

前言
平时遇到一些奇怪的代码问题,记录并整理,内容如下:
博客渲染超时
在 Hugo 中,如果博客文章较多,渲染时间会非常长,导致渲染超时。具体考量可能是因为担心无限递归之类的,hugo 使用了粗暴的解决方法,超时就中断并且报错。所以解决方法也很简单,修改 config.toml 文件中的 timeout 配置项,增加渲染超时时间,单位貌似是毫秒。之前一直没有看 Github 详细报错,之前又出现过 Github Actions 瘫痪,我还以为又出现了,re-run 之后也就好了,估计是因为当初体量卡在临界点上,现在彻底超时了,也就发现了这个问题。
CUDA & CUDNN & Pytorch 安装
因为之前的 Ubuntu 系统又因为我自己的不小心所以坏掉了,于是又一次尝试重装系统,但是出现了很多的问题。
我的系统是 Ubuntu 20.04.6,在清华大学镜像站下载的最新版,电脑显卡是 NVIDIA GeForce RTX 3070 Laptop,可以支持 CUDA 12.2,在本段内容书写的时候,Torch 的官网使用的最标准的 pytorch 是 CUDA 12.1 的,所以安装这个版本,以及 9.3.0 的 CUDNN。
首先给出下载 CUDA 和 CUDNN 的官网,其中 CUDA 12.1 为 https://developer.nvidia.com/cuda-12-1-0-download-archive,CUDNN 9.3.0 为 https://developer.nvidia.com/cudnn-downloads,之后依次选择自己的系统版本即可。其中 CUDA 的安装方法使用的是 runfile (local),并且在此之前运行了 sudo ubuntu-drivers autoinstall 并重启以安装 driver。
问题出现在,对于任何一个全新的最小安装的 Ubuntu 20.04 系统,在使用 runfile 的时候,均会报错,并说明在 /var/log/nvidia-installer.log 中可以看到详情,为:
-> Error.
ERROR: An error occurred while performing the step: "Checking to see whether the nvidia kernel module was successfully built". See /var/log/nvidia-installer.log for details.
-> The command `cd ./kernel; /usr/bin/make -k -j16 NV_EXCLUDE_KERNEL_MODULES="" SYSSRC="/lib/modules/5.15.0-117-generic/build" SYSOUT="/lib/modules/5.15.0-117-generic/build" NV_KERNEL_MODULES="nvidia"` failed with the following output:
make[1]: Entering directory '/usr/src/linux-headers-5.15.0-117-generic'
warning: the compiler differs from the one used to build the kernel
The kernel was built by: gcc (Ubuntu 9.4.0-1ubuntu1~20.04.2) 9.4.0
You are using: cc (Ubuntu 9.4.0-1ubuntu1~20.04.2) 9.4.0
MODPOST /tmp/selfgz3405/NVIDIA-Linux-x86_64-530.30.02/kernel/Module.symvers
ERROR: modpost: GPL-incompatible module nvidia.ko uses GPL-only symbol 'rcu_read_unlock_strict'
make[2]: *** [scripts/Makefile.modpost:133: /tmp/selfgz3405/NVIDIA-Linux-x86_64-530.30.02/kernel/Module.symvers] Error 1
make[2]: *** Deleting file '/tmp/selfgz3405/NVIDIA-Linux-x86_64-530.30.02/kernel/Module.symvers'
make[2]: Target '__modpost' not remade because of errors.
make[1]: *** [Makefile:1830: modules] Error 2
make[1]: Leaving directory '/usr/src/linux-headers-5.15.0-117-generic'
make: *** [Makefile:82: modules] Error 2
ERROR: The nvidia kernel module was not created.
