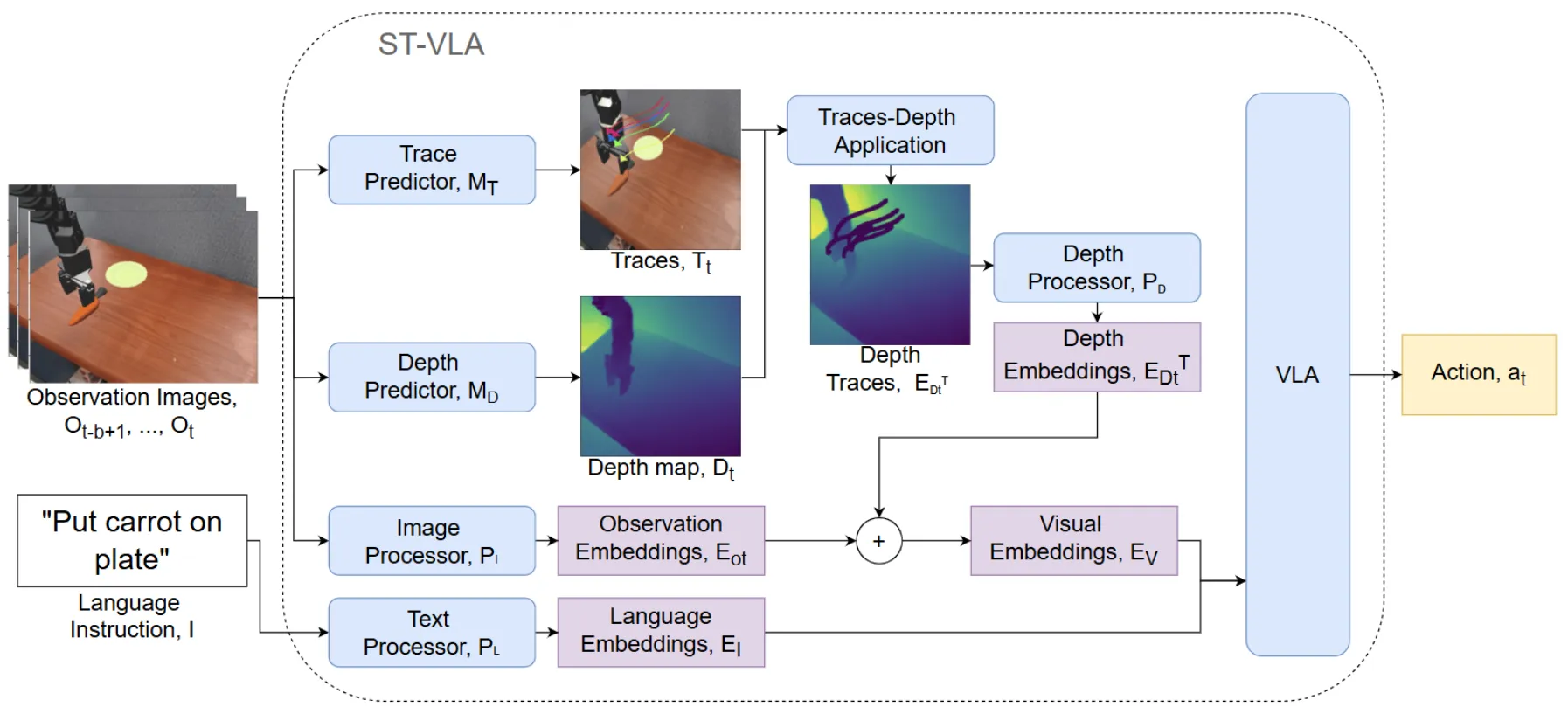
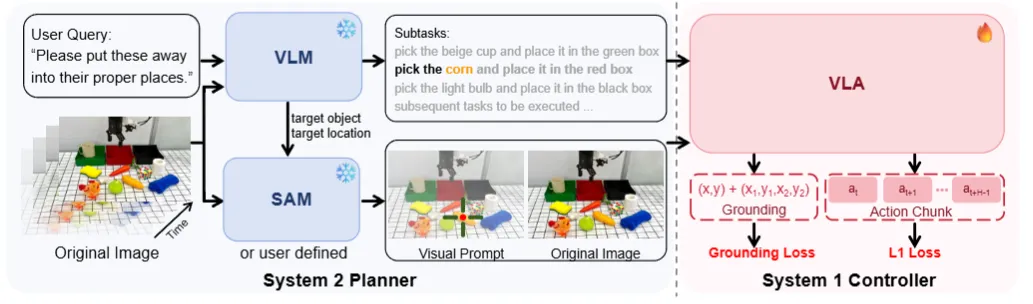
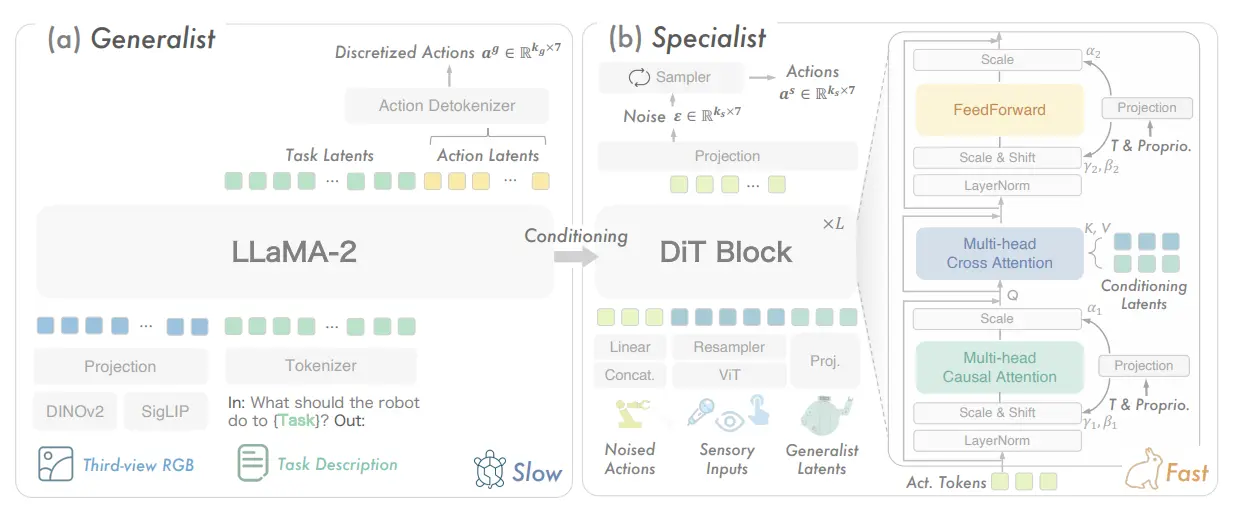
快慢系统#
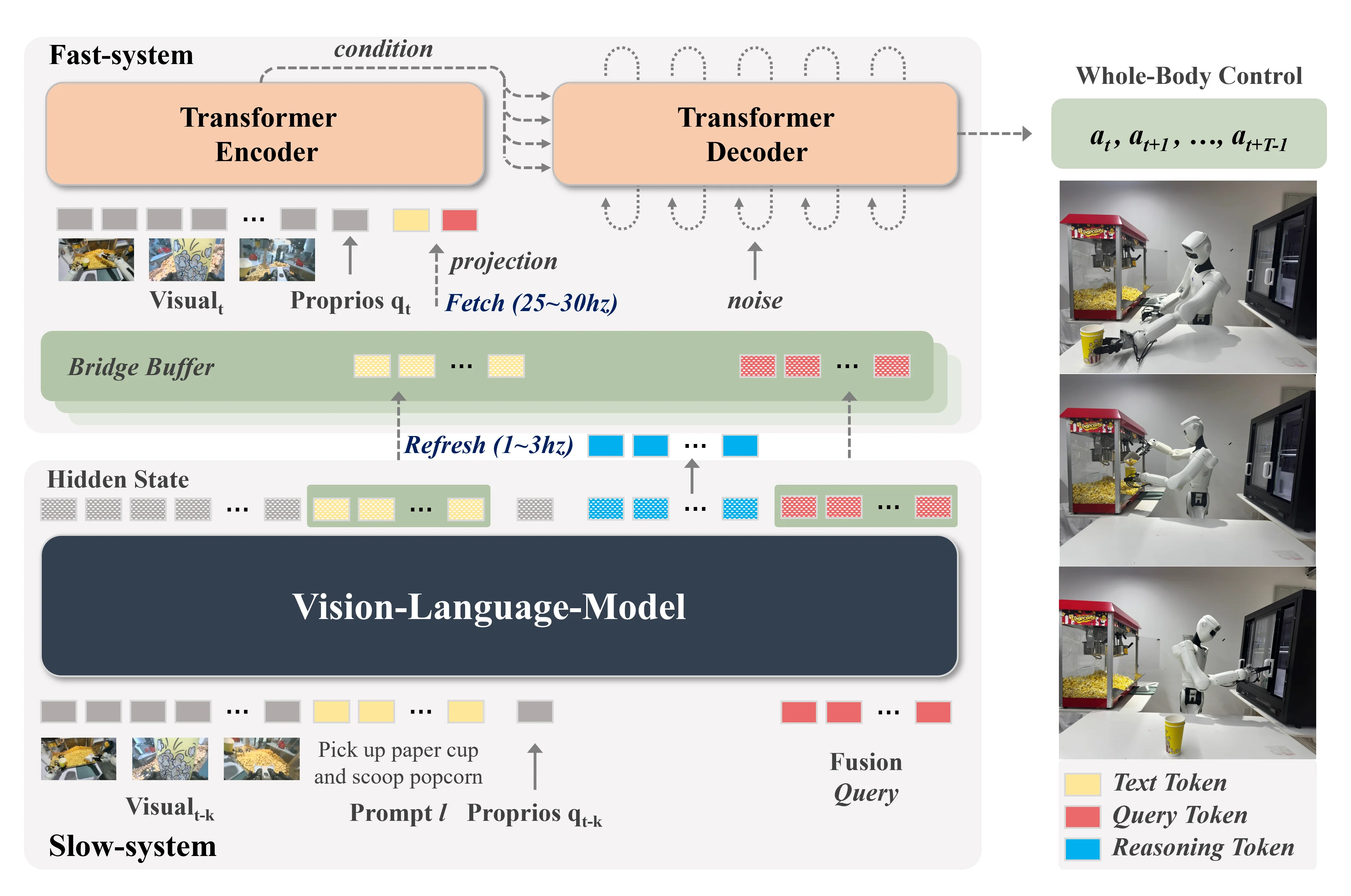
构建一个快慢系统来提高端侧的运行效率也是具身智能比较关心的命题,因为这样可以增加模型的灵活度,进一步提高模型的成功率,上述主要篇幅中其实如 RoboDual 就是快慢系统,同时如 以及 GR00t 等模型均因为包含两个桥接的组件,因此可以以不同的频率进行更新,从而形成快慢系统。除此之外还有一些其他工作:
| 论文 | 主要贡献 |
|---|---|
| Hume | 慢系统生成候选动作,快系统 Corse to Fine |
| Helix | 快慢系统的 Demo,无 report |
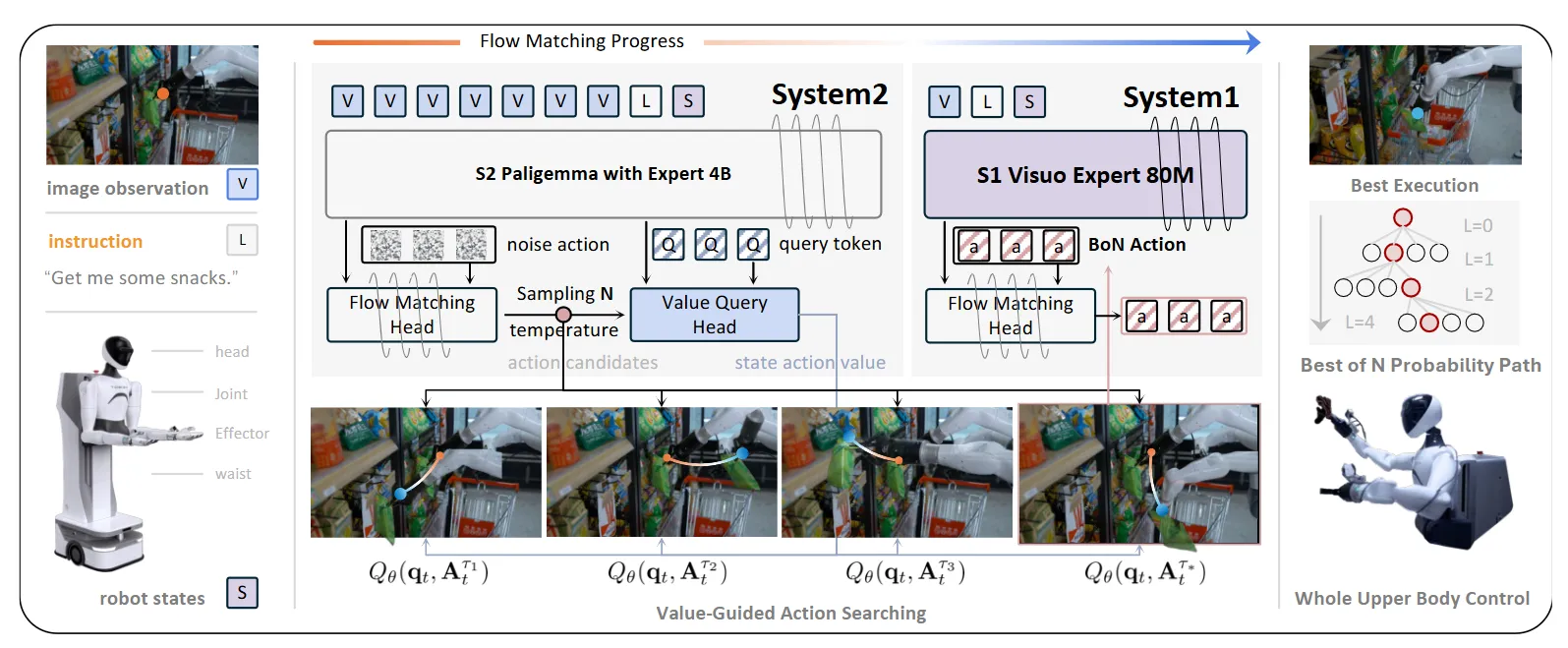
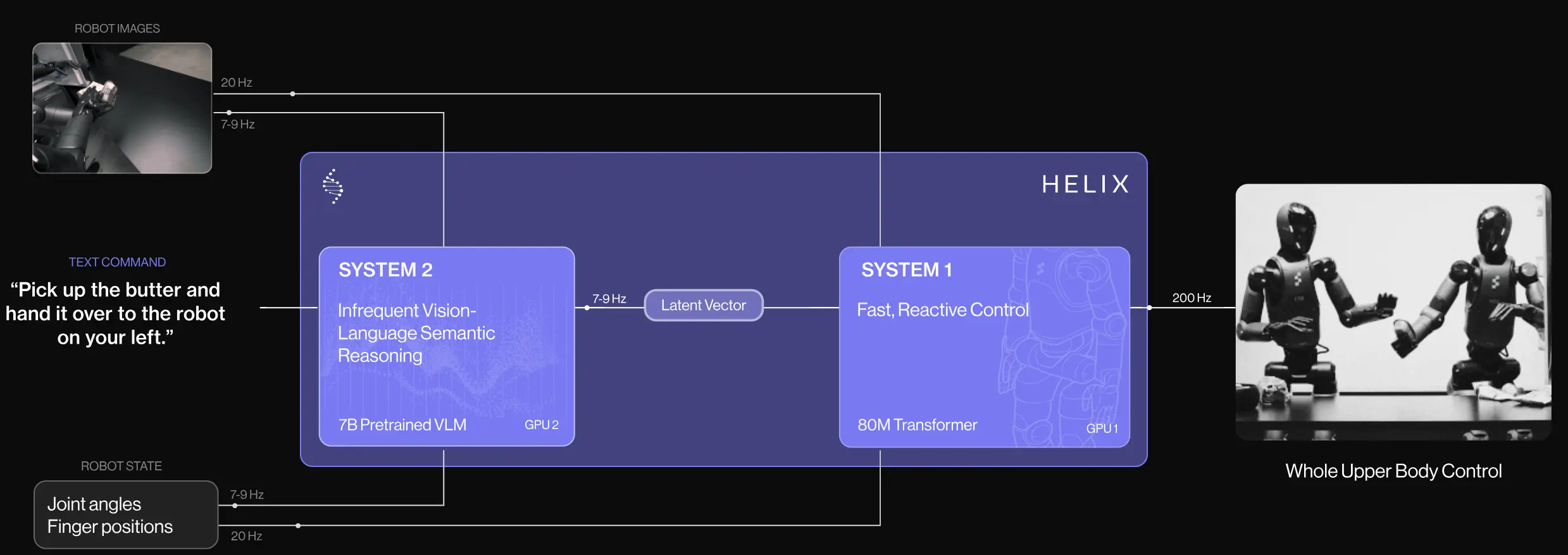
初创们的技术报告#
同时还有一些初创公司、实验室或者正常企业的 VLA 技术报告,这些内容在当时可能较为同质,没有代表性,因此单独列出。在研究预训练以及数据组合的时候或许具有一些参考价值:
| 论文 | 主要贡献 |
|---|---|
| GR-3 | Seed Robotics 出品的 Qwen + Pi |
| G0 | Galaxea 出品的 Qwen 2.5 VL + Pi |
| EO-1 | Interleave 预测 Language & Action 的 co-training VQA 模型 |
| GigaBrain-0 | GigaAI 出品的使用 World Model 合成的数据一起训练,KI Pi |
| iFlyBot-VLA | 讯飞出品的 Latent Action + FAST + MoT Actor |
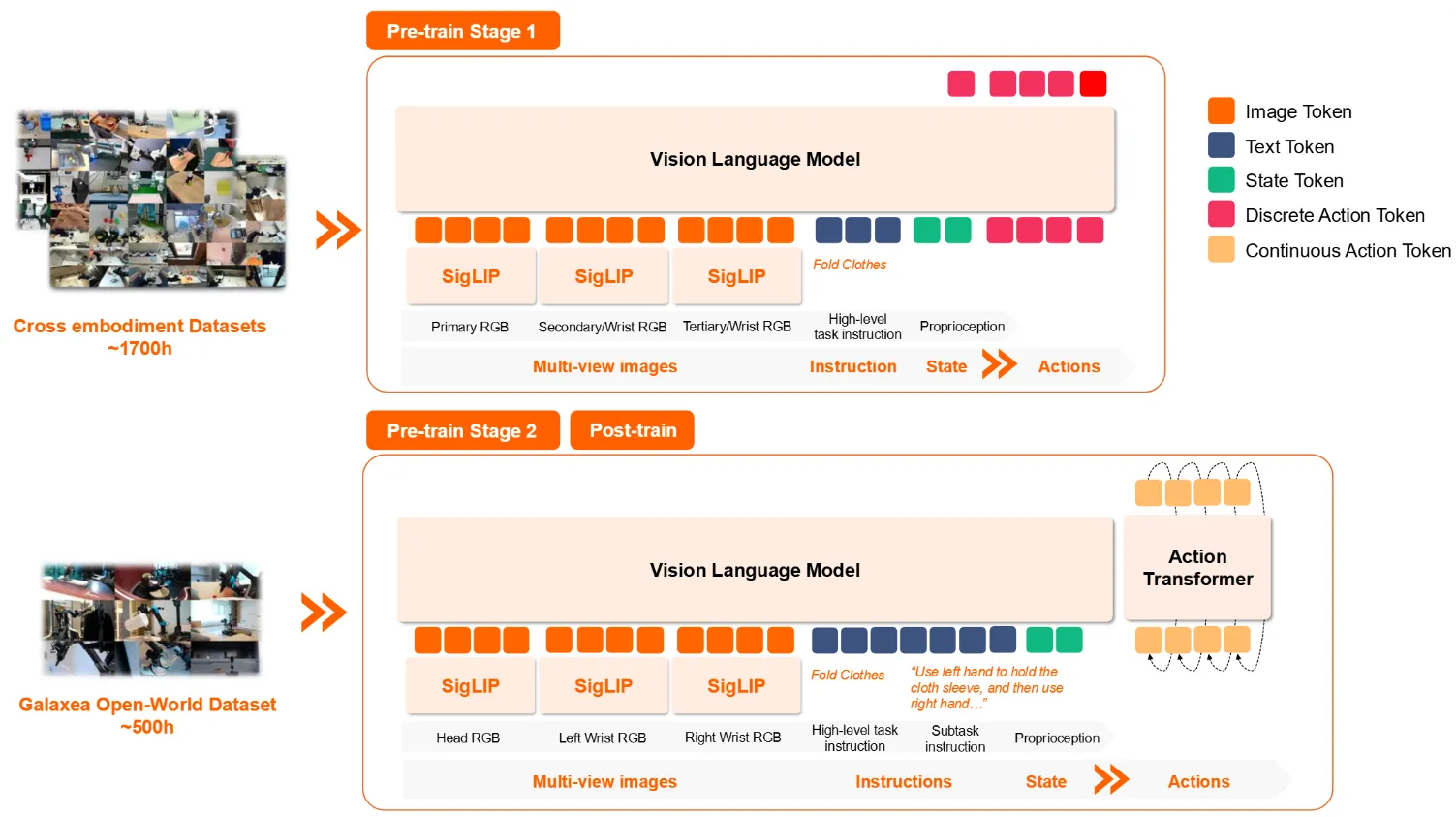
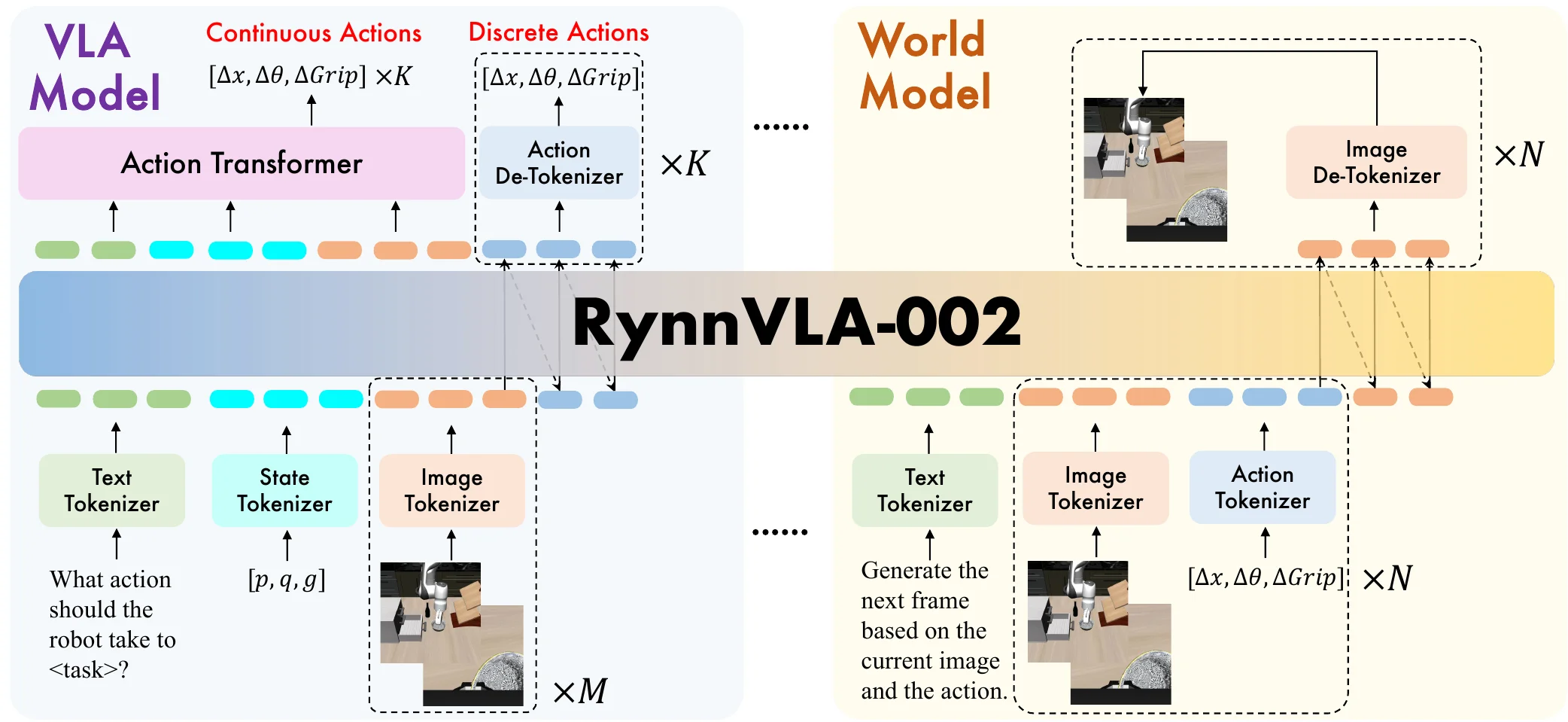
| RynnVLA-002 | 达摩院出品的 UMM-based 同时预测 Future + 离散动作 + DiT Actor |
| DuoCore-FS | Astribot 出品的 VLM + Transformer Fusion + Actor |
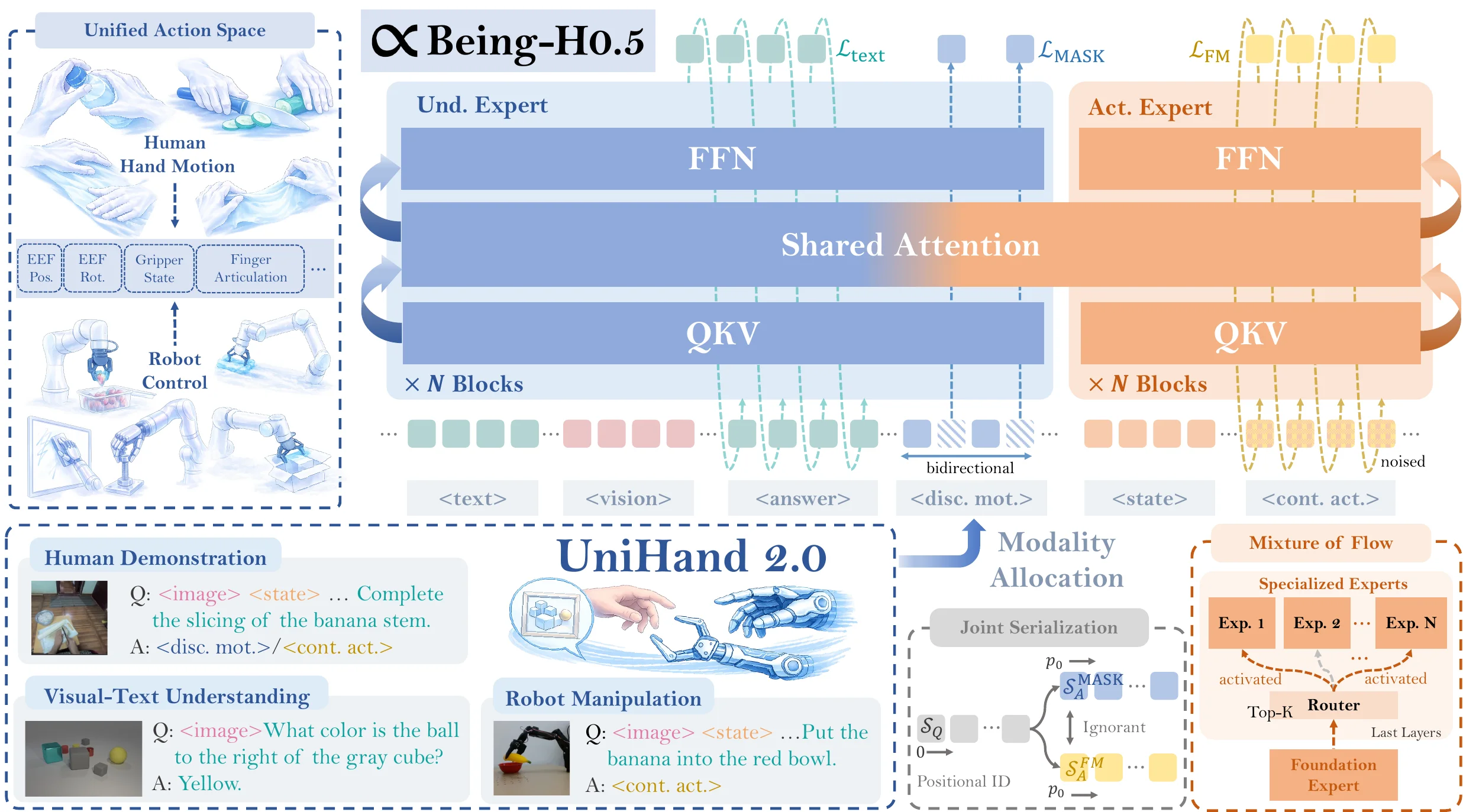
| Being-H0.5 | BeingBeyond 出品的使用 United Action Space 来混训不同本体数据 + VQA 的 Pi |
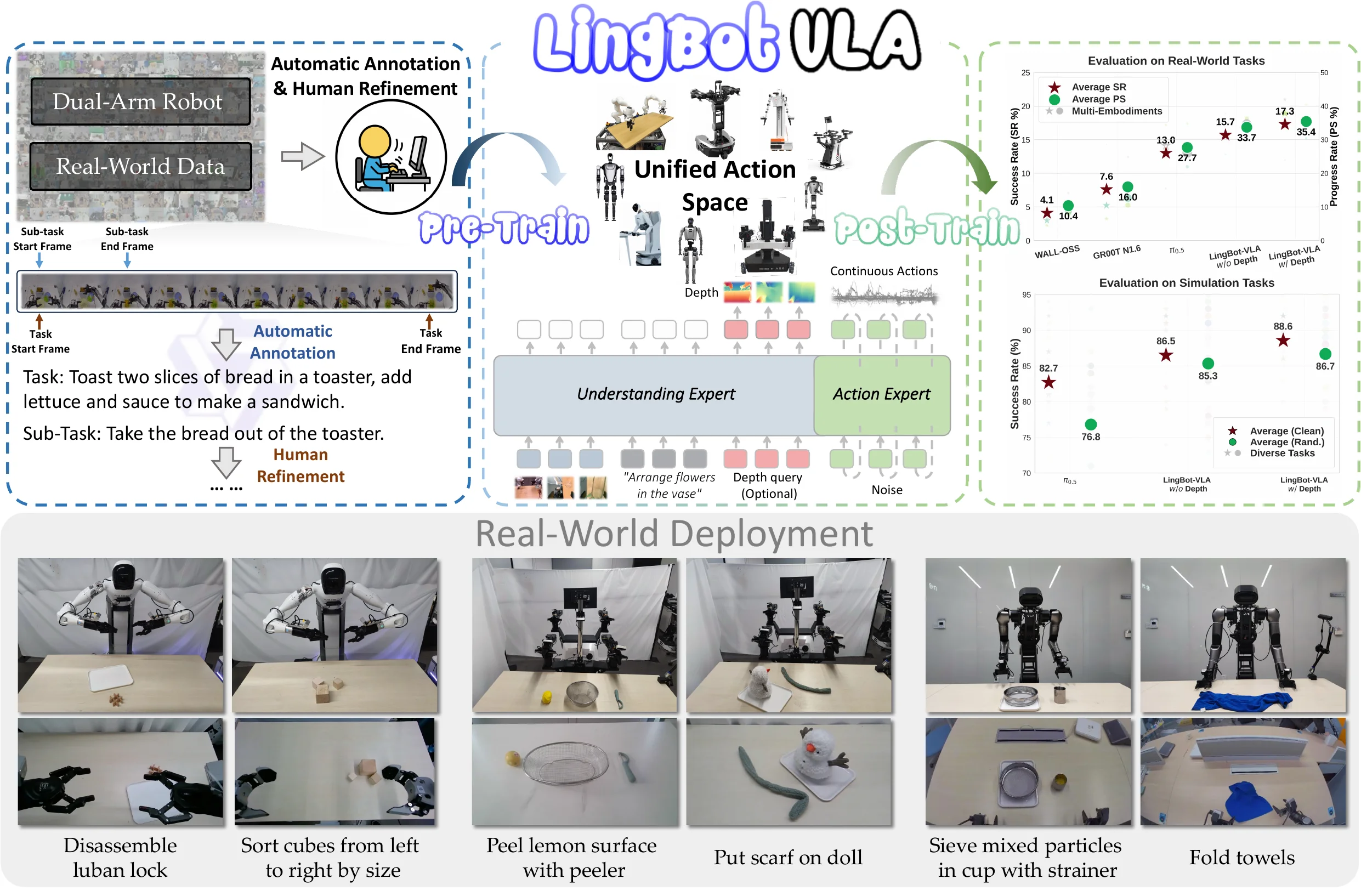
