
Paper Reading: Embodied AI 4
从一些 Embodied AI 相关工作中扫过。
4D-VLA#
Memory Bank + 4D 信息的 VLA
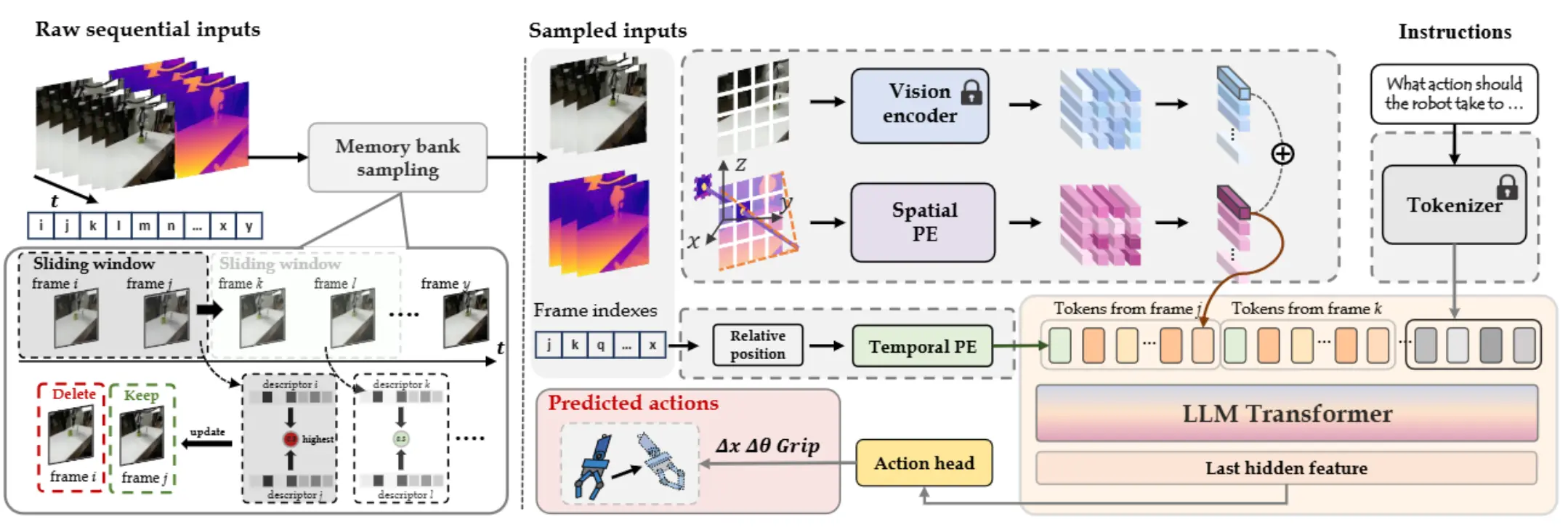
4D-VLA 本身的 VLM 主干是 InternVL-4B,使用投影到世界或者机器人坐标系下对齐的深度图以及视觉图一起编码成 Visual token 输入 VLM,之后后面接一个 Action head。
其中 4D 的体现就是使用了 Memory Bank,这个 Bank 里面采样出来的帧之间的区别要尽可能大,这个思想也比较好理解,毕竟需要保证输入给模型的帧需要有尽可能大的信息量,自然需要差异。本身各种设计都还算挺有意思的。4D-VLA 里面另一个关键,也就是其中的 3D 部分,通过将深度图提供给 VLM 来表征三维信息,则是一个需要思考的话题。本身深度图是否要提供给 VLM 一直是一个有争议的问题,因为新训练的 Visual Encoder 需要 VLM 经过一定的 pre/post-train 去适应,以及进行对齐,而在这些训练过程中,则可能以损失模型本身的泛化能力为代价。从结果上来看,貌似这篇只和 OpenVLA 进行了比较,不知道带来的增益能否抵消这种适应带来的难度。
D(R,O) Grasp#
使用 DexHand 与 Object 的距离作为一种表征的 DexGrasp
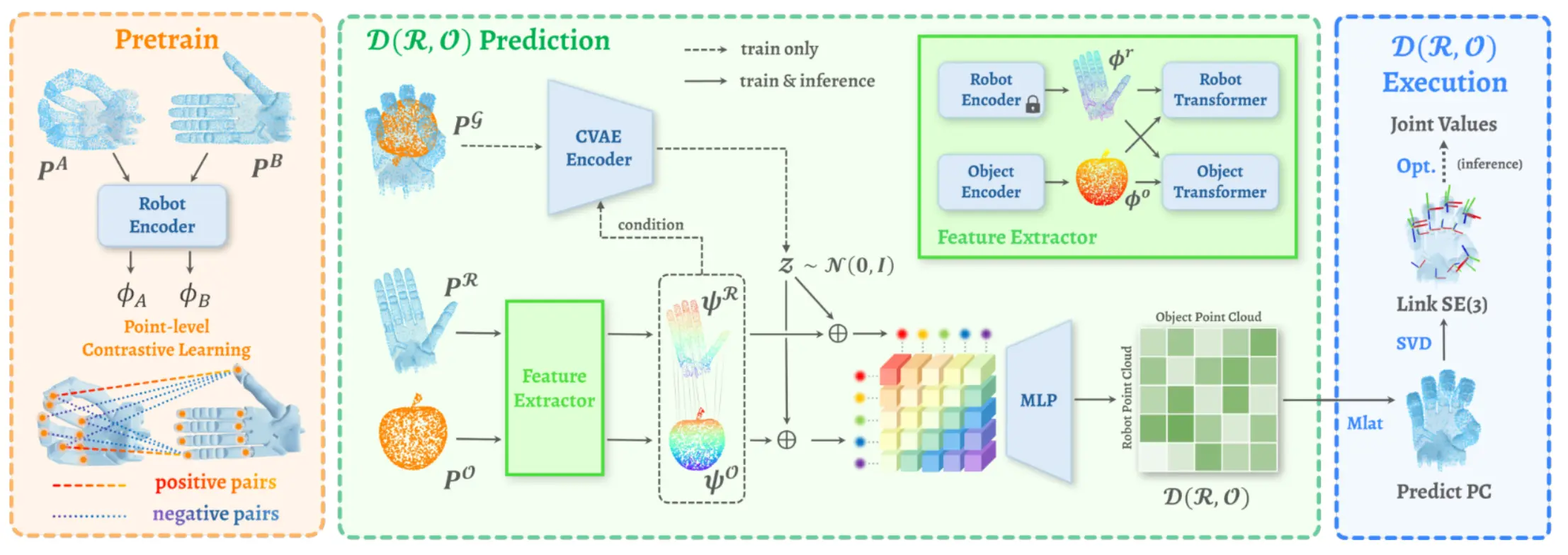