ERROR: Installation has failed. Please see the file '/var/log/nvidia-installer.log' for details. You may find suggestions on fixing installation problems in the README available on the Linux driver download page at www.nvidia.com.经过检查,发现问题其实很简单,是因为 g++ 等版本为 9,太高了,设置为 7 即可。
sudo apt-get install gcc-7 g++-7
sudo update-alternatives --install /usr/bin/gcc gcc /usr/bin/gcc-7 9
sudo update-alternatives --install /usr/bin/gcc gcc /usr/bin/gcc-9 1
sudo update-alternatives --display gcc
sudo update-alternatives --install /usr/bin/g++ g++ /usr/bin/g++-7 9
sudo update-alternatives --install /usr/bin/g++ g++ /usr/bin/g++-9 1
sudo update-alternatives --display g++之后再次运行,获得输出:
===========
= Summary =
===========
Driver: Not Selected
Toolkit: Installed in /usr/local/cuda-12.1/
Please make sure that
- PATH includes /usr/local/cuda-12.1/bin
- LD_LIBRARY_PATH includes /usr/local/cuda-12.1/lib64, or, add /usr/local/cuda-12.1/lib64 to /etc/ld.so.conf and run ldconfig as root
To uninstall the CUDA Toolkit, run cuda-uninstaller in /usr/local/cuda-12.1/bin
***WARNING: Incomplete installation! This installation did not install the CUDA Driver. A driver of version at least 530.00 is required for CUDA 12.1 functionality to work.
To install the driver using this installer, run the following command, replacing <CudaInstaller> with the name of this run file:
sudo <CudaInstaller>.run --silent --driver
Logfile is /var/log/cuda-installer.log设置环境变量:
sudo vim ~/.bashrc # or ~/.zshrc之后在最后添加:
export PATH=/usr/local/cuda-12.1/bin${PATH:+:${PATH}}
export LD_LIBRARY_PATH=/usr/local/cuda-12.1/lib64\
${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}}之后再 source 一下:
source ~/.bashrc # or ~/.zshrc就可以正常的使用 CUDA 了:
nvcc --version输出为:
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2023 NVIDIA Corporation
Built on Tue_Feb__7_19:32:13_PST_2023
Cuda compilation tools, release 12.1, V12.1.66
Build cuda_12.1.r12.1/compiler.32415258_0之后的 CUDNN 以及 torch 的安装就是按照提供的正常流程进行,完结撒花。
全部的指令包括以下内容:
sudo apt update
sudo apt upgrade
sudo ubuntu-drivers autoinstall
reboot
sudo apt-get install gcc-7 g++-7
sudo update-alternatives --install /usr/bin/gcc gcc /usr/bin/gcc-7 9
sudo update-alternatives --install /usr/bin/gcc gcc /usr/bin/gcc-9 1
sudo update-alternatives --display gcc
sudo update-alternatives --install /usr/bin/g++ g++ /usr/bin/g++-7 9
sudo update-alternatives --install /usr/bin/g++ g++ /usr/bin/g++-9 1
sudo update-alternatives --display g++
wget https://developer.download.nvidia.com/compute/cuda/12.1.0/local_installers/cuda_12.1.0_530.30.02_linux.run
sudo sh cuda_12.1.0_530.30.02_linux.run
sudo vim ~/.bashrc # or ~/.zshrc
### add following in .bashrc ###
export PATH=/usr/local/cuda-12.1/bin${PATH:+:${PATH}}
export LD_LIBRARY_PATH=/usr/local/cuda-12.1/lib64\
${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}}