| LingBot-VLA | LingBot 出品的使用自研 LingBot-Depth 添加深度表征,优化 Infra 的跨不同本体 Pi |
| Green-VLA | Sber Robotics Team 出品的 VLM + VLA + RL 全栈的 VLA report,做法中规中矩 |
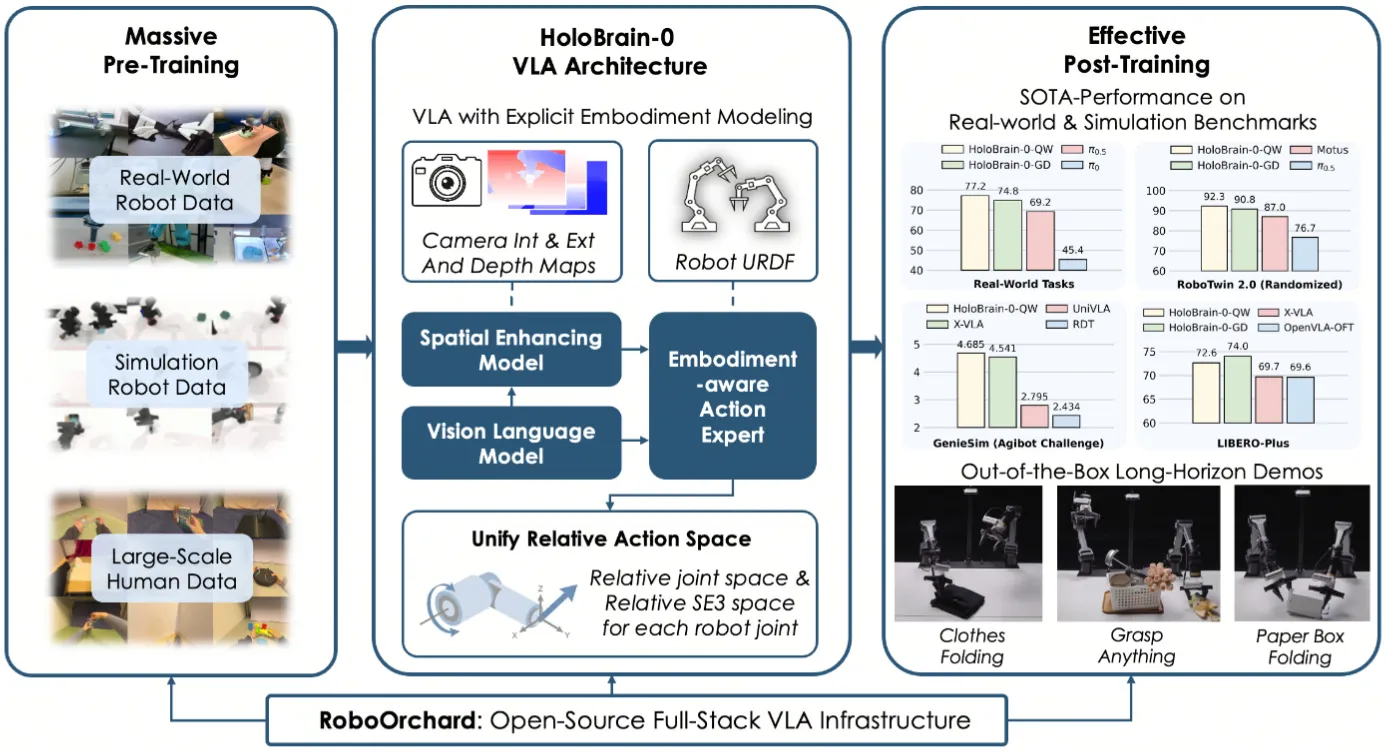
| HoloBrain-0 | 地平线出品的在 Action DiT 里面用 URDF 硬编码一些计算模式的 Pi like VLA |
| LDA-1B | Galbot 出品的在 DINO 潜空间里联合预测动力学 / 策略 / 视觉的 MM-DiT 基模 |
| Xiaomi-Robotics-0 | 小米的 Choice Policy 训 VLM Action + Pi like VLA + 异步适配 Training RTC |
| DM0 | Dexmal 出品的 VLA,VL 输入之后进行多轮推理,然后之后输出 Action,以及不推理模式,包含可观经验以及预训练 |
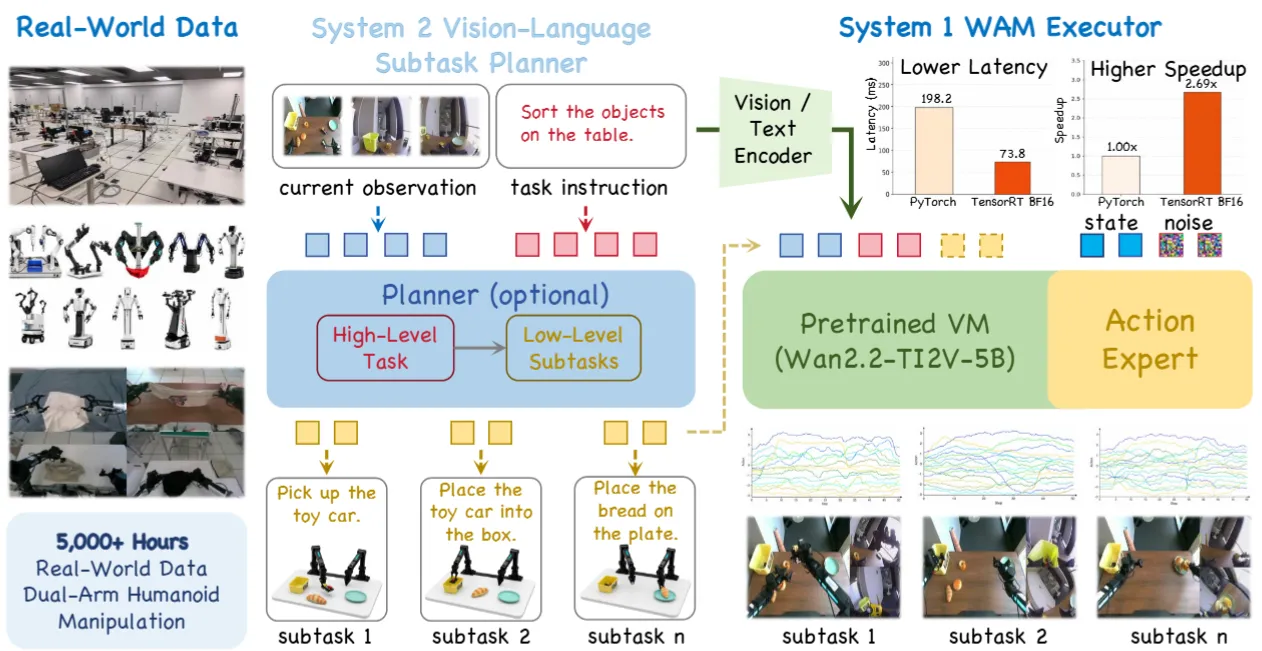
| PSI Lab 出品的 Ego 视频预训 + 机器人后训 + AMO 底层控制的三层 Humanoid VLA | |
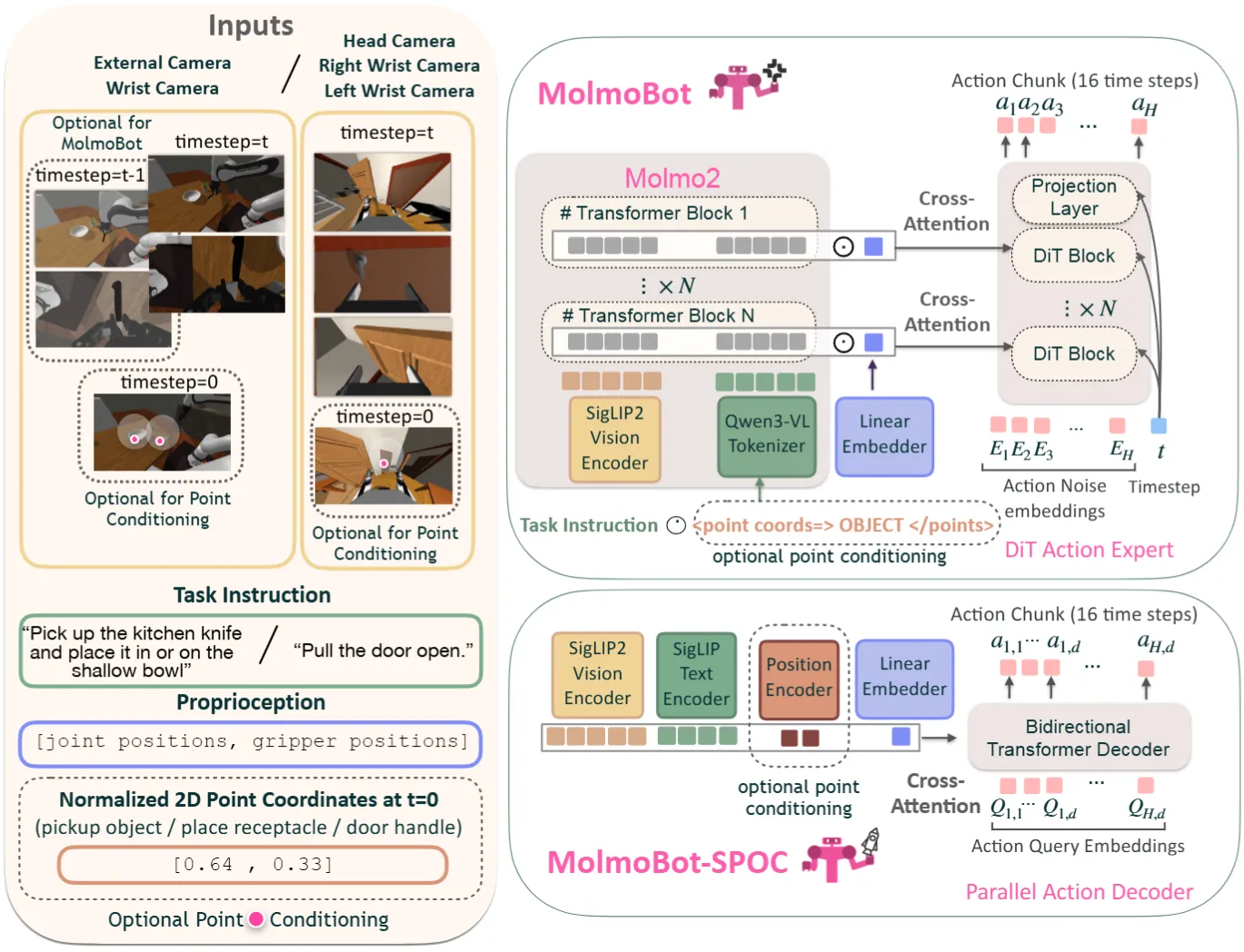
| MolmoB0T | AllenAI 出品的 Molmo2 + 1.7M 纯合成数据零样本到真机,cross-attn 接 VLM 中间 hidden state |
| JoyAI-RA 0.1 | JD 出品的 VLM + Fast Token + Actor Pi-like MoT 模型 |
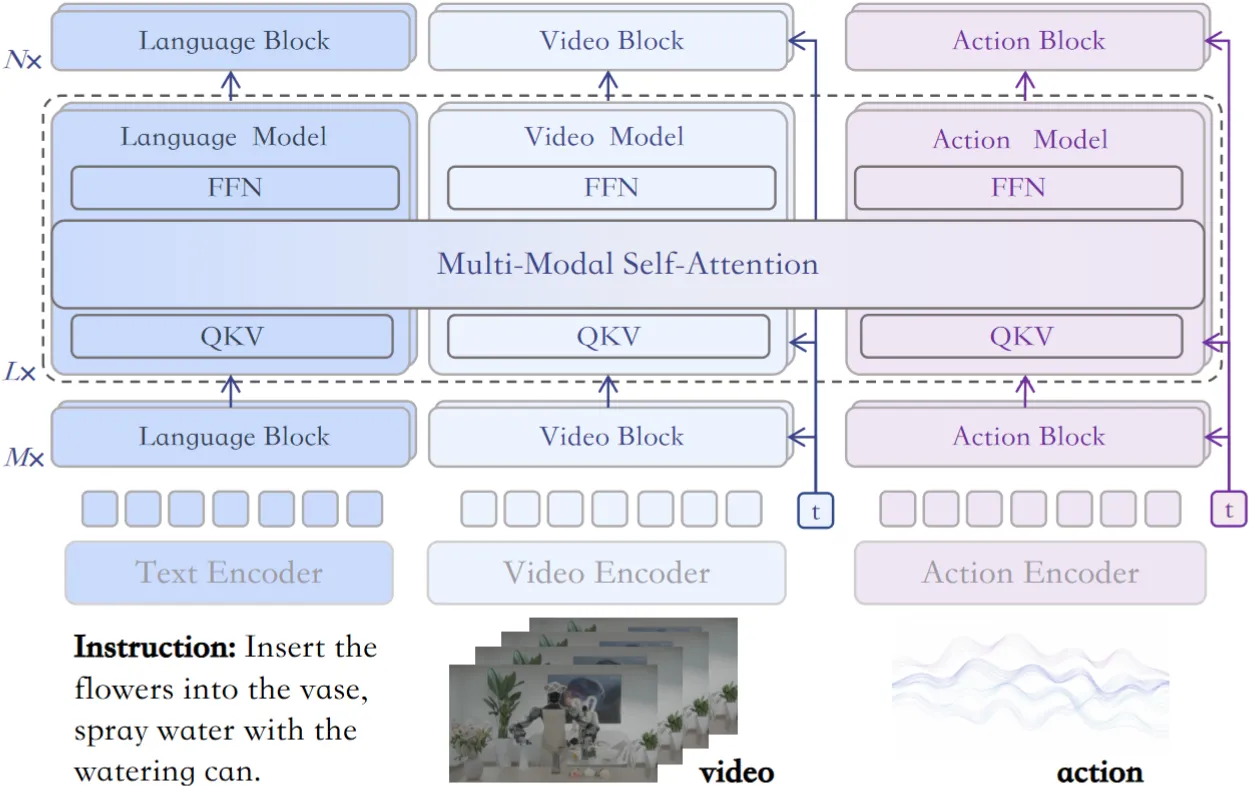
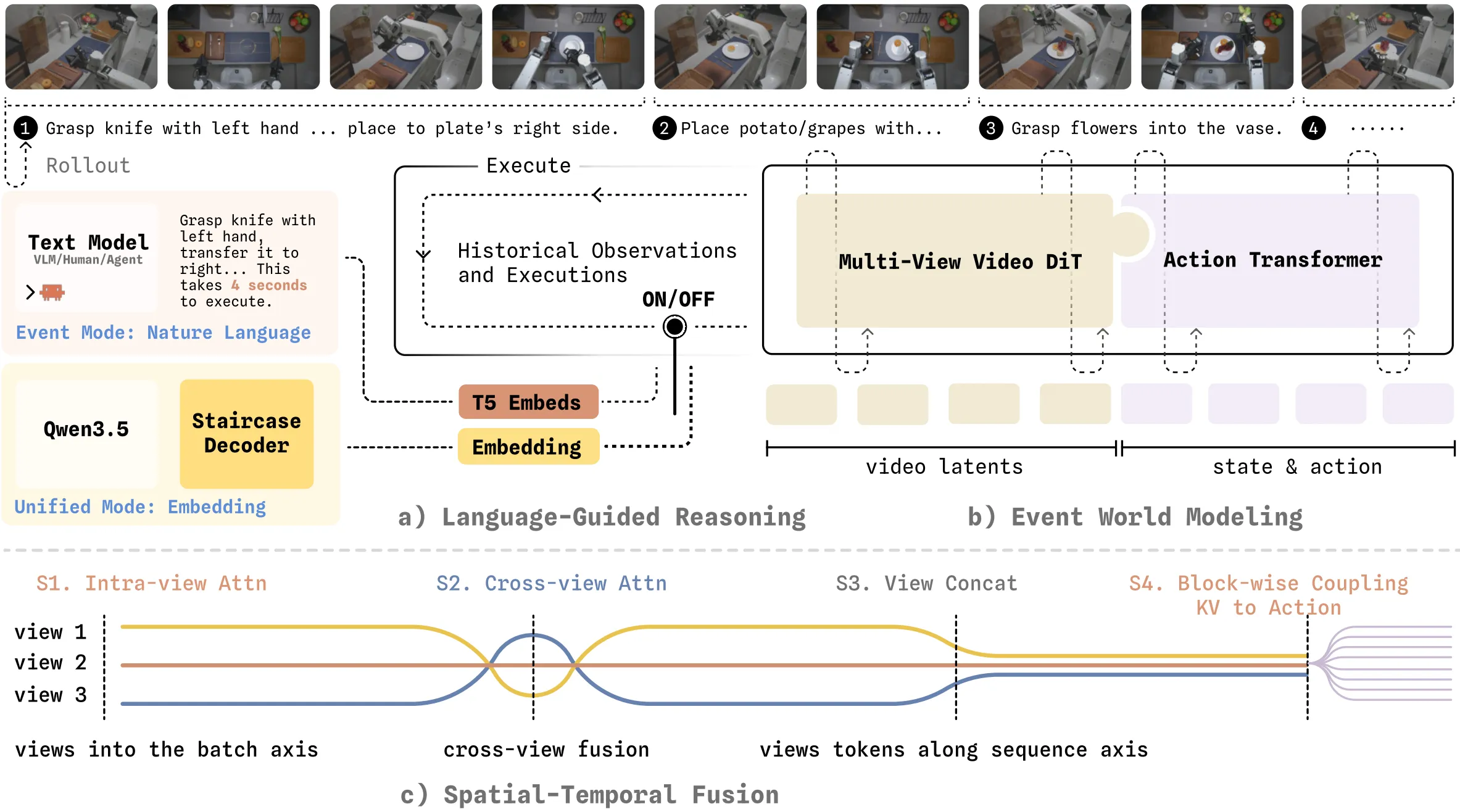
| MotuBrain | 生数出品的更完善的 Motus-like MoT 模型,以及一些细节优化,如使用 H-bridge attn |
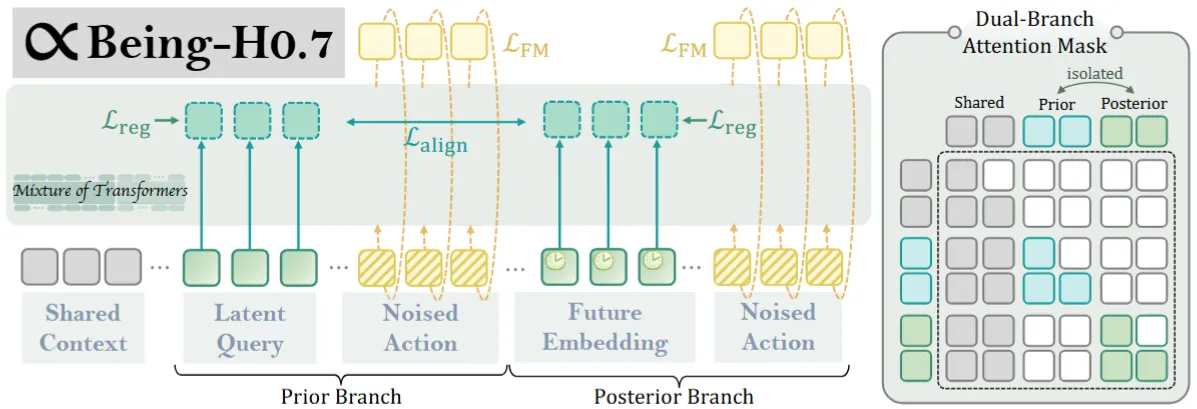
| Being-H0.7 | BeingBeyond 出品的使用 Latent Query 以及 Future Embedding,最后预测 Action 的 MoT |
| MolmoAct2 | AllenAI 出品的 Molmo2ER VLM + 预训练 Pi-like MoT 模型 |
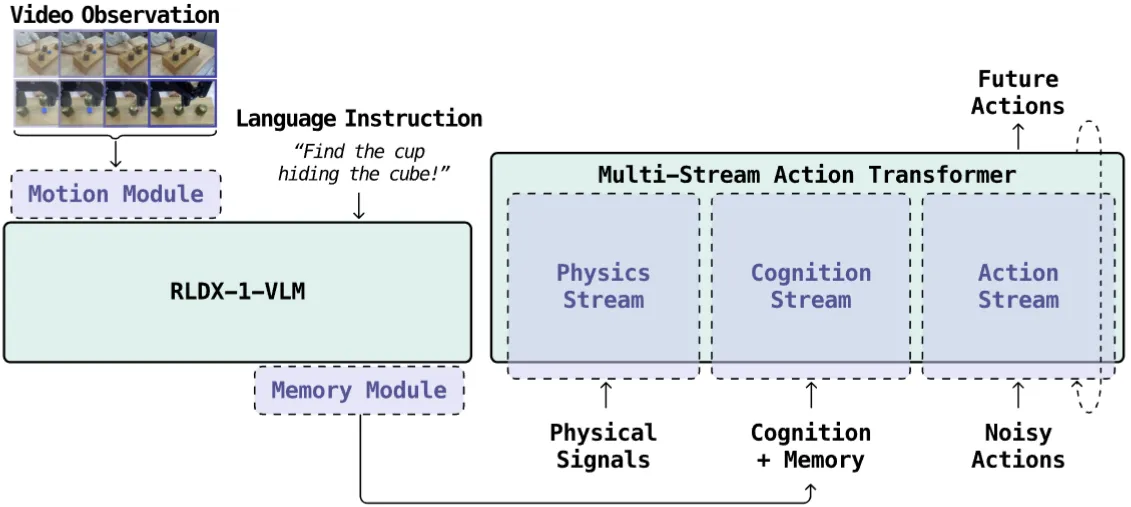
| RLDX-1 | RLWRLD 出品的 VLM 预训练 + VLM 中训练 + Actor 后训练的支持记忆以及触觉的 GR00t-like 模型 |
| PhysBrain 1.0 | 中关村学院出品的 LangForce 在 VLM + VLA 流程的技术报告,用 VLA 和 VAL 顺序输入数据并对齐 L |