D(R,O) Grasp 提取灵巧手以及物体的点云的 Feature,然后用 CVAE 预测距离矩阵,然后进行优化,因为优化可以并行,所以性能很高也很快。
InstructVLA#
双阶段训练的 MOE 的 VLA
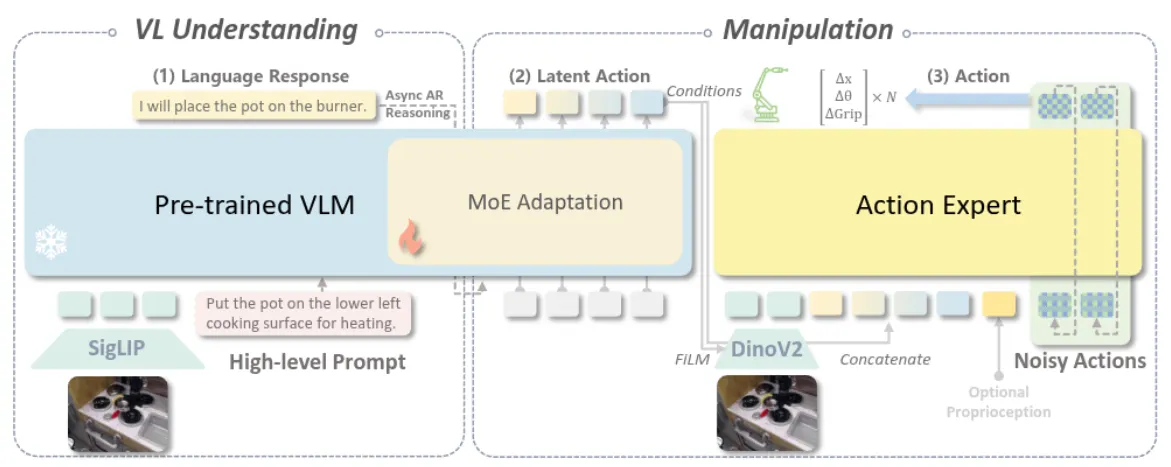
InstructVLA 本身还是 pi-like 的架构,其中 VLM 是一个 MOE,两个阶段去训练,使用了构建的大量的数据。
本质上 InstructVLA 强调了多 Stage 的训练,第一阶段直接进行动作数据的预训练,这部分在文章的 setting 下也就是使用了 OXE,然后第二阶段冻结 DP,梯度回传到 VLM,去训练 MOE 以及 LoRA。InstructVLA 是近期开始讲 Generalist 故事的论文之一,是否有必要将模型的多模态泛化能力完全在 VLA 中保持,这一点依然是个问号。
包括 InstructVLA 在内的一系列模型证明了训练 in-domain 的推理任务,可以在推理内容上从泛化角度具有一定的外拓,也就是训练了 将猩猩爱吃的食物(香蕉)放到盘子里 之后大概率可以泛化到 将海边比较常见的热带水果(椰子)放到盘子里。结果上来看,InstructVLA 也具有一定的 zero-shot 能力,还算是令人印象深刻。
Fast-in-Slow#
快慢系统 VLA
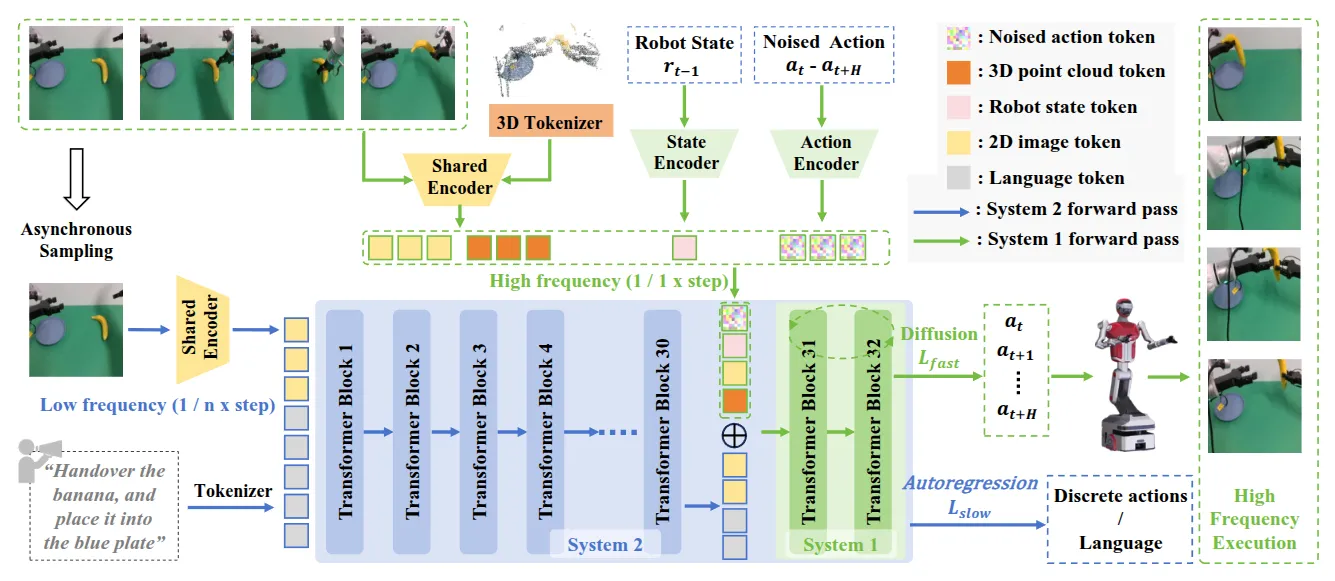