################################
source ~/.bashrc # or ~/.zshrc
wget https://developer.download.nvidia.com/compute/cudnn/9.3.0/local_installers/cudnn-local-repo-ubuntu2004-9.3.0_1.0-1_amd64.deb
sudo dpkg -i cudnn-local-repo-ubuntu2004-9.3.0_1.0-1_amd64.deb
sudo cp /var/cudnn-local-repo-ubuntu2004-9.3.0/cudnn-*-keyring.gpg /usr/share/keyrings/
sudo apt-get update
sudo apt-get -y install cudnn
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh
./Miniconda3-latest-Linux-x86_64.sh
conda create -n torch python=3.8
conda activate torch
pip3 install torch torchvision torchaudio之后在 python 中 torch.cuda.is_available() 返回为 true。
Ubuntu 22.04 三系统安装以及安装显卡驱动后无线网卡恢复
因为 Ubuntu 20.04 的若干的内容已经不再支持,使用起来最新的一些软件基本上全是报错,比较经典的就是 GLIBC 2.3.1 以及 libssl.so.3 等内容,而前者的安装十分的麻烦,所以干脆直接安装三系统。
三系统的安装不是很困难,将新创建的 EFI 分区作为引导器就好(理论来说,全部的系统都可以使用同一个 EFI 分区,但是我之前安装的时候,当时太过于稚嫩,胡乱操作出现过问题,现在不太敢尝试,所以没有踩过坑,在这里不作为介绍的方法),之后在系统的 GRUB 界面就可以看到三个系统了。
一个常见的问题在于,如何切换 Grub。比如说我之前已经给我的 Ubuntu 20.04 的 Grub 安装了一个主题,而安装了新的系统之后,这个 Grub 会被新系统的 Grub 覆盖掉,那么应该如何处理呢。
假如说按照上述的方法,那么你在进入系统的时候其实是可以看到自己的之前的系统的,进入之前的系统之后,可以运行:
sudo update-grub
lsblk
# 输出中可以找到 MOUNTPOINTS 为 /boot/efi 的项,记住其 NAME
sudo grub-install /dev/nvme0n1p1 # 以 nvme0n1p1 为例之后重启即可。
Ubuntu 22.04 有一个比较经典的问题,就是安装显卡驱动之后,会导致无线网卡消失,按照正常的流程进行操作之后,运行 sudo ubuntu-drivers autoinstall 并且重启,再次进入默认的系统之后,就会发现网卡消失了。
再次重启,进入 GRUB 之后选择 Advanced options for ubuntu,进去之后可以看到两个 Ubuntu 的版本以及对应的两个 recovery mode。两个版本里面比较新的一个是在安装显卡驱动之后新安装的版本,可以理解为显卡驱动对于较高版本的内核具有依赖,但是配套的无线没有一起安装,记下来两个版本的型号,然后选择较低版本的内核(不是 recovery mode)进入。
进入这一内核之后,可以发现网卡是有的,但是使用 nvidia-smi,并没有正常的那个输出界面,因为这个系统中内核不满足显卡驱动的依赖,那么把这个系统的版本提上去就好了。
使用 sudo dpkg --get-selection | grep linux 可以看到一些信息,其中一些项目包含版本号,有新版本的版本号,以及旧版本的,记下来这些旧版本的,并且使用 sudo apt install 安装使用新版本号覆盖旧版本号的这些内容。本人安装内容如下,作为参考:
sudo apt install linux-headers-6.8.0-40-generic linux-image-6.8.0-40-generic linux-modules-6.8.0-40-generic linux-modules-extra-6.8.0-40-generic再次重启,正常进入正常的系统,恢复。
需要注意的是,越早设置这些内容,与本文档的对齐程度最高,本人的安装流程为,正常安装系统(将全部硬盘空间都挂在在 / 下)并设置语言为中文,进入系统之后更换语言为英文(因为不然的话输入法的安装比较麻烦),重启,将文件夹变为英文名,再重启,连接网络,sudo apt update 以及 sudo apt upgrade,最后就开始安装显卡驱动 sudo ubuntu-drivers autoinstall 并 reboot 重启。
GPT API 调用显示 Unknown scheme for proxy URL
在使用 GPT API 的时候,正常的发送 request,显示:
GPT API 报错信息
ValueError: Unable to determine SOCKS version from socks://127.0.0.1:7890/但是此时我已经将全部的代理关闭了,更不要说后续要需要开启代理才可以连接 https://api.openai.com/v1,经过检查之后,大概是因为自己的网络环境太过于乱七八糟:
env | grep -i proxy可以查看到究竟是哪个环境出现了问题,之后正常使用 bash 或者 python 程序都可以进行修改,本人是发现 ALL_PROXY 出现问题:
unset ALL_PROXY
unset all_proxy
env | grep -i proxy
export ALL_PROXY="http://127.0.0.1:7890"
export all_proxy="http://127.0.0.1:7890"import os
os.environ['ALL_PROXY'] = 'http://127.0.0.1:7890'
os.environ['all_proxy'] = 'http://127.0.0.1:7890'重点其实在于找到哪个有问题,并且进行覆盖,unset 是严谨起见,其实无所谓。
AnyGrasp 配置踩坑
最近正在配置 AnyGrasp,在这里记录一下遇到的问题。我的环境为 Ubuntu 22.04, CUDA 12.1, cudnn 9.3.0。