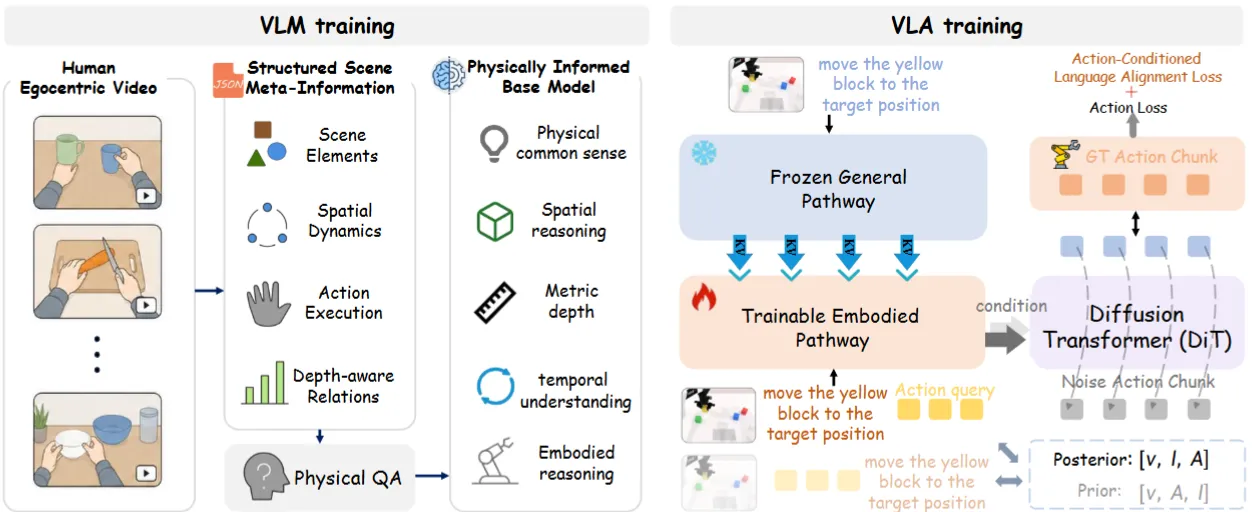
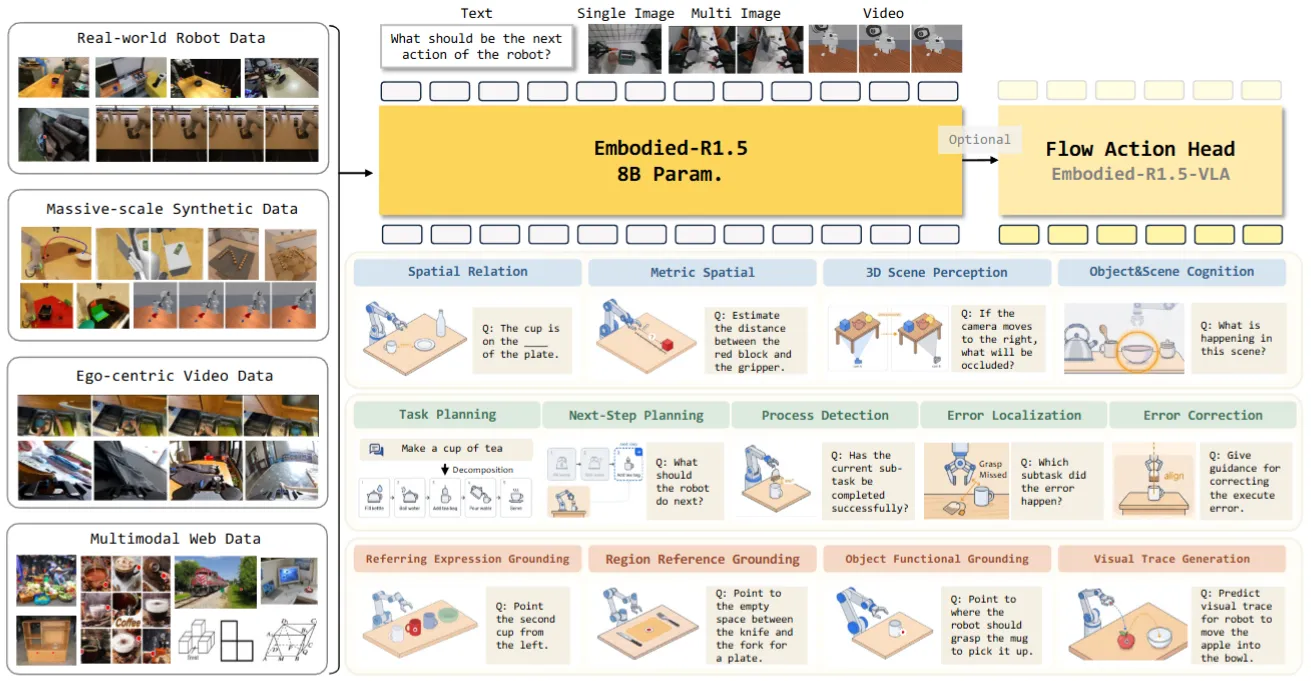
| Embodied-R1.5 | Hunyuan 出品的预训练具身 VLM + 可后训练 VLA |
| Wall-OSS-0.5 | 自变量机器人出品的预训练 Pi-like MoT |
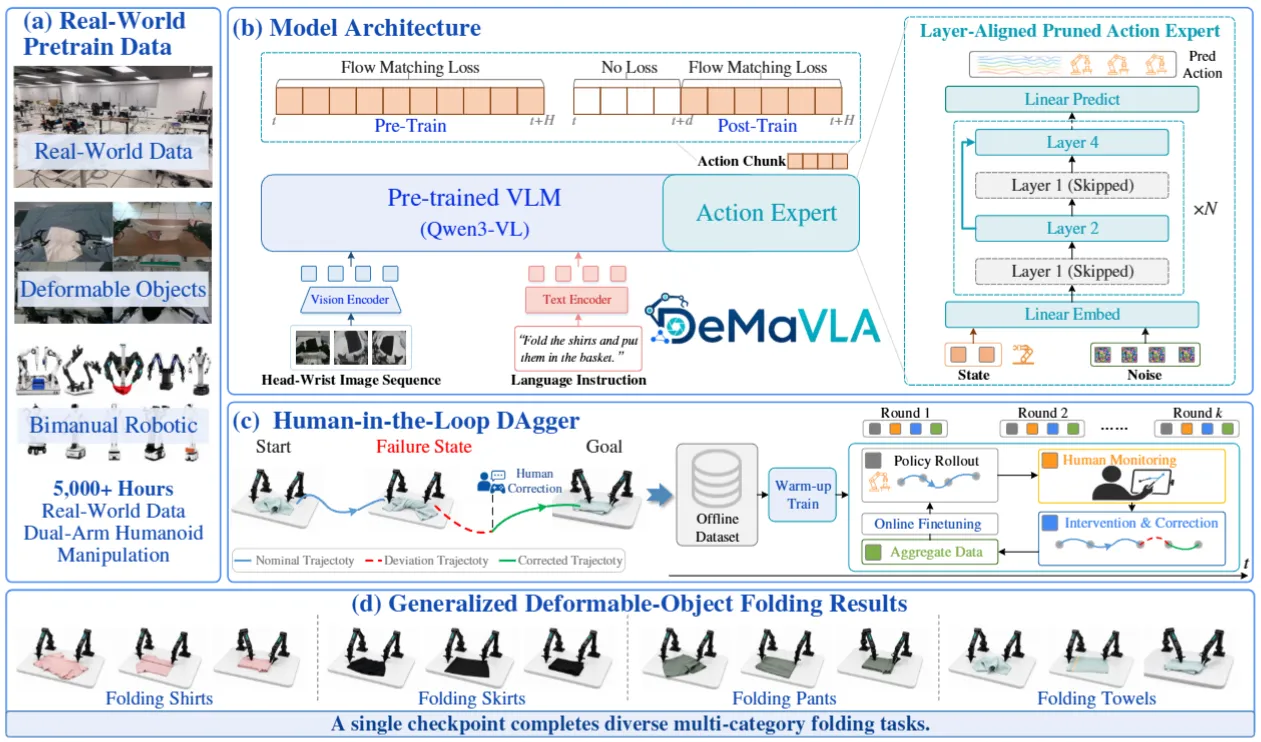
| DeMaVLA | 美的出品的预训练 Pi-like MoT + Training RTC + DAgger |
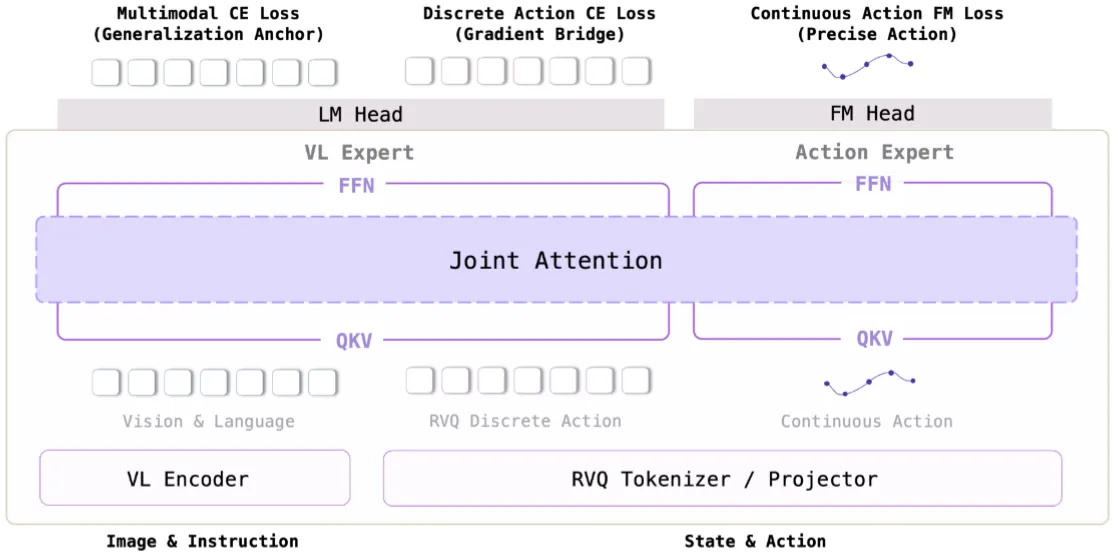
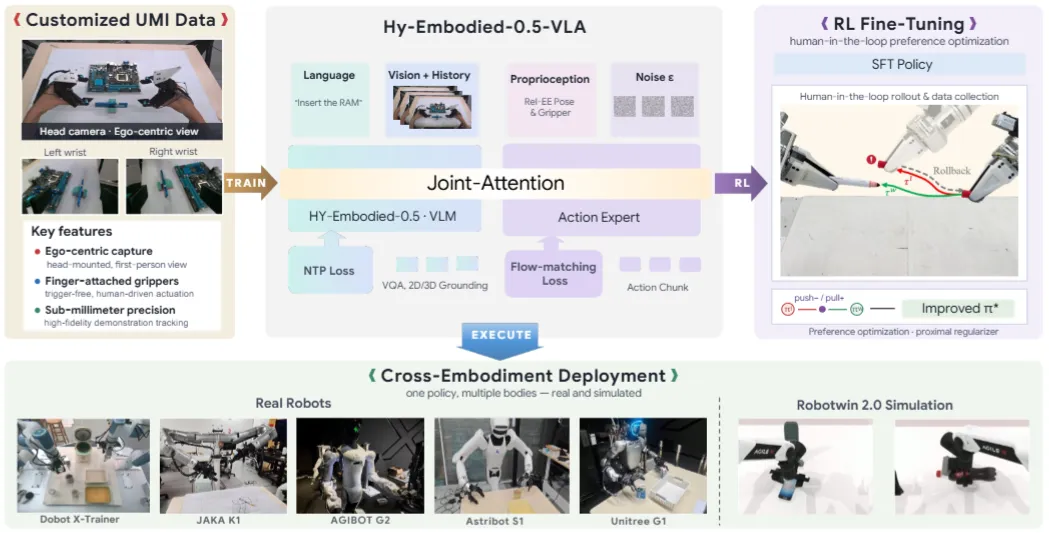
| Hy-Embodied-0.5-VLA | Hunyuan 出品的基于 Hunyuan VLM + Actor MoT 的预训练模型 + RL 后训练 |
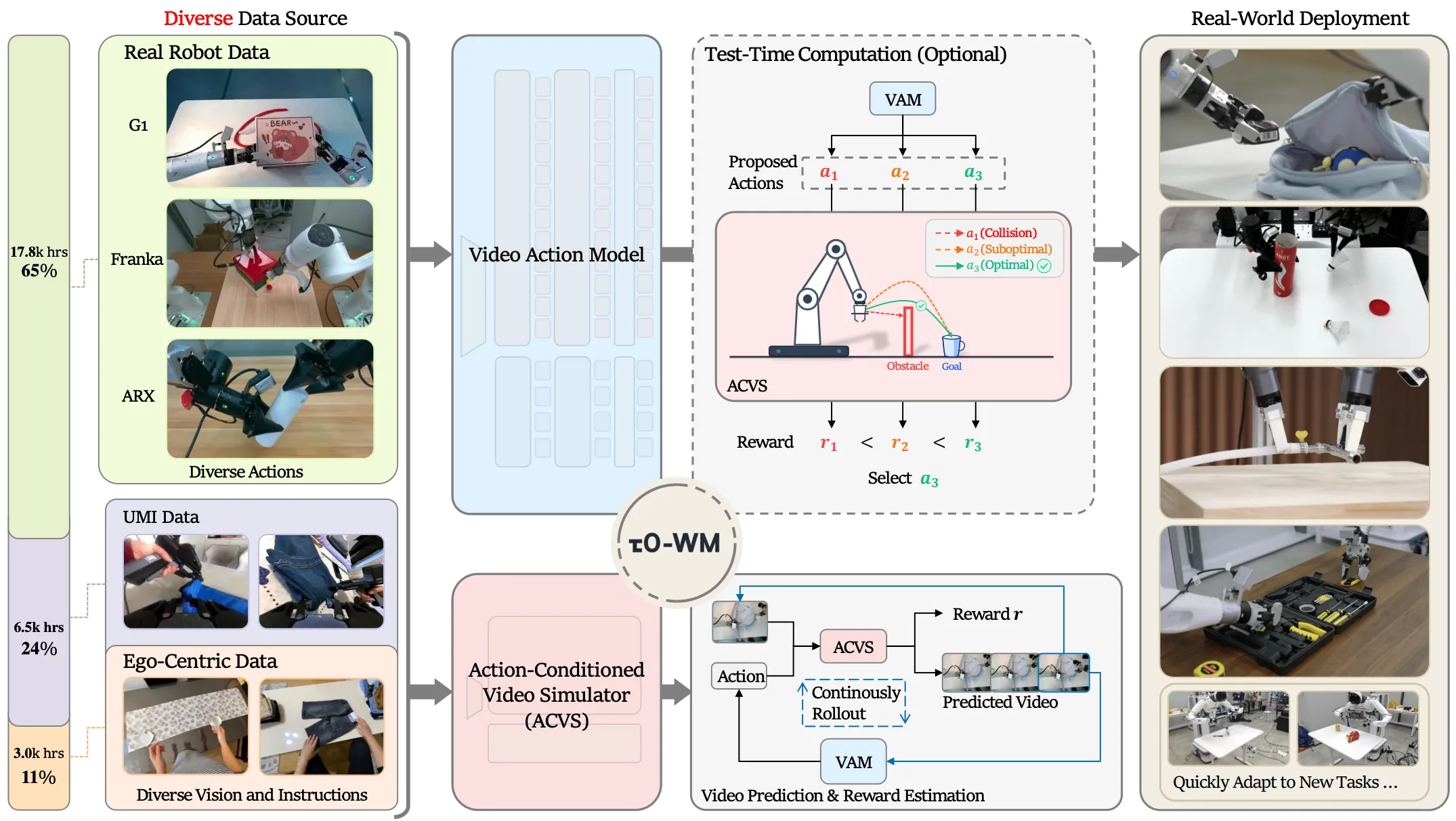
| -WM | AGIBOT Finch 出品的 WM 进行 Action-condition WM 以及 WAM 训练 |
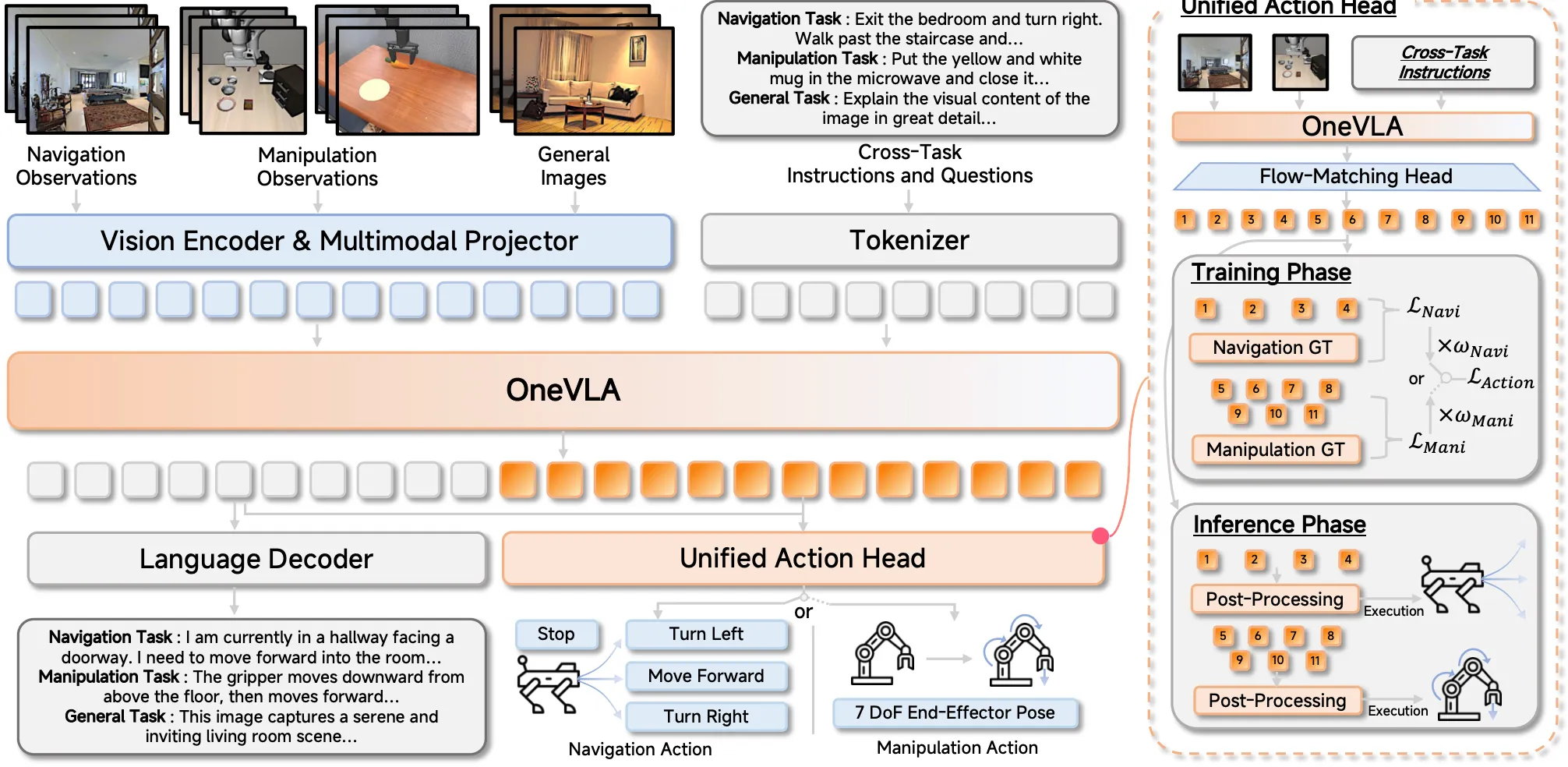
| OneVLA | 小米出品的 concat VLN VLA space 来实现统一框架的 GR00t-like VLA |
| WALL-WM | 自变量出品的 High Level VLM 指令输出 + 下游预训练 WM + Actor 框架 |
| ABot-M1.5 | 高德出品的 Video + Latent Action + Action MoT 的 VLA |
| InternVLA-A1.5 | SHAILAB 出品的 VLM + Actor 的 MoT,并且预测 WM 的 Condition 但是在推理时不接 WM |
| DSWAM | 美的出品的 VLM + WM-VLA 的双系统框架 |
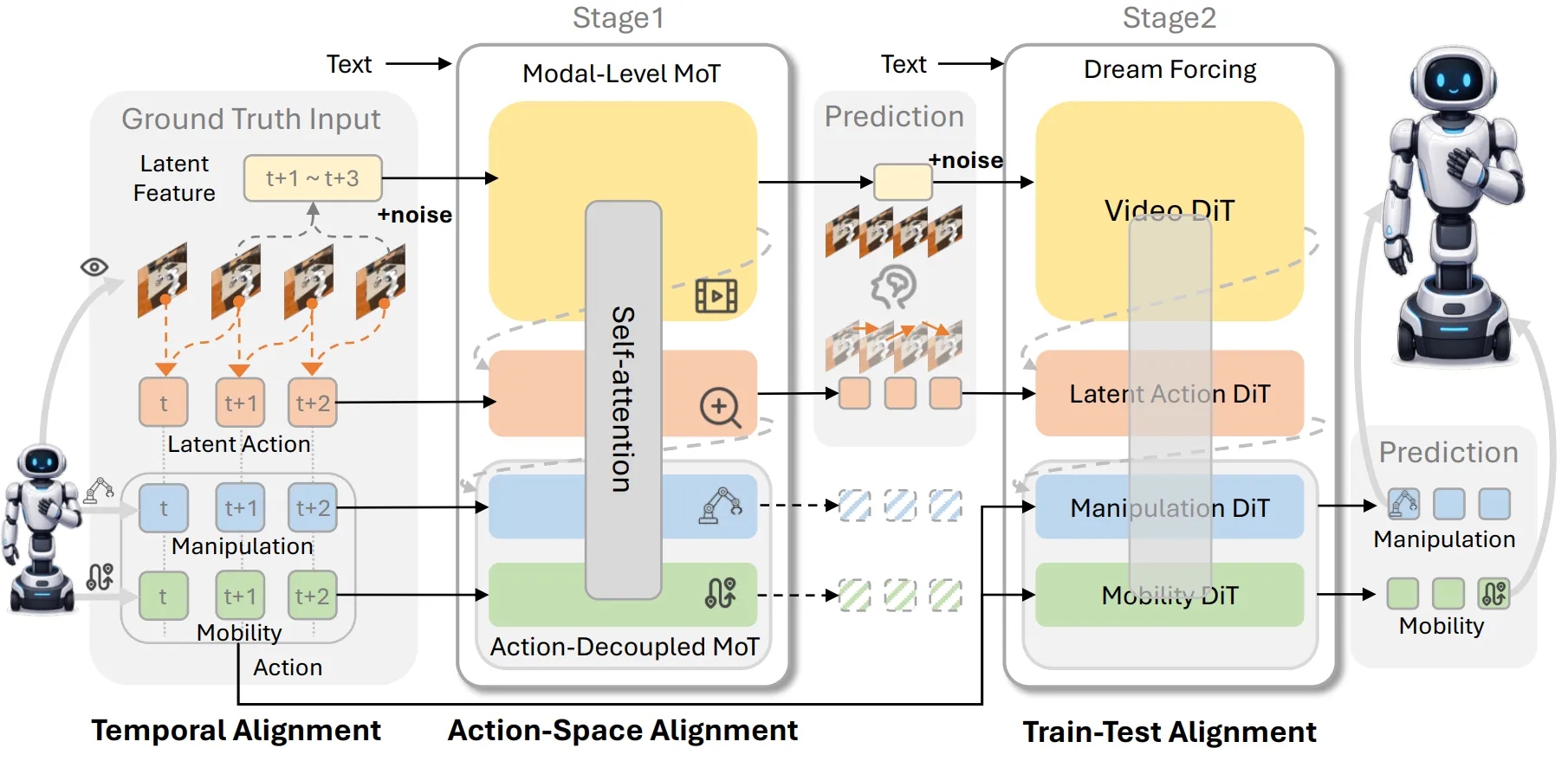
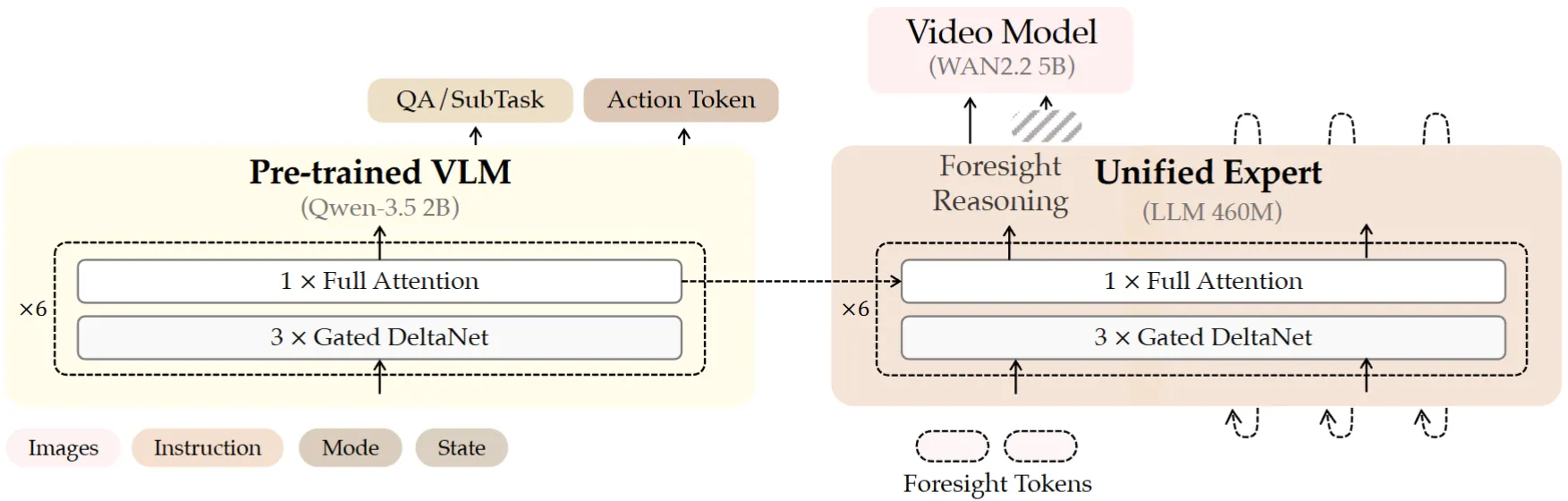
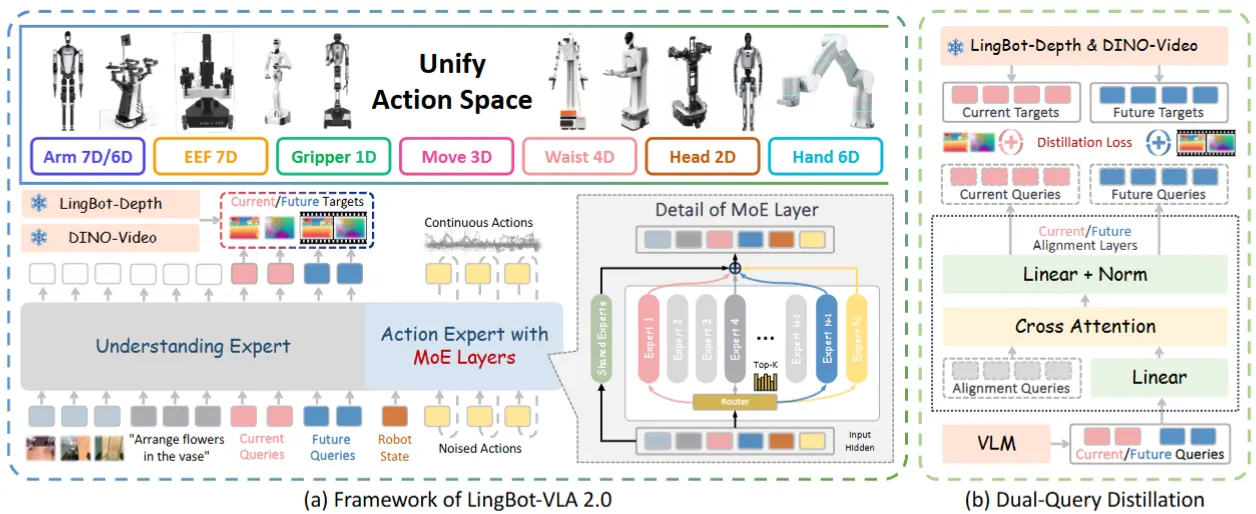
| LingBot-VLA 2.0 | LingBot 出品的比较系统的 VLA,同时预测 DINO 以及 Depth 的特征,MoE 的 Actor,以及一些数据清洗的说明 |
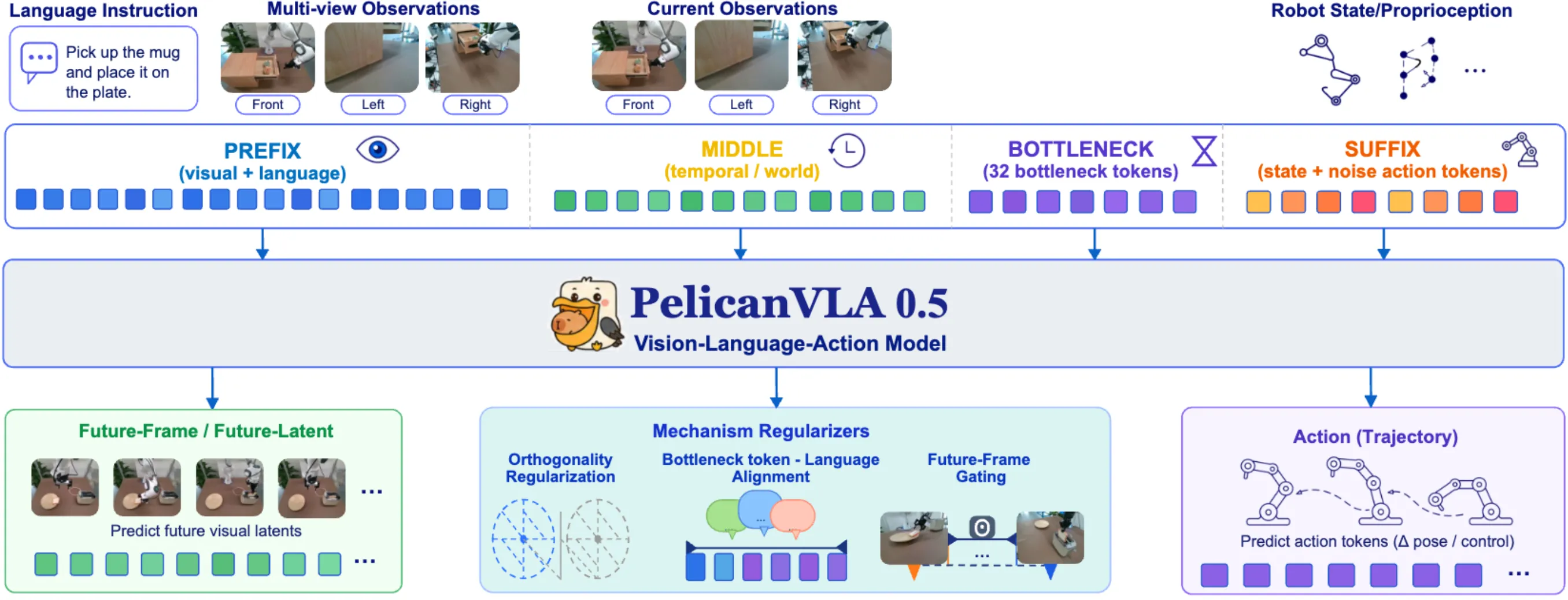
| Pelican-VLA 0.5 | 北京人型出品的统一的 Transformer 预测 future token + BotToken(可学习的 Token,包含若干约束) + 噪声动作块 |