FiS-VLA 算是比较意料之中的架构,一个 VLM 作为慢系统,本身 AR 输出 Language,然后一个 DP 作为快系统,Vision Encoder 的输出和 VLM 的输出 concat 并且作为 DP 的 condition。
这里面有意思的一点在于,这种架构说明在 DP 中确实可以引入异步,DP 比 VLM 快一定的速度,而同时 DP 的 condition 也可以不只是 VLM 的输出,也可以和别的内容 concat 在一起,也就给加入诸如 3D Encoder 了空间。毕竟从第一性原理考量,VLA 需要 VLM 的能力越多越好,那么就尽量不要修改 VLM 的结构,也就不能在 VLM 的前面加入 3D Encoder,那么当整体的模型希望引入更多的 perception 能力的时候,一个合理的设计自然也就是在 DP 中加入新的 embedding 进行 concat 了。
NavDP#
DP + 轨迹选择
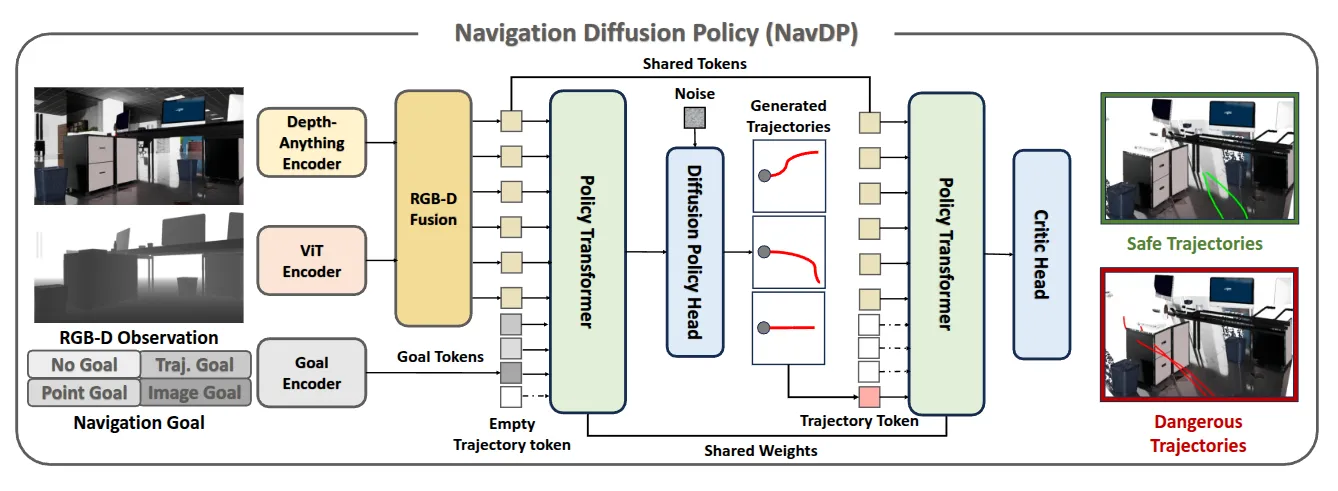
第一次读 Navigation 的论文,还挺有意思的。
NavDP 本身就是 Transformer 去 Fusion Goal 和 Observation,Observation 本身是 RGB-D 的,然后之后的输出作为 DP 的 condition 来输出一个 chunk 的轨迹,之后轨迹用 1D Conv 压成 Trajectory token 再次输入到同一个 shared weight 的 Transformer 中,这次后面接一个 Critic 来选择轨迹。