INFO信息
之前其实写过一版,但是感觉不是很详细,至少照着看是不能无痛安装的,所以说换了一个新的,并且重新写一下。
首先先给出 AnyGrasp 的 Github 仓库链接:https://github.com/graspnet/anygrasp_sdk,其中的 Installation 部分给出了简略的安装步骤,但是因为其依赖的 MinkowskiEngine 已经年久失修,所以需要一些额外的操作。
先配置一个 conda 环境:
conda create -n anygrasp python=3.10
conda install openblas-devel -c anaconda
pip install torch 'numpy<1.23' ninja接下来可以开始配置第一步,也就是 MinkowskiEngine:
git clone https://github.com/NVIDIA/MinkowskiEngine.git
cd MinkowskiEngine根据经验来说,需要配置以下的环境变量:
export CXX=c++
export CUDA_HOME=/usr/local/cuda-12.1
export MAX_JOBS=2
export SKLEARN_ALLOW_DEPRECATED_SKLEARN_PACKAGE_INSTALL=True其中后两者,MAX_JOBS 是 CUDA: Out of memory 的 Issue,SKLEARN_ALLOW_DEPRECATED_SKLEARN_PACKAGE_INSTALL=True 是 sklearn 过期的 Issue。假如说之后执行安装操作:
python setup.py install --blas_include_dirs=${CONDA_PREFIX}/include --blas=openblas首先可能存在的报错,核心问题为 error: namespace "thrust" has no member "device",本质上还是年久失修,和 CUDA 12.X 不兼容了。
根据仓库里的 Issue#543 可以找到对于我适用的方法,即在四个不同的文件中添加 #include:
// src/convolution_kernel.cuh
#include <thrust/execution_policy.h>// src/coordinate_map_gpu.cu
#include <thrust/unique.h>
#include <thrust/remove.h>// src/spmm.cu
#include <thrust/execution_policy.h>
#include <thrust/reduce.h>
#include <thrust/sort.h>// src/3rdparty/concurrent_unordered_map.cuh
#include <thrust/execution_policy.h>之后可能会有报错 ModuleNotFoundError: No module named 'distutils.msvccompiler',那么执行 pip install "setuptools <65"。
之后再次安装,也会有报错:
Traceback (most recent call last):
File "/home/gaoning/miniconda3/envs/anygrasp/lib/python3.10/site-packages/torch/utils/cpp_extension.py", line 2105, in _run_ninja_build
subprocess.run(
File "/home/gaoning/miniconda3/envs/anygrasp/lib/python3.10/subprocess.py", line 526, in run
raise CalledProcessError(retcode, process.args,
subprocess.CalledProcessError: Command '['ninja', '-v', '-j', '2']' returned non-zero exit status 1.可以编辑 setup.py:
setup(
name="MinkowskiEngine",
version=find_version("MinkowskiEngine", "__init__.py"),
install_requires=["torch", "numpy"],
packages=["MinkowskiEngine", "MinkowskiEngine.utils", "MinkowskiEngine.modules"],
package_dir={"MinkowskiEngine": "./MinkowskiEngine"},
ext_modules=ext_modules,
include_dirs=[str(SRC_PATH), str(SRC_PATH / "3rdparty"), *include_dirs],
cmdclass={"build_ext": BuildExtension.with_options(use_ninja=False)},
author="Christopher Choy",
author_email="chrischoy@ai.stanford.edu",
...,
)将 use_ninja 设置为 False,之后再次执行,就没问题了。
之后安装 anygrasp_sdk:
git clone https://github.com/graspnet/anygrasp_sdk.git
cd anygrasp_sdk
pip install -r requirements.txt之后安装 pointnet2:
cd pointnet2
python setup.py install值得一提的是,在安装 pointnet2 的过程中依然可能出现 Command '['ninja', '-v', '-j', '2']' 的报错,解决方法同上,依然是修改 setup.py 中的 setup() 函数的传参。
在这一过程中还可能出现一个比较罕见的问题:
gcc: fatal error: cannot execute ‘cc1plus’: execvp: No such file or directory
compilation terminated.