| Lumo-2 | AstriBot 出品的 Qwen 预测 Dynamic Token 并以此仅一步预测 Action Token,然后转为连续 Action Chunk |
| GigaWorld-Policy-0.5 | GigaAI 出品的 MoT WAM,推理时可不预测 Visual |

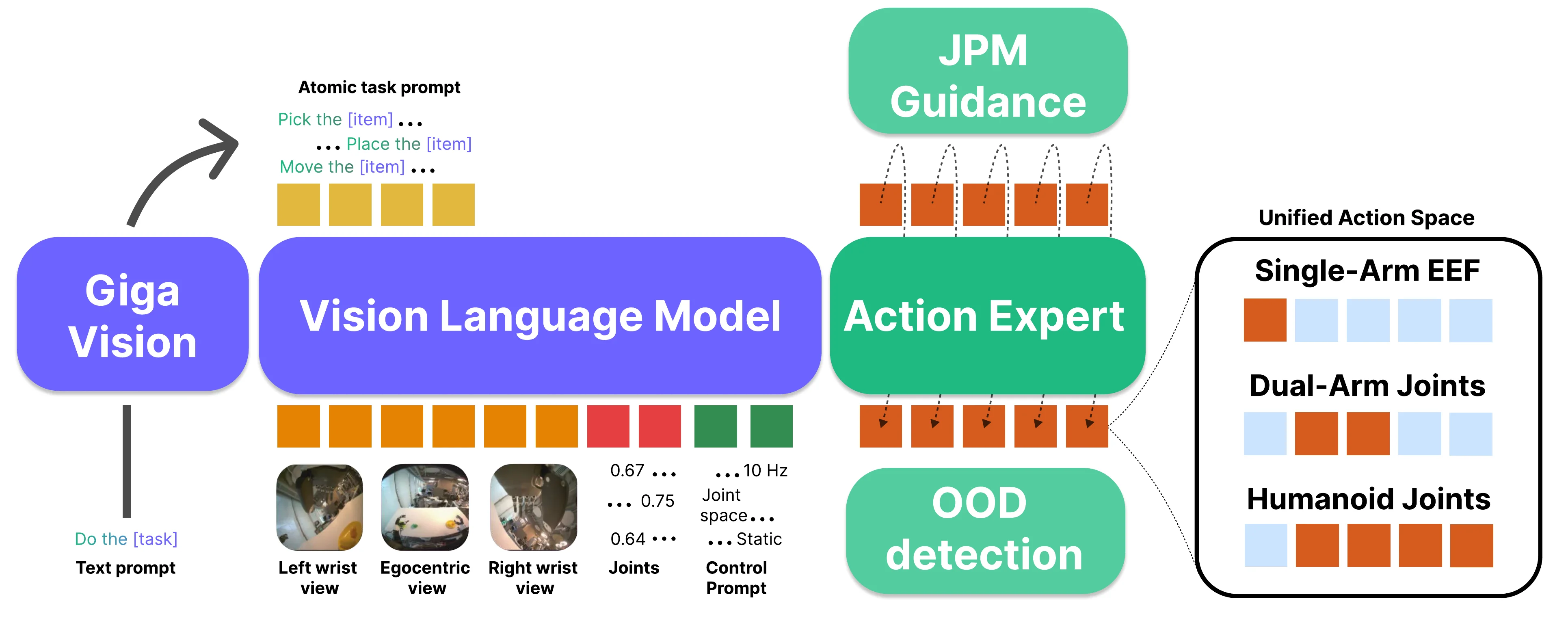

新架构探索/其他#
一些不足以作为代表性,但是相对有一些值得一提的点的论文将被放在这里,但是总体上它们依然遵循 VLA 的任务范式:
dVLA#
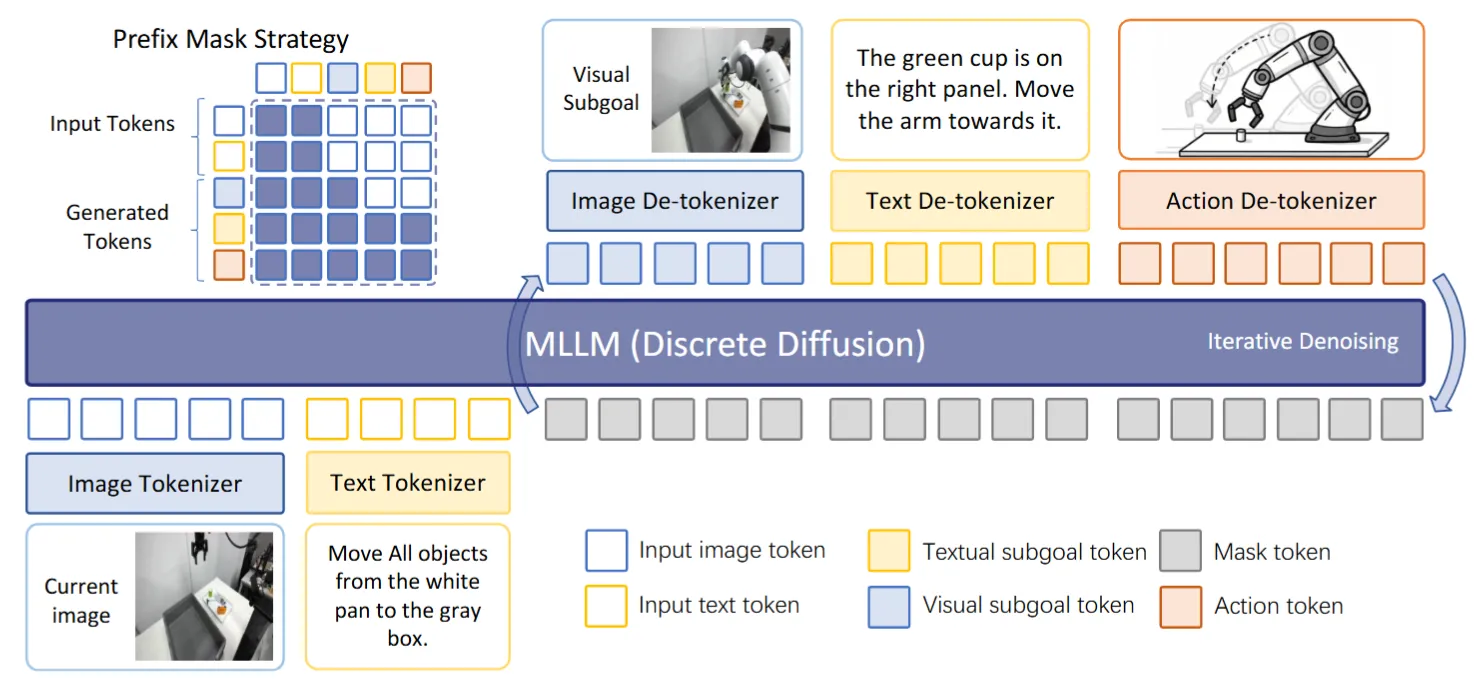
dVLA 即基于 Diffusion LM 或者 VLM 搭建的 VLA 模型,依然保持 Unified 的 training objective。
| 论文 | 主要贡献 |
|---|---|
| dVLA | 比较规整的 dLLM 用 diffusion 同时预测 image、language 以及 action |
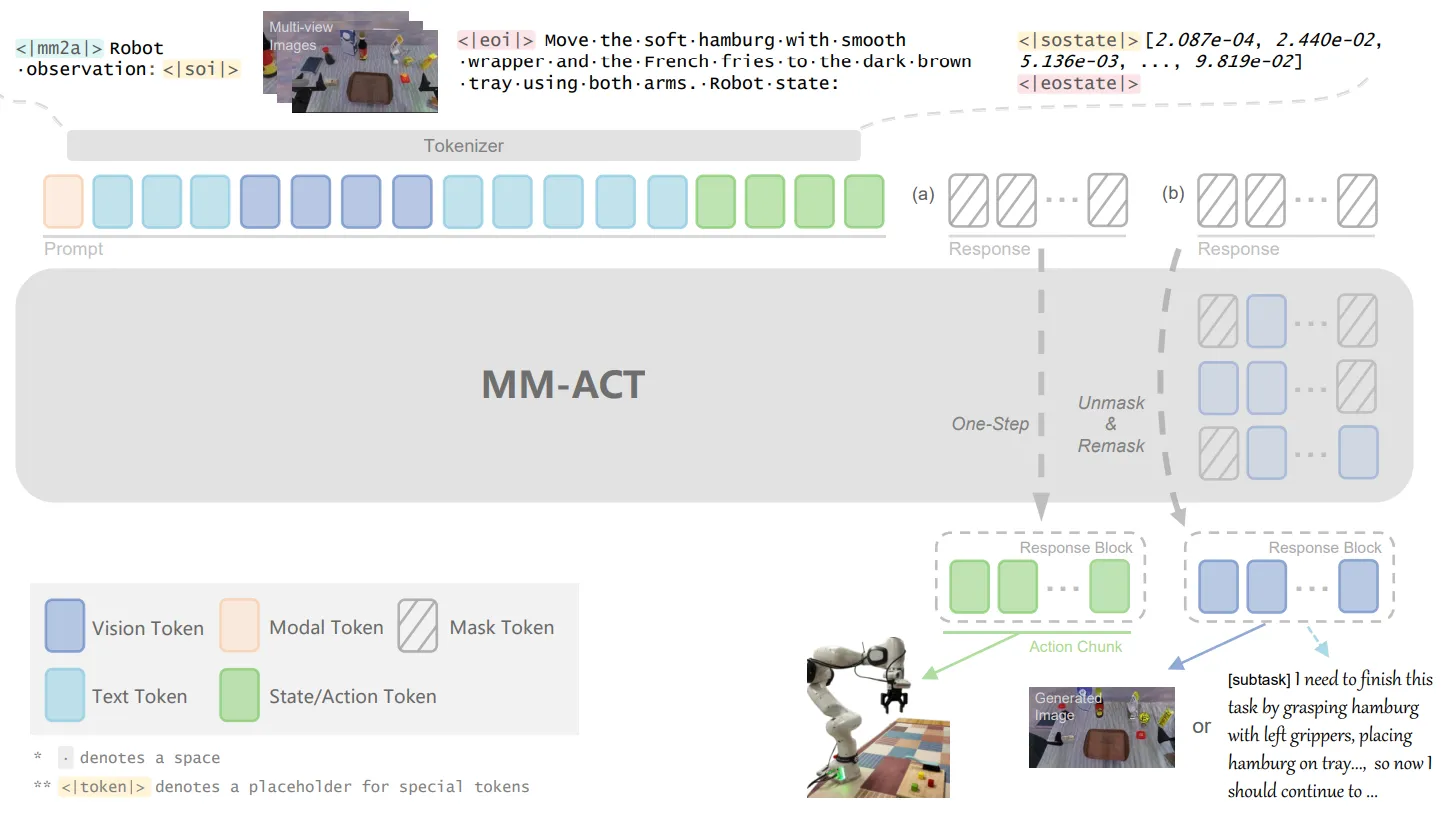
| MM-ACT | 基于 LLaDA 的 dVLA,可同时预测 Visual Language Action 三种表征。 |
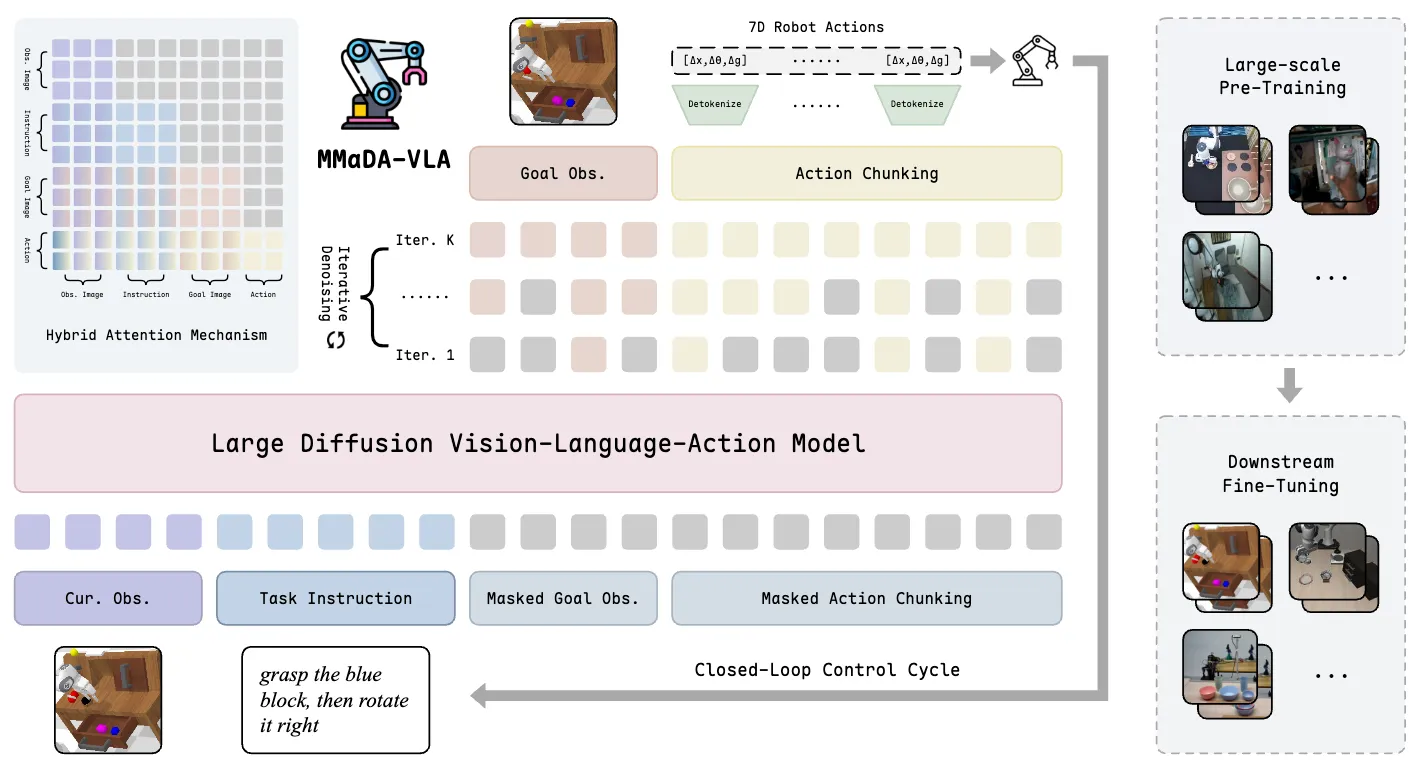
| MMaDA-VLA | 基于 MMaDa 的 dVLA,预测 Goal Image 以及 Action |
其他架构#
| 论文 | 主要贡献 |
|---|---|
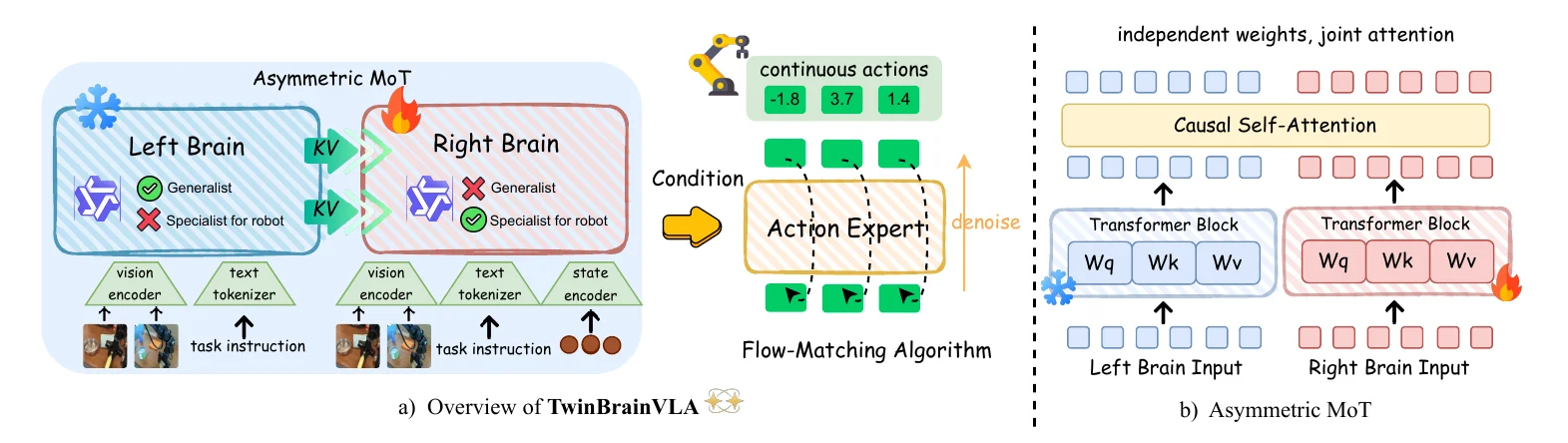
| TwinBrainVLA | Frozen VLM + VLM + Actor 的 MoT 以避免灾难性遗忘 |
| BagelVLA | 使用 Babel 的 VLM + VLA + Actor MoT,同时探索了桥接的不同降噪策略 |
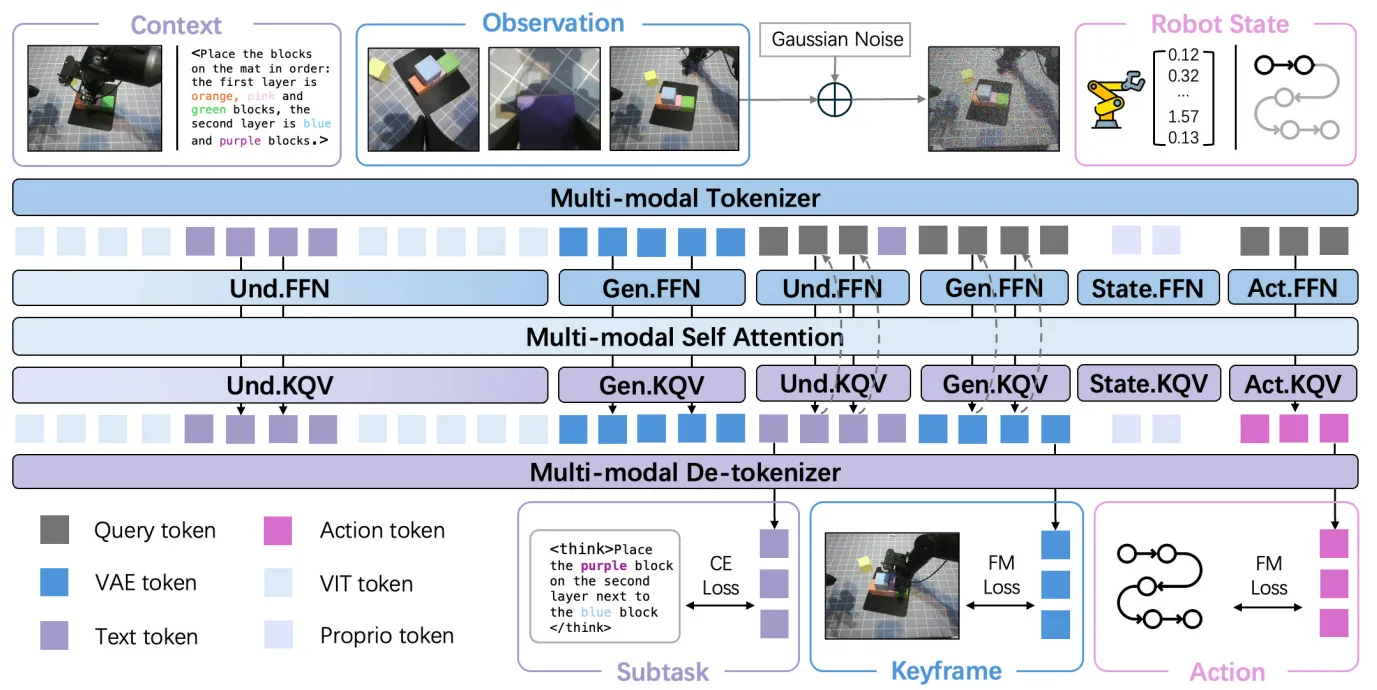
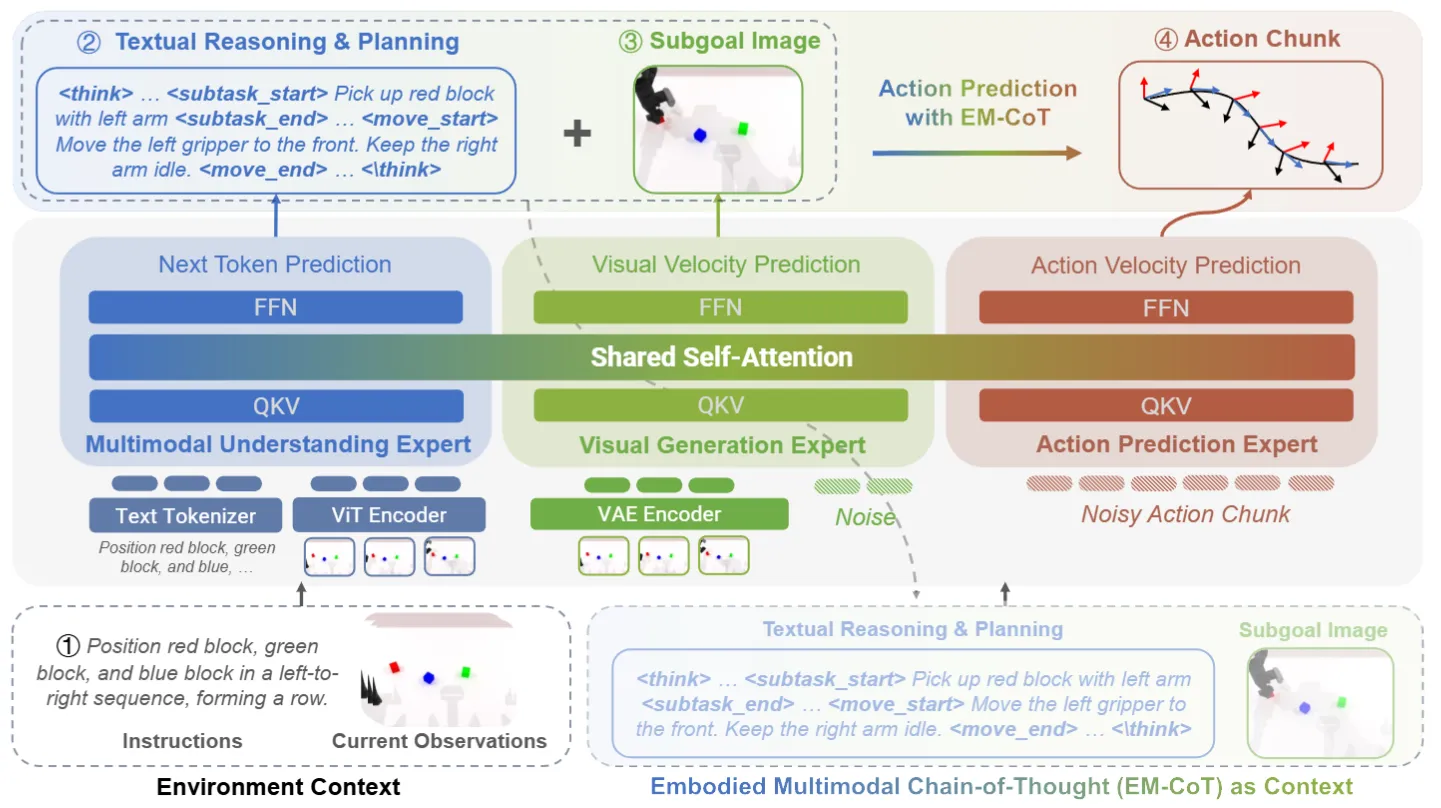
| HALO | 文本 CoT / 视觉 subgoal / 动作三专家 MoT VLA |
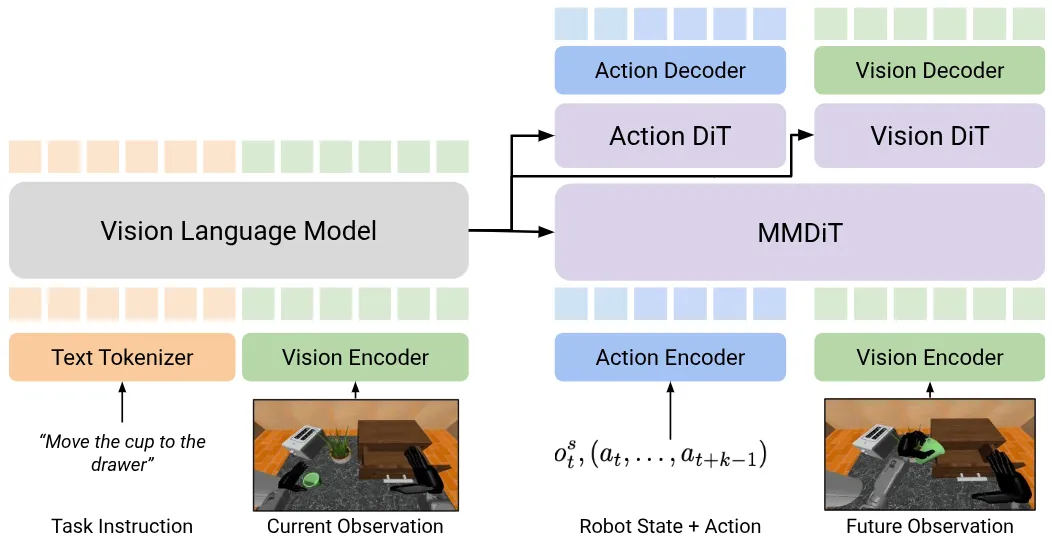
| DUST | 在 Actor 部分使用 MMDiT + Joint Diffusion |
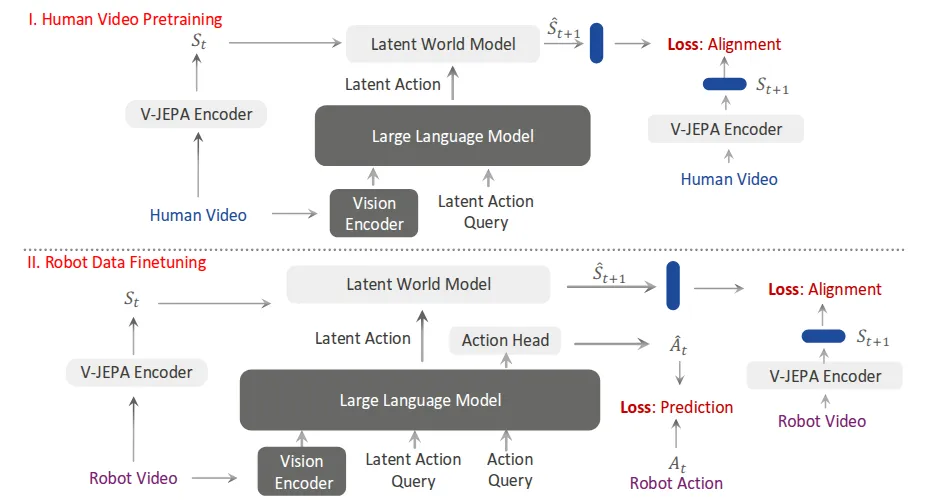
| VLA-JEPA | JEPA 风格的 latent 未来预测作为协同监督从而可以 Leverage Human Data |
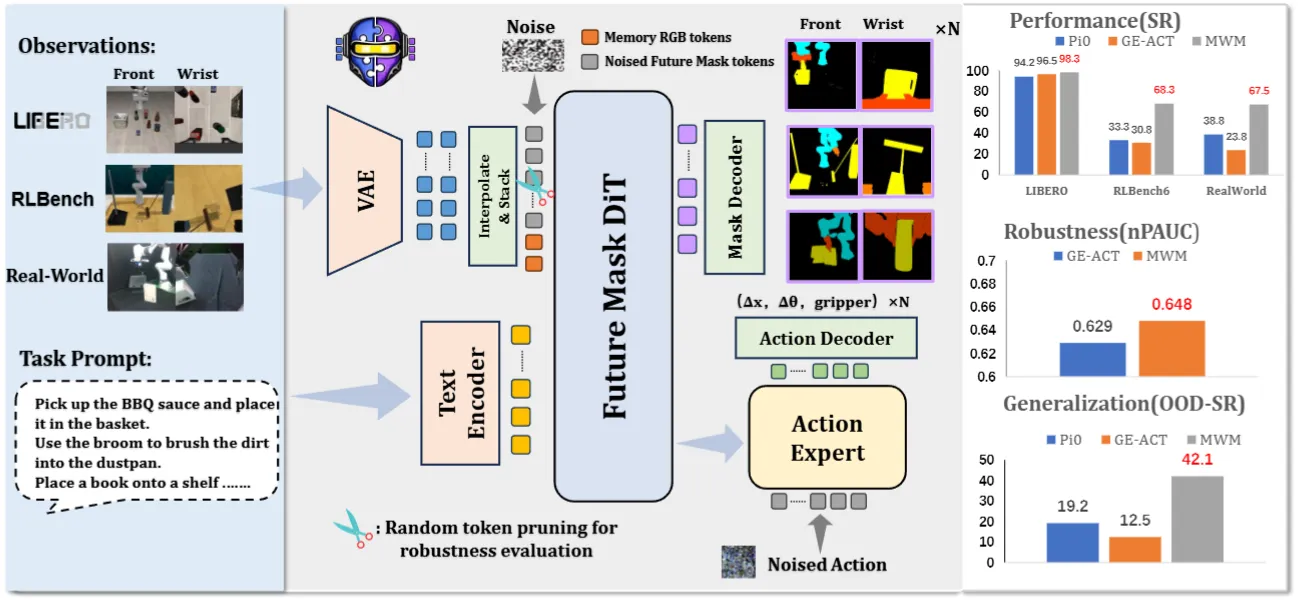
| MWM | 预测未来的 Mask 的 WM + Actor DiT 的 WAM |
| PriorVLA | Frozen VLA + Actor 的 MoT 来利用 VLA 先验知识 |
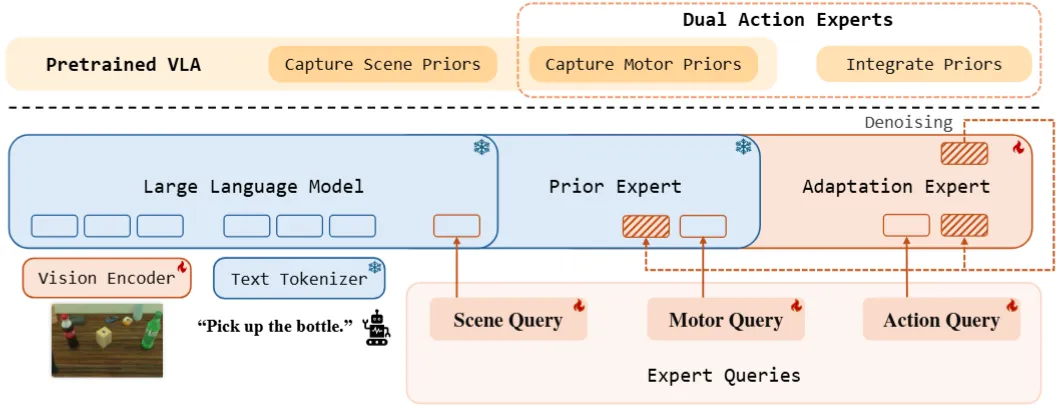
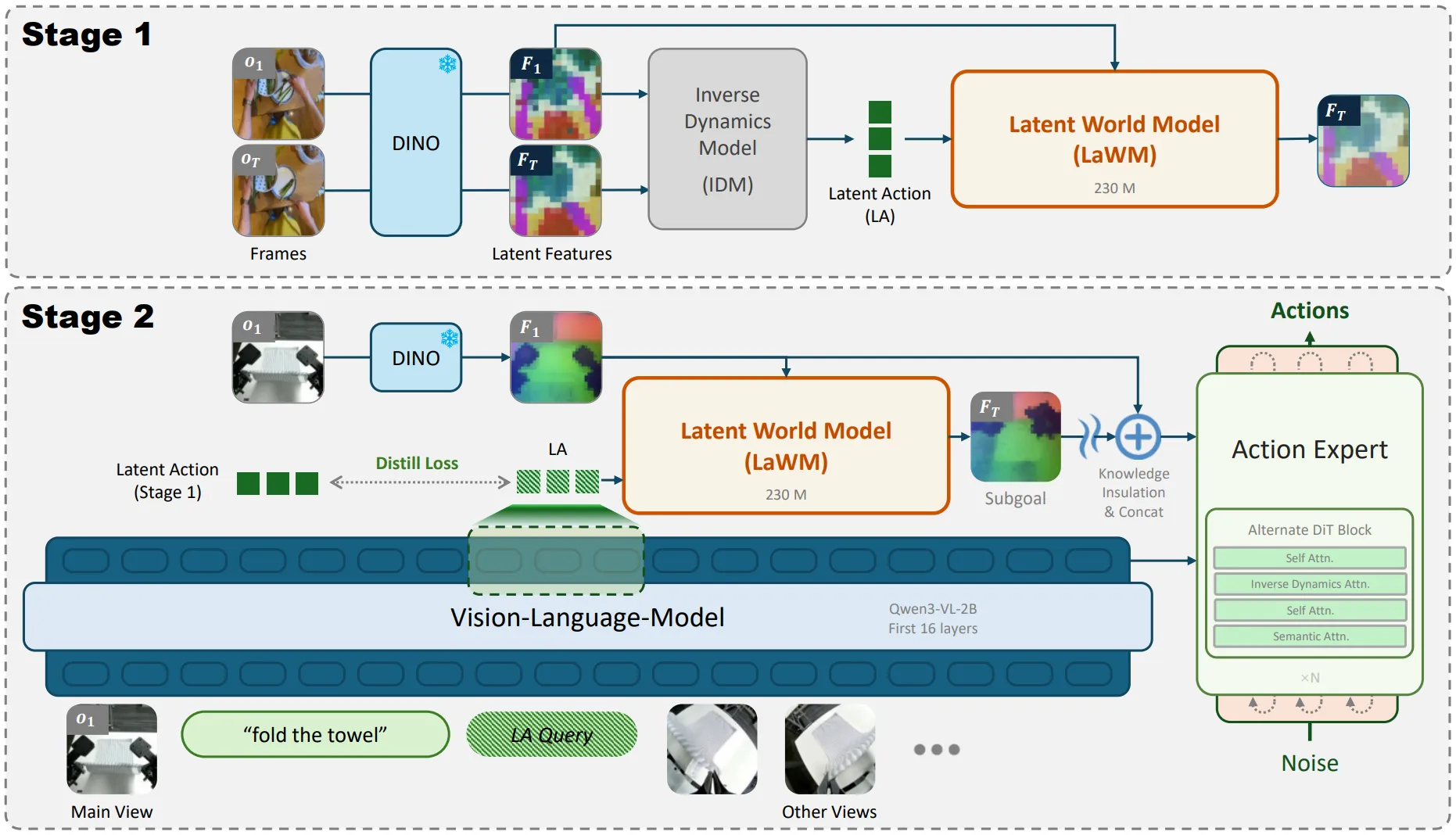
| LaWAM | 训练 Latent WM,VLM 预测 Latent Action 输入给 LaWM 预测 Latent Feature 然后输入给 Actor |
| ASPIRE | 将 Single Skill Policy 作为一个 Skill 加入到现代 Agentic Coding 框架,并且使得其可以不断变强 |
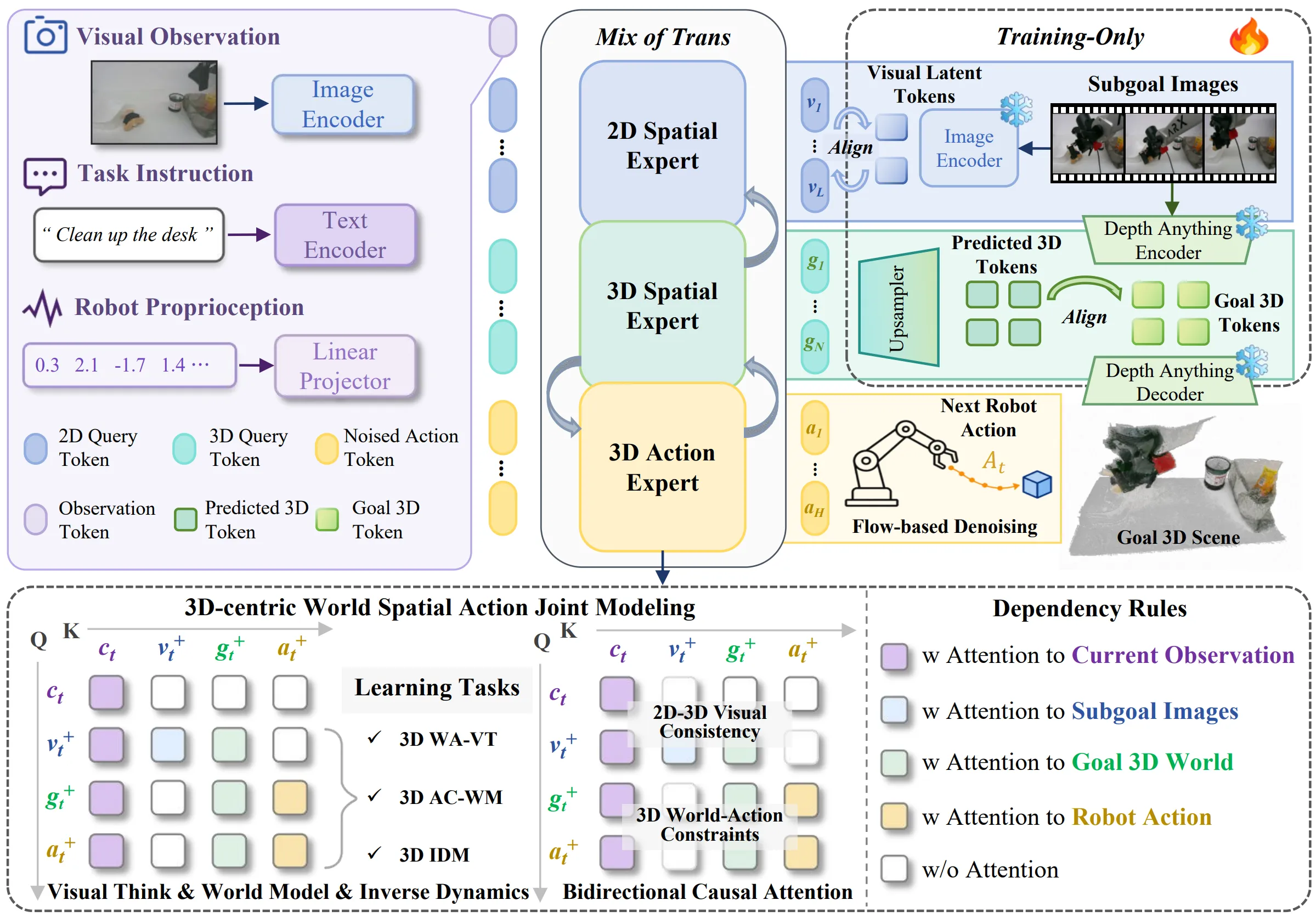
| 2D Thinking + 3D Modeling + Action 的 MoT VLA |

Tricks#
在这里包括一些在训练或者部署上的细节设计,这些设计并不是方法级别的,或者易于迁移到已有的方法上,从而达到不错的效果,可以在后续的模型调优中参考:
| 论文 | 主要贡献 |
|---|---|
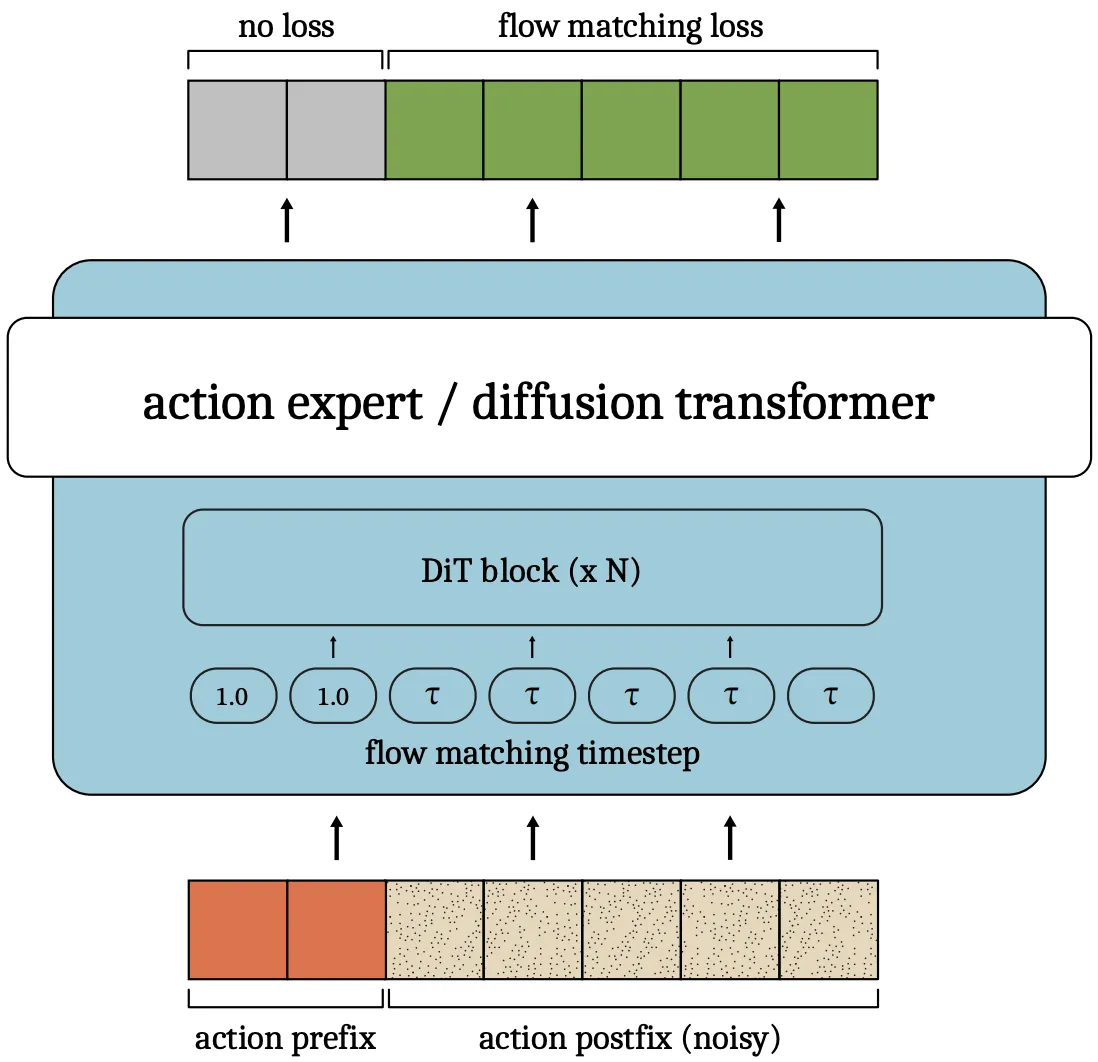
| Training-time RTC | 在 Denoise 前面加一段 Action prefix |
| Action2Action | 对于 Flow Matching 不采样 noise 而是使用之前的 Action |
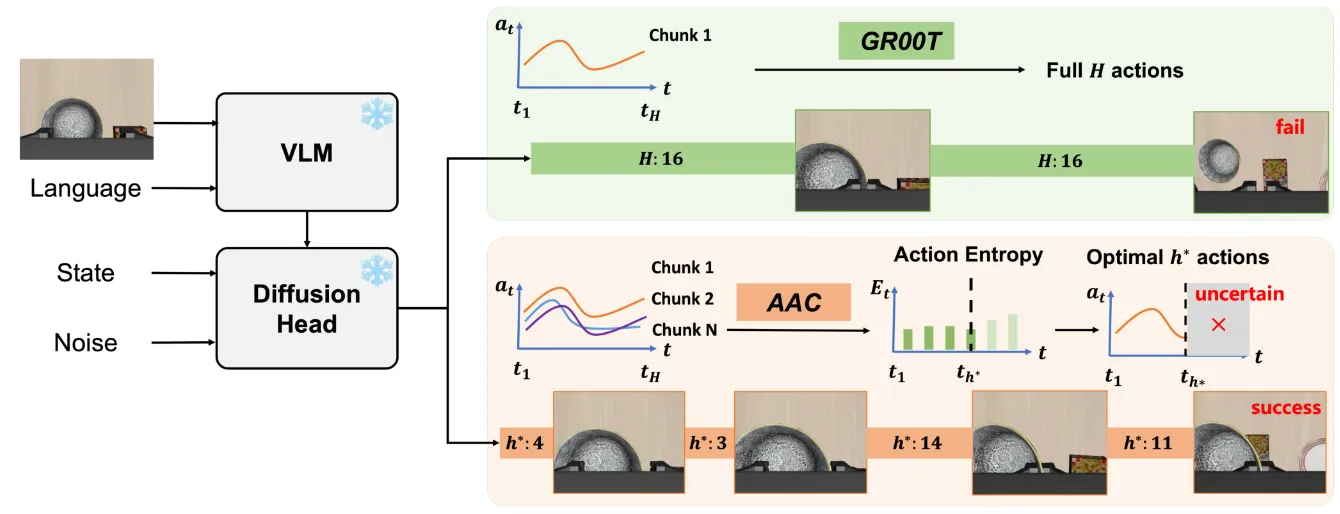
| AAC | 使用动作熵,在推理时动态选择 Action Chunk 大小 |
| 自适应的 VLM 和 Actor 早停以加速推理 |
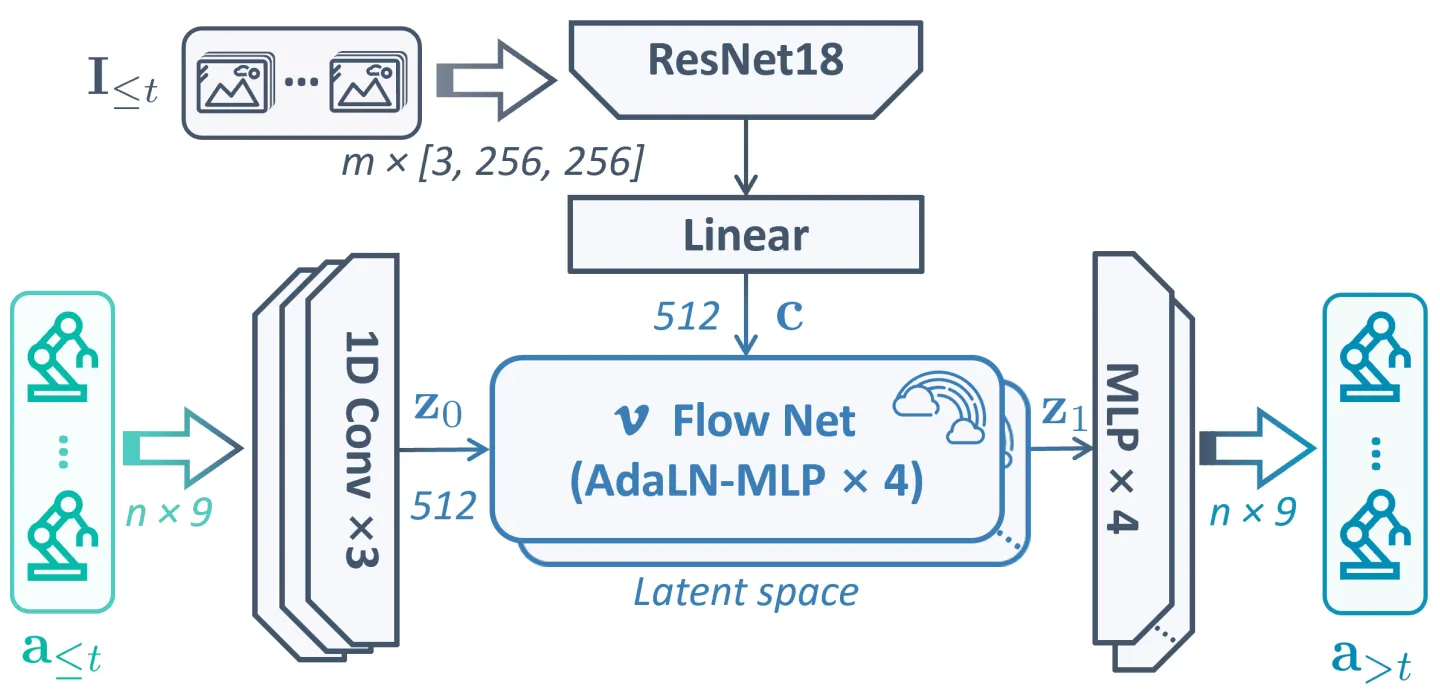
Policy 模型#
站在 VLA 模型的对立面,policy 则是我们对于另外一种模型的名称概括。通常来说,这些模型的参数量较小,具有着某种来自于计算机视觉领域较早时期的风格,它们往往基于一些 Transformer block 以及一定的 encoder 进行设计,并且论文的创新点或许也主要集中在对于模型结构内特征交互的改进。
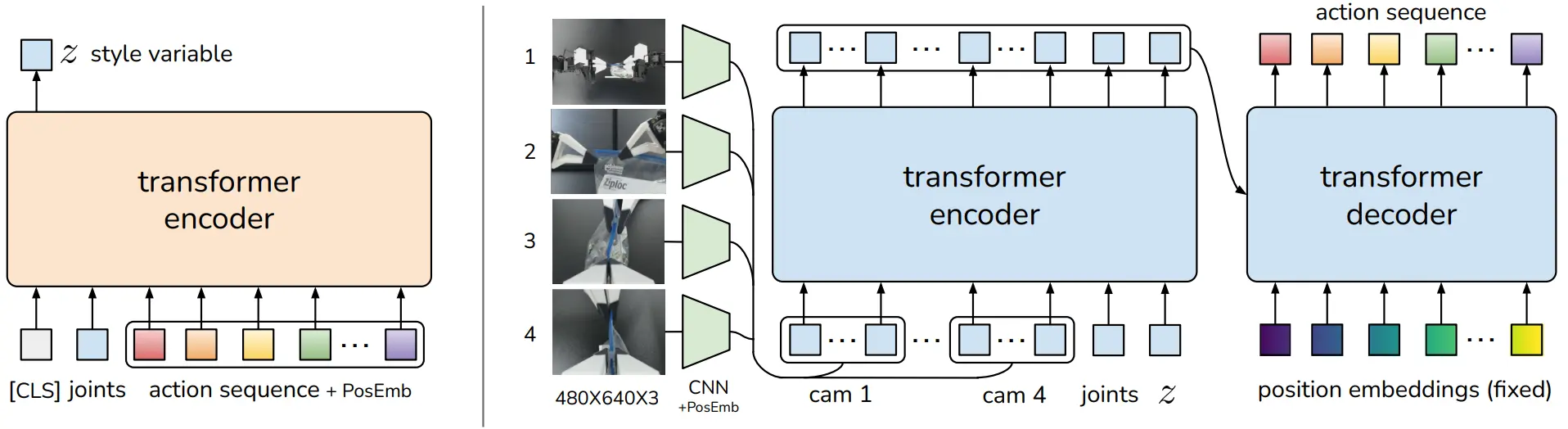
ACT 是最为经典的 Policy 模型,虽然在 23 年提出,但是在如今大量的机器人公司的 Demo 调试中依然被广泛使用,大多数时候因为 Demo 需要鲁棒的过拟合,ACT 的设计显然是非常适合的。本身 ACT 使用了 CVAE 来预测 Action,是一种直接且有效的方案。本身 ACT 提出了 Action Ensemble,即将预测的 Action 进行 EMA 平滑。
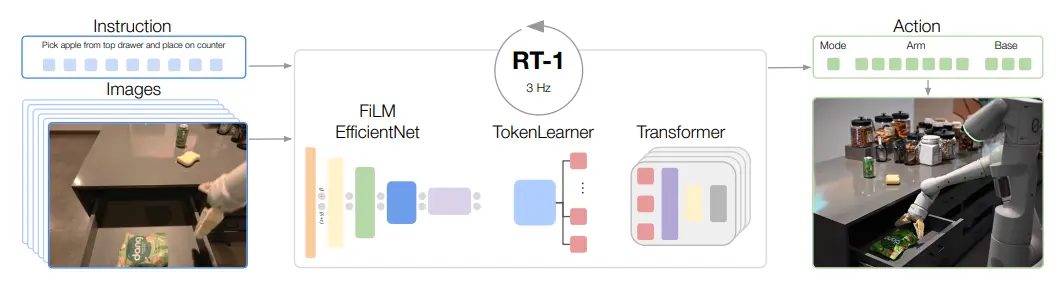
RT-1 是谷歌团队基于他们自己采集的数据集训练的 Policy 模型,即 Robot Transformer,虽然在此之后很快,RT-2 就成为了 VLA 的范式,但是本身这篇论文依然比较经典。