error: command '/usr/bin/gcc' failed with exit code 1一般来说直接 sudo apt install build-essential 就已经可以了,但是我的问题不止于此,因为系统里的 gcc 和 g++ 都没问题。检查之后发现,这是因为 pointnet2 的编译过程中涉及了使用 gcc 并且调用 g++ 的操作,而 gcc 大概率调用同版本的 g++,可能是因为 gcc --version 和 g++ --version 两个的版本不一样,所以就导致了这个问题。使用指定版本的 sudo apt install 进行重新安装(版本在 Ubuntu 22.04 可以是 12):
sudo apt install gcc-12 g++-12之后正常安装即可。
最后是使用 AnyGrasp 需要 Key,而这个 Key 需要生成,因此需要使用 ./license_checker -f,而因为 Ubuntu 22.04,这个也会报错,一个是缺少 libcrypto.so.1.1,一个是 sh: 1: ifconfig: not found。
# to solve libcrypto.so.1.1 issue
find / -name libcrypto.so.1.1
# for example found a libcrypto.so.1.1 from cuda
sudo ln -s /usr/local/cuda-12.1/nsight-systems-2023.1.2/host-linux-x64/libcrypto.so.1.1 /usr/lib/libcrypto.so.1.1
# to solve ifconfig issue
sudo apt install net-tools同时运行 ./lincense_checker -f 之后输出的机器码,大概率最后以 % 结尾,这个因为在输出的时候没有添加换行提示符(Python 的 print() 自带换行符,而写这个程序的编程语言有可能不带),提交不包含 % 的内容到申请表中即可,另,邮箱需要使用教育邮箱。
Ubuntu22.04 搜狗输入法无法输出中文
众所周知,在 Ubuntu 系统中,假如说在安装的时候选择了中文作为语言(一般来说我在写教程的时候会推荐这么做,之后再把中文换回英文,而把输入法留下来),那么你的电脑中会包含一个 Ubuntu 的默认的输入法,然而不说这个输入法不是很符合中国人的说话习惯,其也很难根据你的打字来学习你的打字习惯。一般来说唯一的解决方案就是使用搜狗输入法。
具体的方法如下:
前往 搜狗输入法的官网 并且下载 Linux个人版,这时候就会开始下载搜狗输入法的 .deb 包,并且进入搜狗输入法的教程界面。然而虽然说一般情况下这个教程是好用的,但是在 Ubuntu 22.04 的时候,或许需要额外进行一些操作,以下从头来讲。
首先需要安装 fcitx:
sudo apt install fcitx之后进入设置中的区域和语言(Region & Language),选择 Manage Installed Languages,在 Keyboard input method system 中选择 Fcitx 4。当然,假如说你本身没有配置过中文,需要先在 Install/Remove Languages 中选择简体中文并且点击 Apply:


之后再安装一些依赖并且删除 ibus。
sudo apt install libqt5qml5 libqt5quick5 libqt5quickwidgets5 qml-module-qtquick2
sudo apt install libgsettings-qt1
sudo apt remove --purge ibus之后 reboot 重启电脑,应该就会出现搜狗输入法了。假如没有的话,点击输入法,选择 配置 或者 Configure,添加点击加号并且搜索搜狗输入法(sogoupinyin)进行添加。保险起见,可以把别的输入法都按一遍减号来删除。
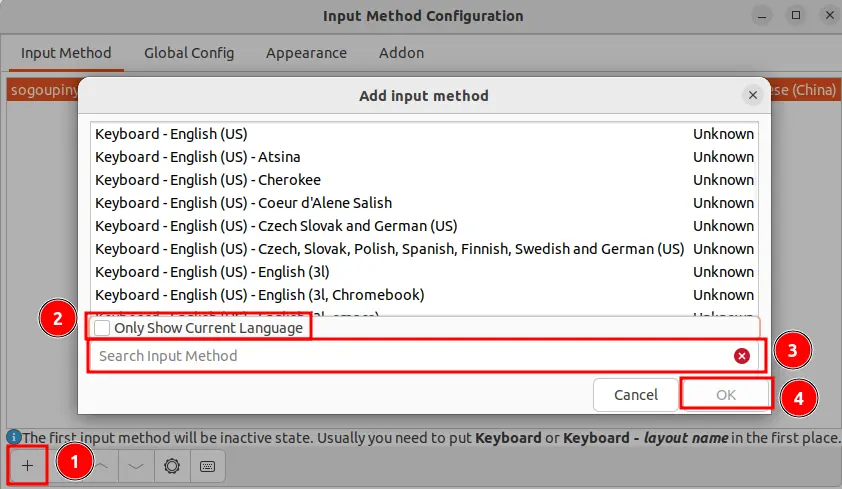
此时搜狗输入法就安装好了。其中主要的坑在于,安装依赖并且删除 ibus 这一步骤,在 搜狗输入法自己的教程 中没有给出。