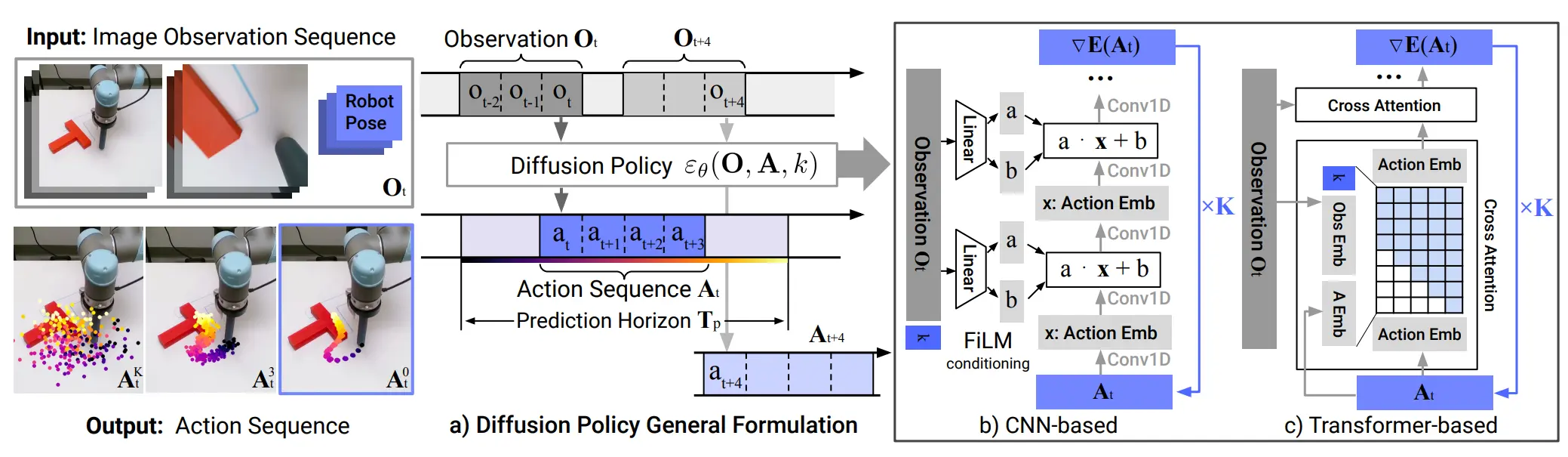
另外比较经典的就是 Diffusion Policy,也就是直接使用 Diffusion 来预测 Action,并且用 Obs 作为 Condition,这一方法在后续得到了大量 Policy 论文的 Follow-up,有必要注意的是 3D Diffusion Policy,其本身输入的内容变为点云,使得在其他工作的应用中,可以通过仿真或者其他无法生成可靠贴图,但是存在可靠点云的数据中进行训练。
Humanoid#
长久以来人形机器人的发展也是一个主线,相较于 Manipulation 的任务,人形机器人的发展方向主要即 Locomotion,难点在于对于人形机器人,如何使用算法使得人形机器人在执行复杂的动作的同时可以保持身体的平衡等。这一领域一方面并非本文重点,一方面前后涉及范围过广,我们在这里仅列举近期的几个有代表性的工作。
其中 BeyondMimic 是最近非常不错的工作,用紧凑的 motion-tracking 先把一堆高动态技能学下来,再用 latent diffusion + classifier guidance 做技能组合和 unseen 任务泛化,支持 motion editing、teleop、避障,零样本部署到真机。
同时,System 0 这一概念也在 VLA 中兴起,即预训练一个可以用于运动控制的基础模型,使得上有 VLA 可以输出正常的机器人动作,由 System 0 来进行具体的运动控制,达到合理的状态。这一方面,NVIDIA 的 SONIC 是具有代表性的突破,通过统一 token space 支持 VR 遥操作、人类视频、VLA 等多种输入,使用了 42M 参数 + 100M 动捕帧进行训练。
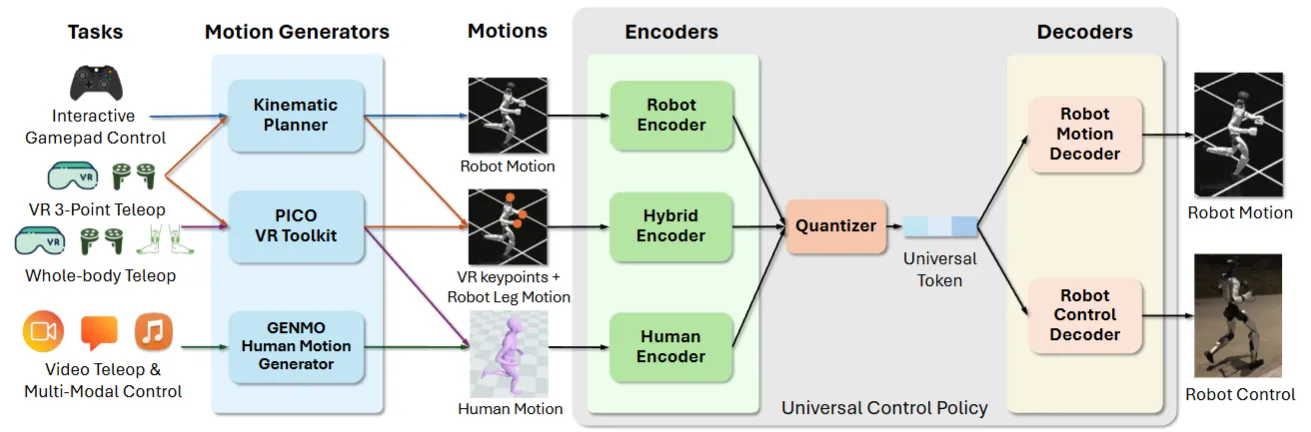
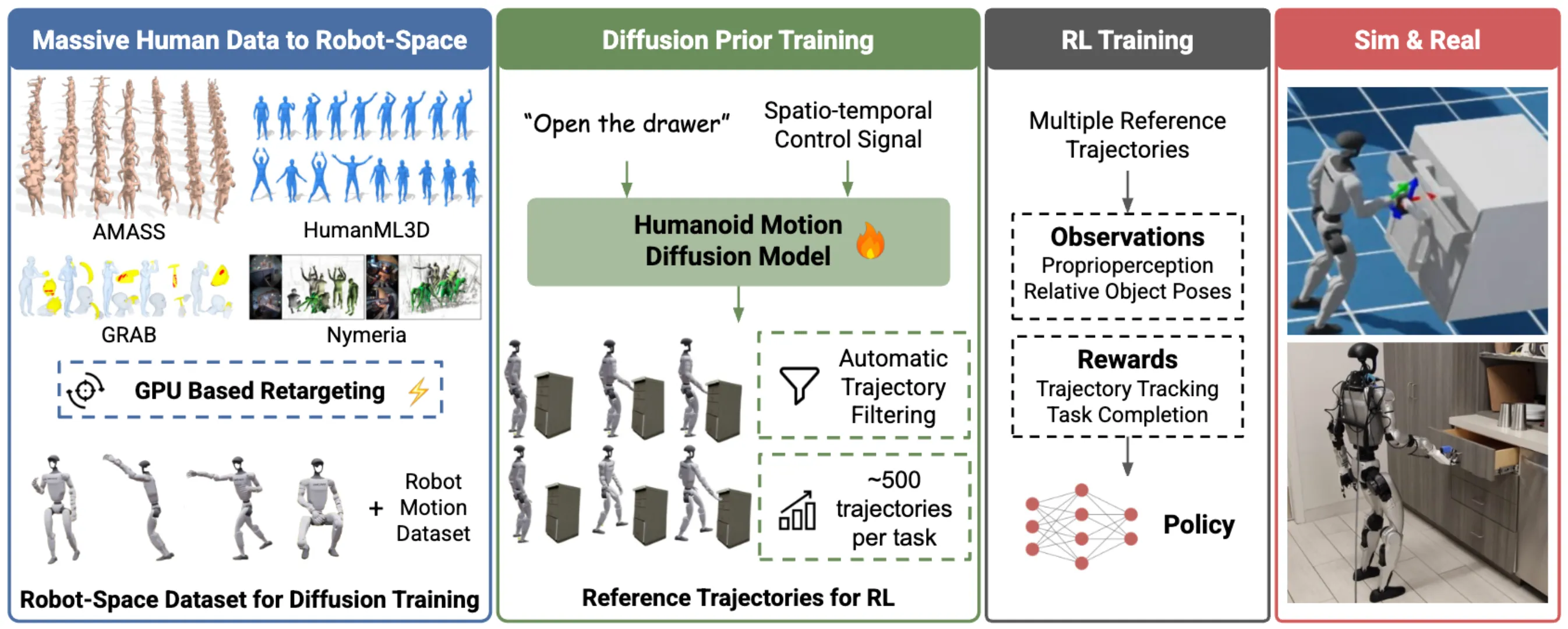
除此之外还有一些 Learning Based 或者间接的方案:
| 论文 | 主要贡献 |
|---|---|
| DreamControl-v2 | 基于 retarget 之后的数据集训练 Diffusion 模型生成参考轨迹,之后从轨迹进行 RL sim-to-real |
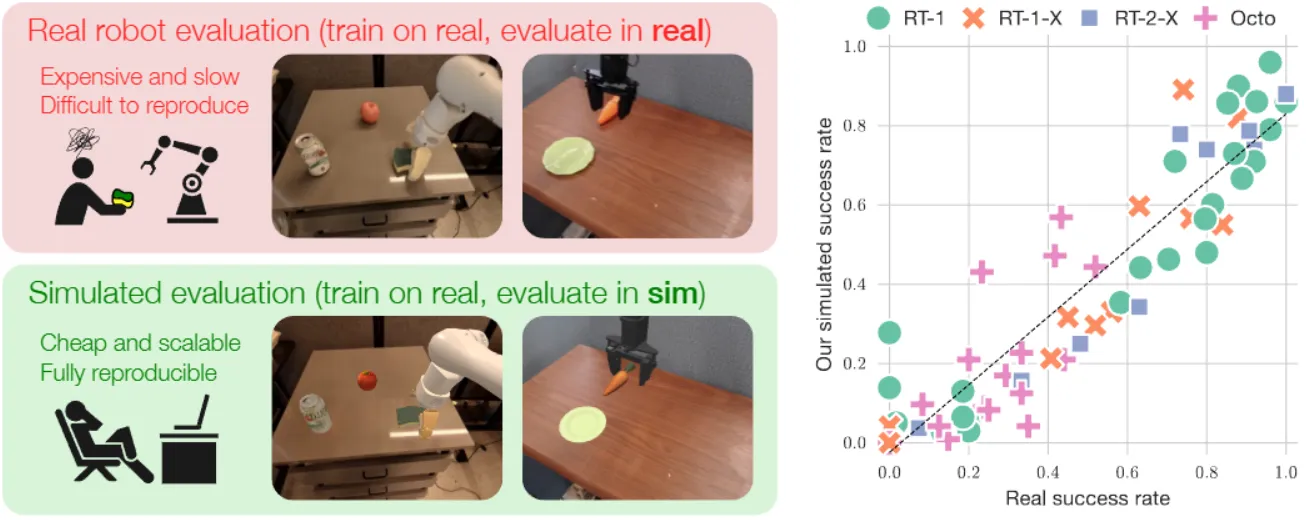
Benchmark#
了解 VLA 的常见测评,也是了解 VLA 发展以及学界和业界目前对于 VLA 期望的一个途径,在这里列举常见的 Benchmark 以及各自的侧重点:
| 论文 | 主要贡献 |
|---|---|
| LIBERO | 基于 Mujoco,因为数据集分布,难度有限,包含部分动作组合的任务 |
| LIBERO-Plus | 加入物体布局、相机视角、机器人初始状态、语言指令、光照条件、背景纹理以及传感器噪声等维度扰动的 LIBERO |
| Simpler-Env | 基于 Sapien,复刻 OXE 部分场景,数据集为 Real Data,良好的 Sim 调校并且大量实验验证 Sim-Real 一致性 |
| RoboCasa-GR1 | 基于 RoboSuite 的人形上半身桌面操作 Benchmark,Nvidia 随 GR00t 一同出品 |
| RoboChallenge | Real World Benchmark,使用四种不同的本体,不同的任务,随机化有限 |
| WorldArena | 在具身场景下对于 World Model 的测试,以及包括作为 Data Engine 以及 Simulator 等能力的测试 |
| UMI-Bench 1.0 | 在 UMI 数据上训练的真机 Benchmark |
| EBench | 高保真度、支持 Long Horizon / Mobile Manipulation / dexterous 以及多维度分析的 Isaac Sim Benchmark |
| RoboDojo | Generalization / Memory / Long-Horizon / Precision / 开放指令的 Isaac Sim Benchmark |



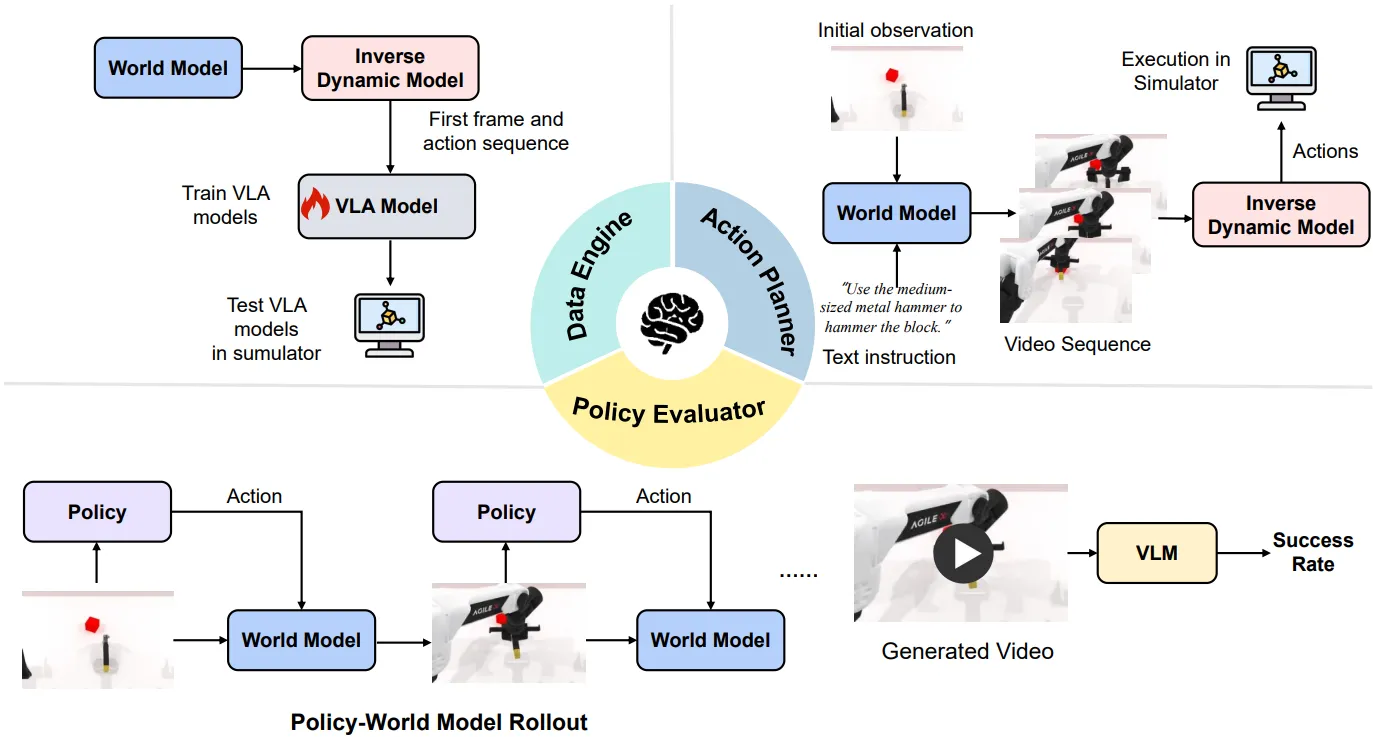



数据采集#
伴随着 VLA 的发展以及对于 Scaling 的需求,业界以及学界开始探索如何更好地 Leverage 异构的数据,如 Ego / UMI Data 等,一些改进通过 Training recipe 的调整,如更加 well-design 的课程学习完成,另外一些则通过如修改数据清洗流程或数据采集硬件展开,即从源头和末端解决异构数据混合训练的问题。
其中比较大规模且具有声望的是 EgoScale,采集了大量的 Ego Data,并且使用类似 GR00t 的结构进行了预训练,具有还可以的效果。
机器人数据集#
在这里汇聚一些常见的机器人数据集。
| 论文 | 主要贡献 |
|---|---|
| Open X-Embodiment | 多家机构的整合跨本体机器人数据集 |
| Open-H-Embodiment | 多家机构的整合跨本体医疗机器人数据集,作为天然具有数据飞轮但是伦理难度高的领域,未来可期 |

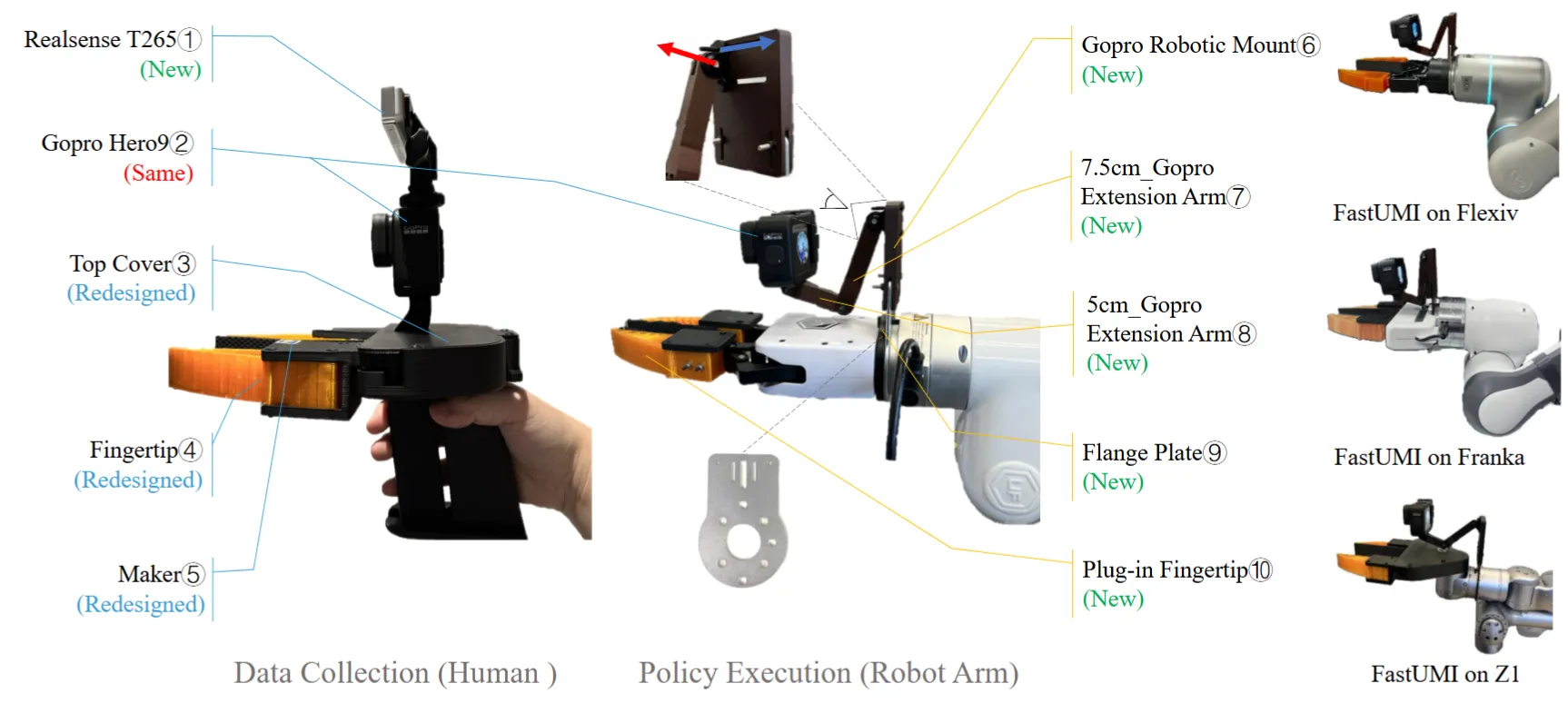
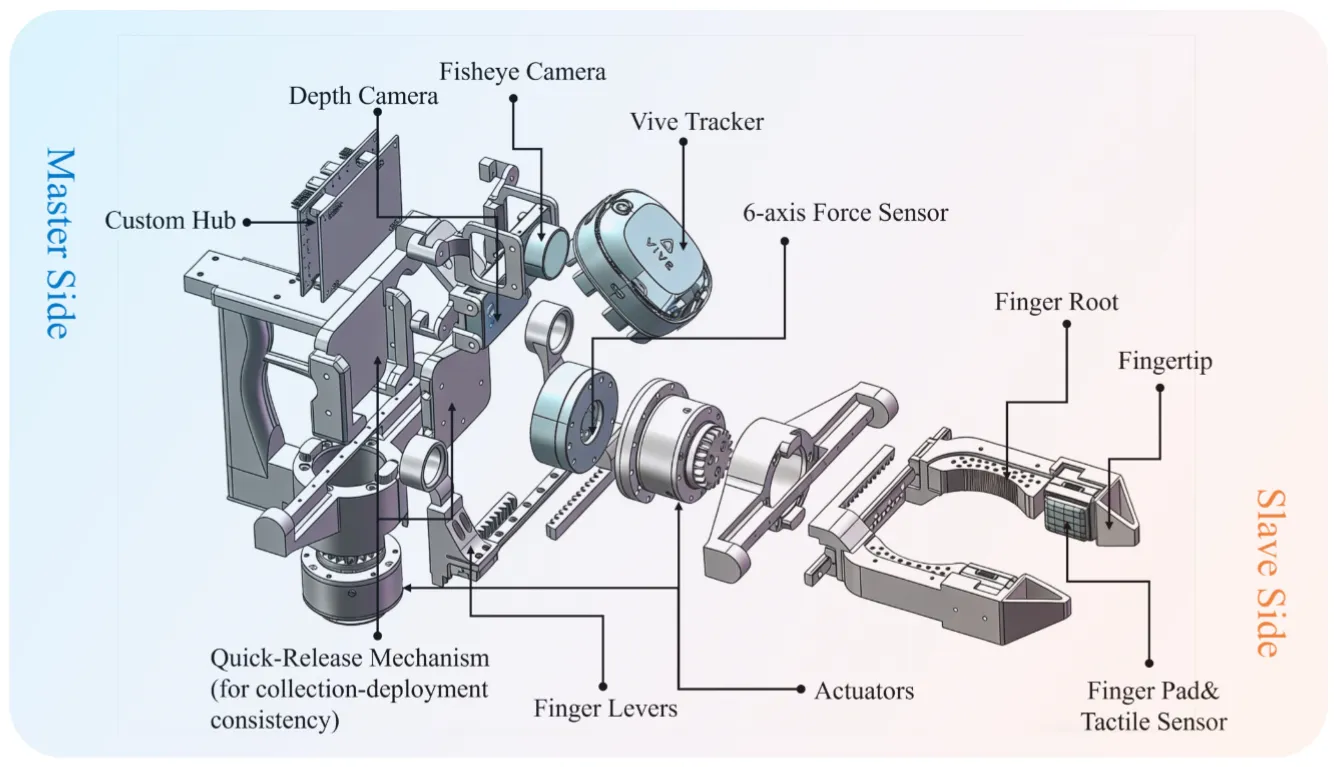
UMI#
UMI,即 Universal Manipulation Interface,是指使用一种特殊夹爪,通过 IMU 获得传感数据来决定动作,并且包含鱼眼镜头等,一方面可以替换不同本体,在跨本体时迁移,一方面可以使得人类手持 UMI 也可以参加数据,即进一步加快数据飞轮。和 UMI 相关工作主要以硬件的设计以及算法的优化为主,在这里进行一些统计。

| 论文 | 主要贡献 |
|---|---|
| FastUMI | 对 UMI 实现的工程优化 |
| DexUMI | 同构手套 + SAM 抠图的灵巧手 UMI |
| OmniUMI | 多模态 UMI,包括深度与力觉等 |

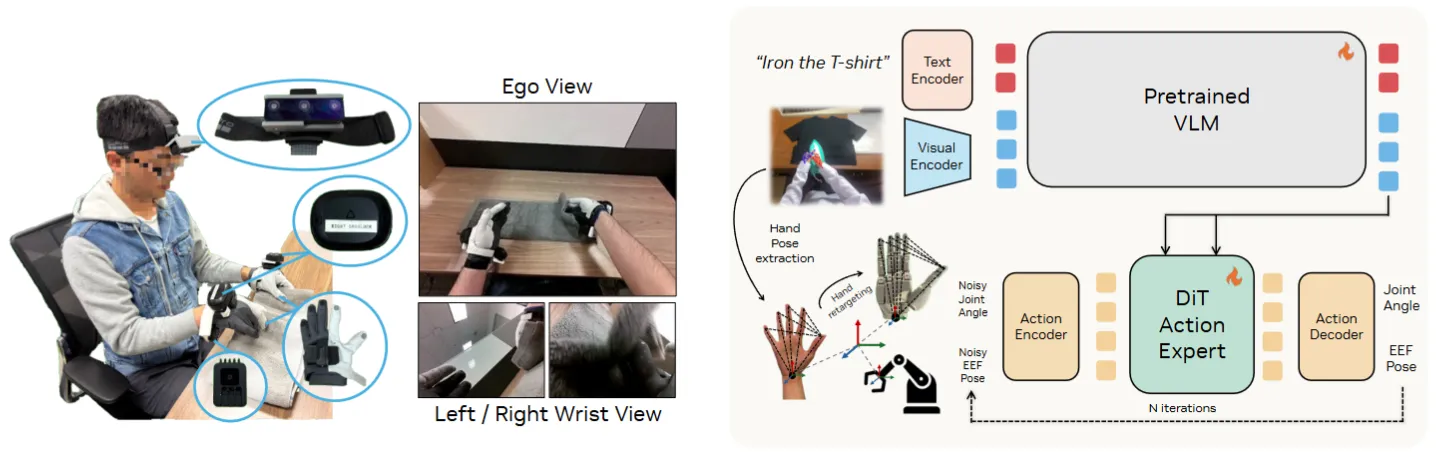
Ego Data#
Ego Data,即 Ego-centric Data,主要指人类采集的第一视角视频数据,一般作为 World Model 训练数据,或者在进行 retarget 以及标注之后作为 VLA 训练数据使用。
| 论文 | 主要贡献 |
|---|---|
| EgoVerse | 多源 Ego Data,本身训练使用正常的 Co-training 范式 |
| EgoLive | JD 出品的 Ego Data,以及一套清洗与标注流程 |
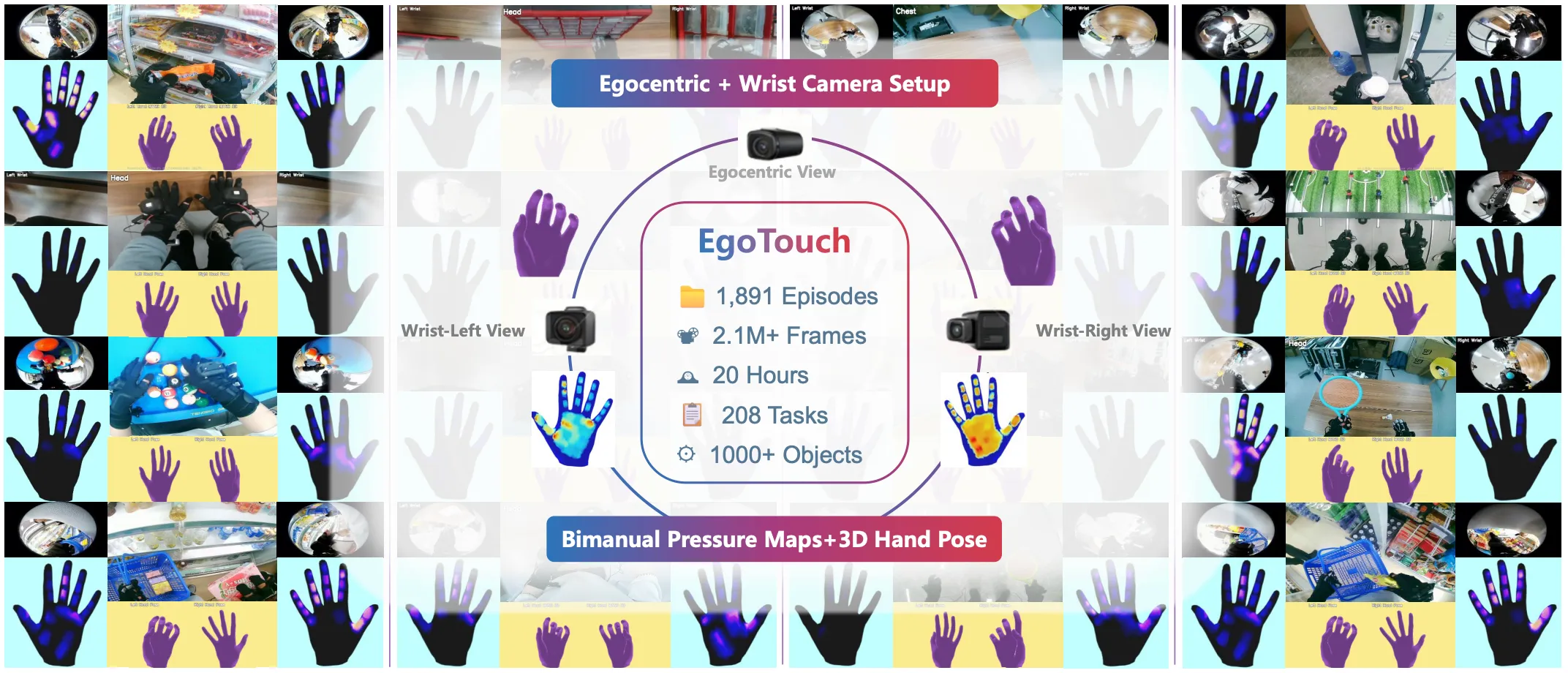
| EgoTouch | 哈工深出品的 Ego Data 并且包含手部触觉数据 |
| EgoInfinity | 大规模 Ego Data 以及一套处理管线 |
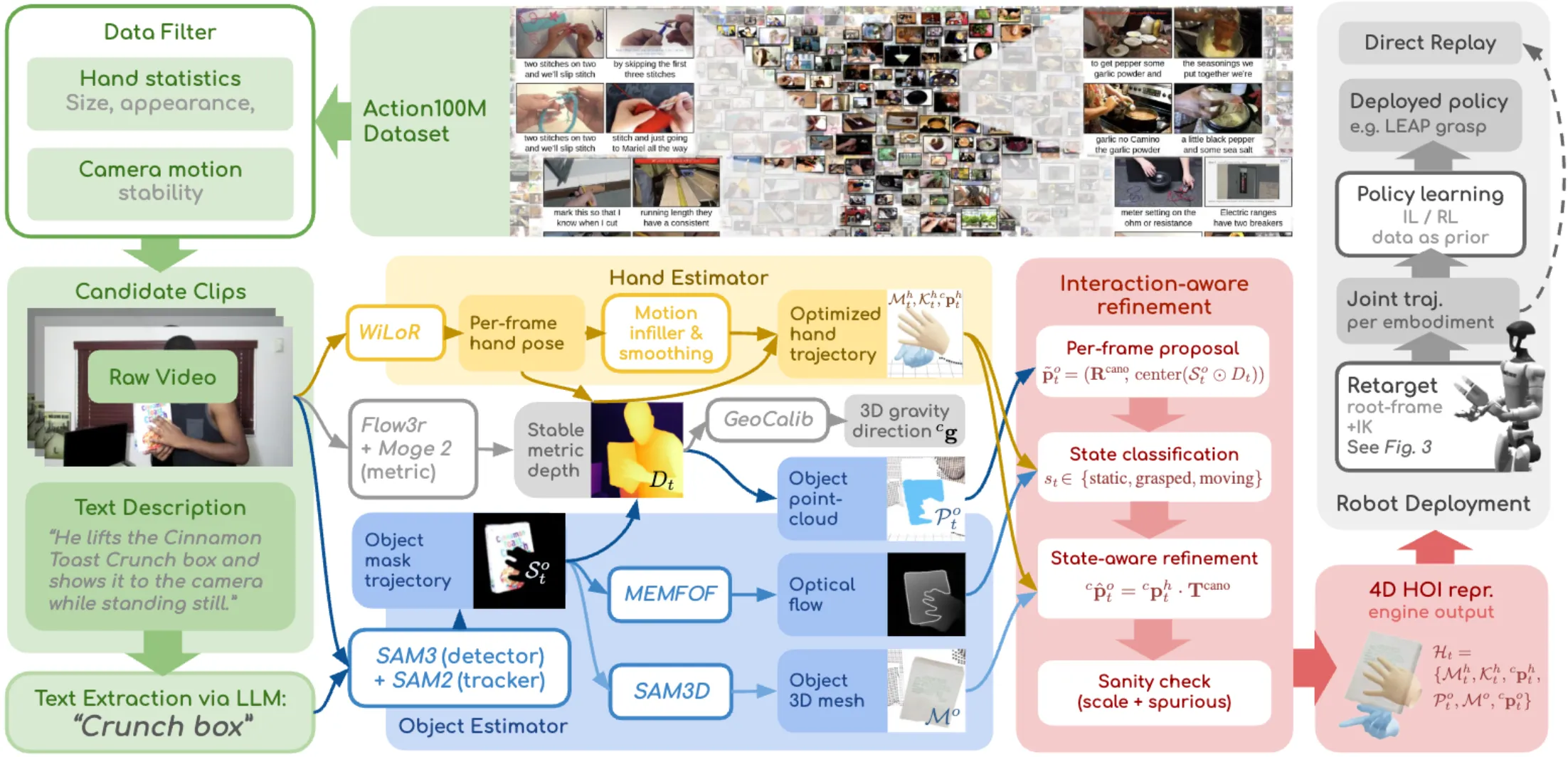
| EgoSteer | 大规模 Ego Data 以及一套处理管线,可用于灵巧操作 |
| Open-AoE | 大规模手机第一视角数据以及一套视频到训练的工具链 |



仿真合成数据#
使用仿真器合成数据一直是具身领域中认为的可行 Scaling 方案,尽管伴随着 Sim to Real 的 gap,但是在图形学技术的发展过程中,无论是效率还是 photorealistic 程度都是在不断提升,依然是一个未来可期的方向。
本身较早且具有代表性的工作当属 MimicGen,以及以其为基础搭建的 RoboCasa,通过人类遥操作数据,记录为 Object Centic 的轨迹数据,并且进行分割,这样在之后 randomize 物体位置之后,也可以通过拼接以及坐标变化,以及对于更长程任务可以由子动作进行排列组合,达到操作的效果,从而大量 Scaling 数据。
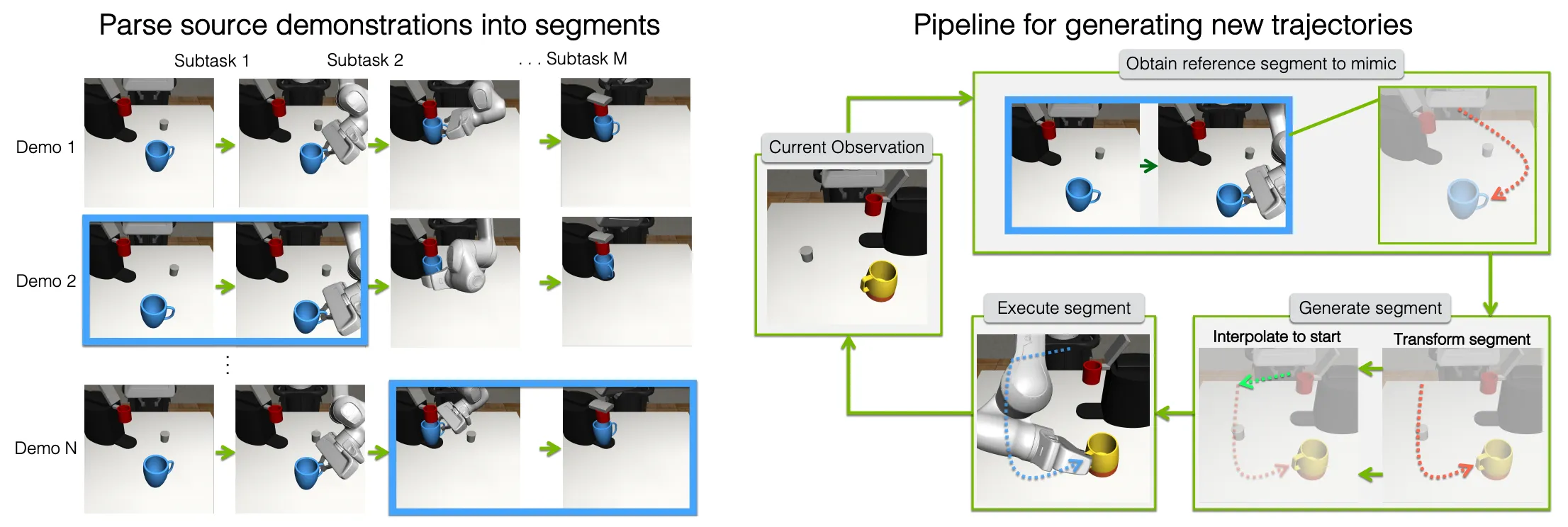
同样具有代表的工作如下列举:
| 论文 | 主要贡献 |
|---|---|
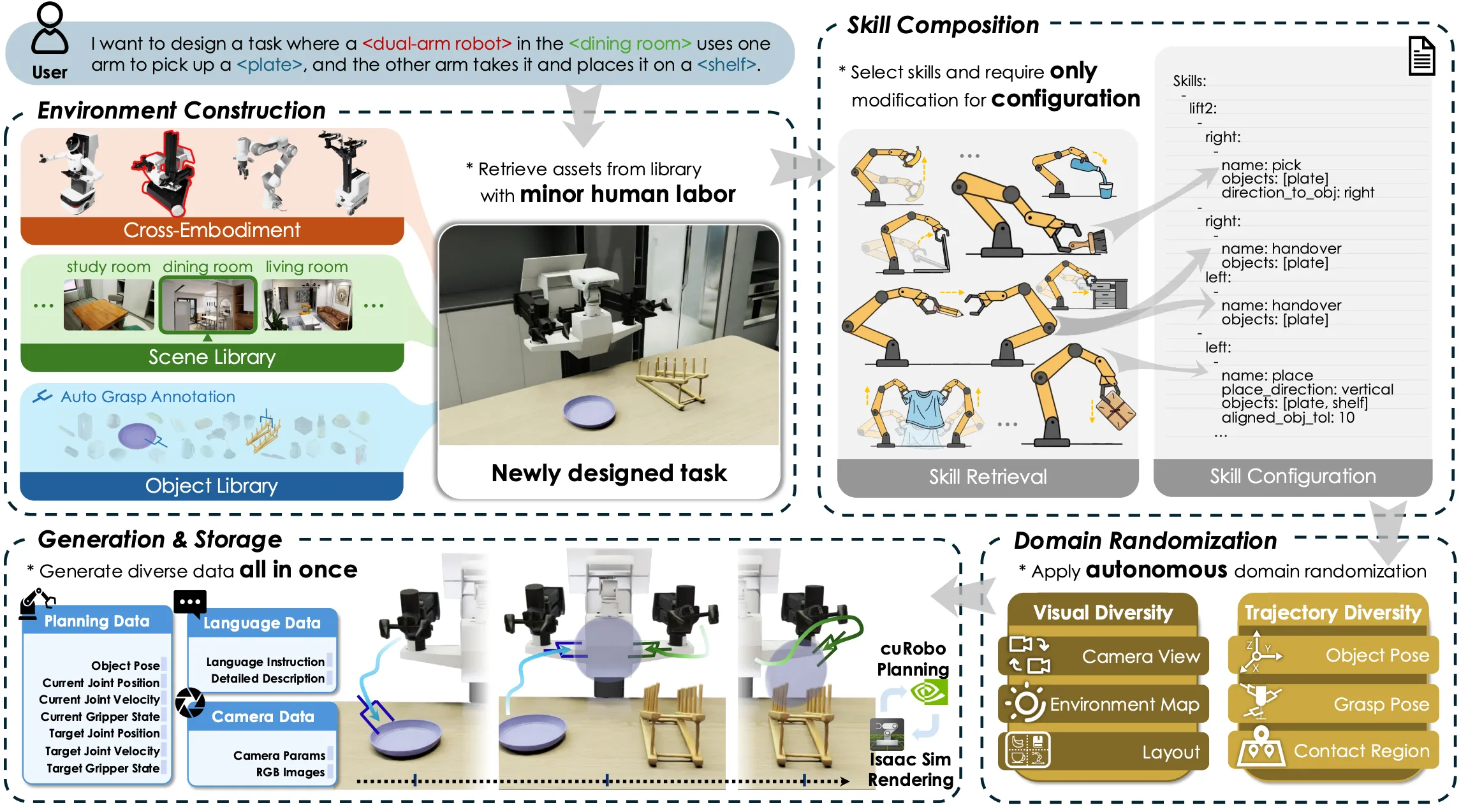
| InternVLA-M1 | 仿真数据合成部分,基于 GenManip,Scaling 大量 rich annotation diverse data |
| InternData-A1 | 多 Skill 大规模仿真数据合成 |
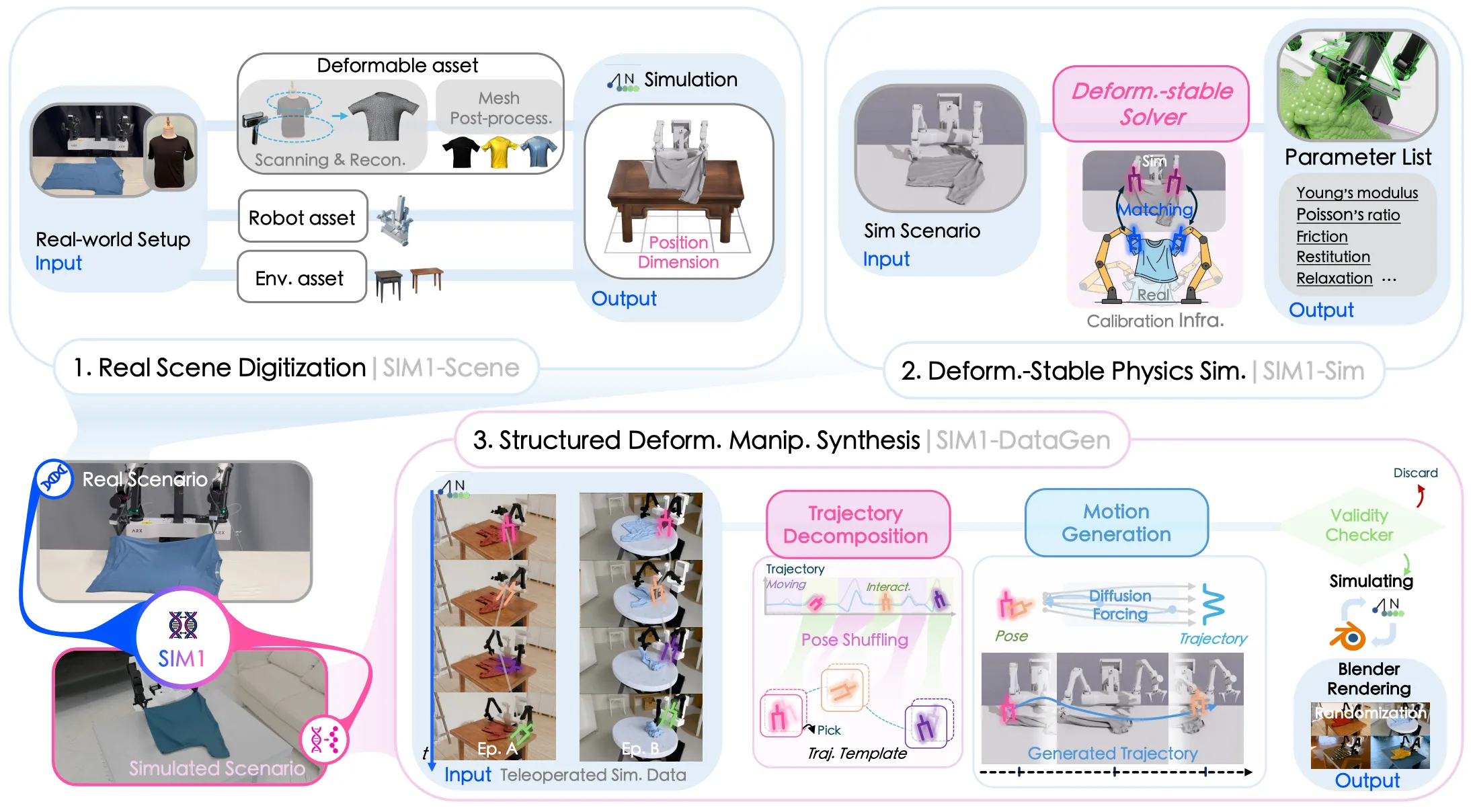
| Sim1 | 使用 Newton + Blender 合成叠衣服数据 |