这个导航以及对应的任务本身其实非常巧妙,本身感觉这种级别的 Navigation 是并不需要「脑子」,本质上任务是 2D Goal 或者视觉导航,而并没有语义理解的任务难度,作为一个导航领域的 foundation model,加上使用了大量的 simulation render 的数据,完全是 scalable 并且容易 work 的,确实不错,在 solid 的情况下可以成为一些方法的 base model。
总的来说,这篇工作我还是挺喜欢的,在 DP 的范式下做出了一些探索,而且都是必要的,并且证明了一定的 scalable,很好地在自己的 scope 中闭环了。
Nav#
双系统 Navigation
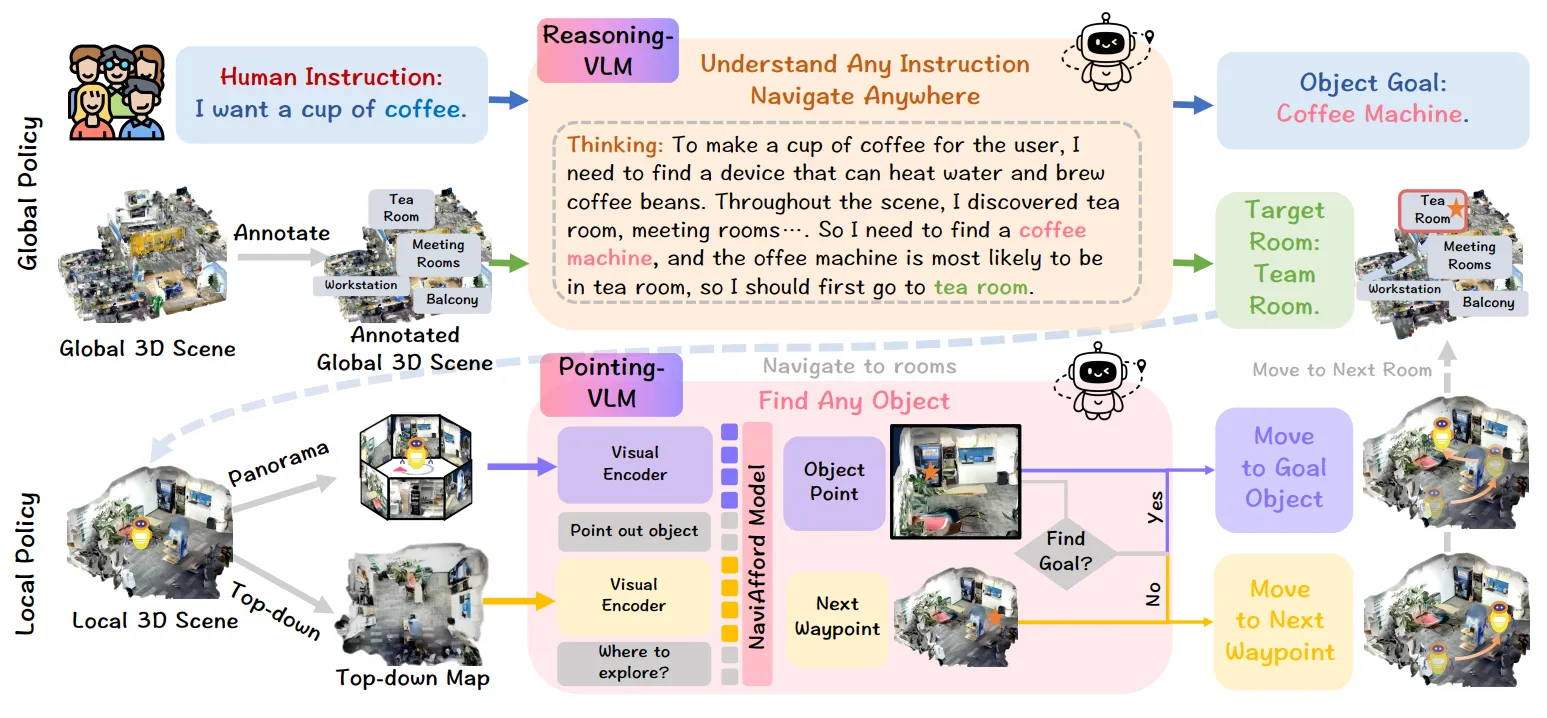
Nav 是导航中除了如 NavDP 这种 low-level 导航之外的另一种 topic,也就是进行 high-level 的 Navigation。
本身相较于 Manipulation,Navigation 的 System 2 从故事上是更加闭环的,毕竟从一开始 SLAM 开始,一个可以被证实的事情是,导航本身至少在 Local Map 中只需要进行 2D 的规划,并且如 NavDP 这种 policy-based 还是如直接基于点云进行避障,早在很久以前都是已经验证十分有效的方案了。这也就意味着对于 Navigation 的 System 2 来说,已经可以输出最终需要的信息了,也就是最多只有三个自由度的 2D Nav Goal (x, y, yaw)。
读者假如看了之前关于在 Manipulation 中引入 VLM 并且使用各种中间表征的 Paper reading,不难发现,对于 Manipulation 来说,这些表征确实是相对「中间」的,因为 Manipulation 最后的执行是使用 6 自由度的空间的 end-effector pose 进行。这对于模型来说要不然具有极大的难度,对于 VLM 几乎学不出来,要不然则少很多的信息(如 bounding box),或者具有歧义性(如 2D trajectory)。
因此作为一个相对「粗粒度」的任务来说,VLM 确实在导航中进行了很大程度的运用。
回到论文本身,Nav 的 System 2 是 VLM,System 1 也是 VLM 但是专门训练过 Affordance,因此本身只是构建了数据以及 System 来构建一个导航的 infra system,将不同的组件串联在了一起,这方面没有过多的 highlight。本身 Nav 似乎复用了 RoboBrain 的 Affordance 的训练数据,输出依然是 Point,并且具有了非常好的效果,之后通过 Point,可以变换到机器人坐标系下,并且进行正常的导航。
Genie Envisioner#
Video generation model 一气化三清为 Action model 和 simulation
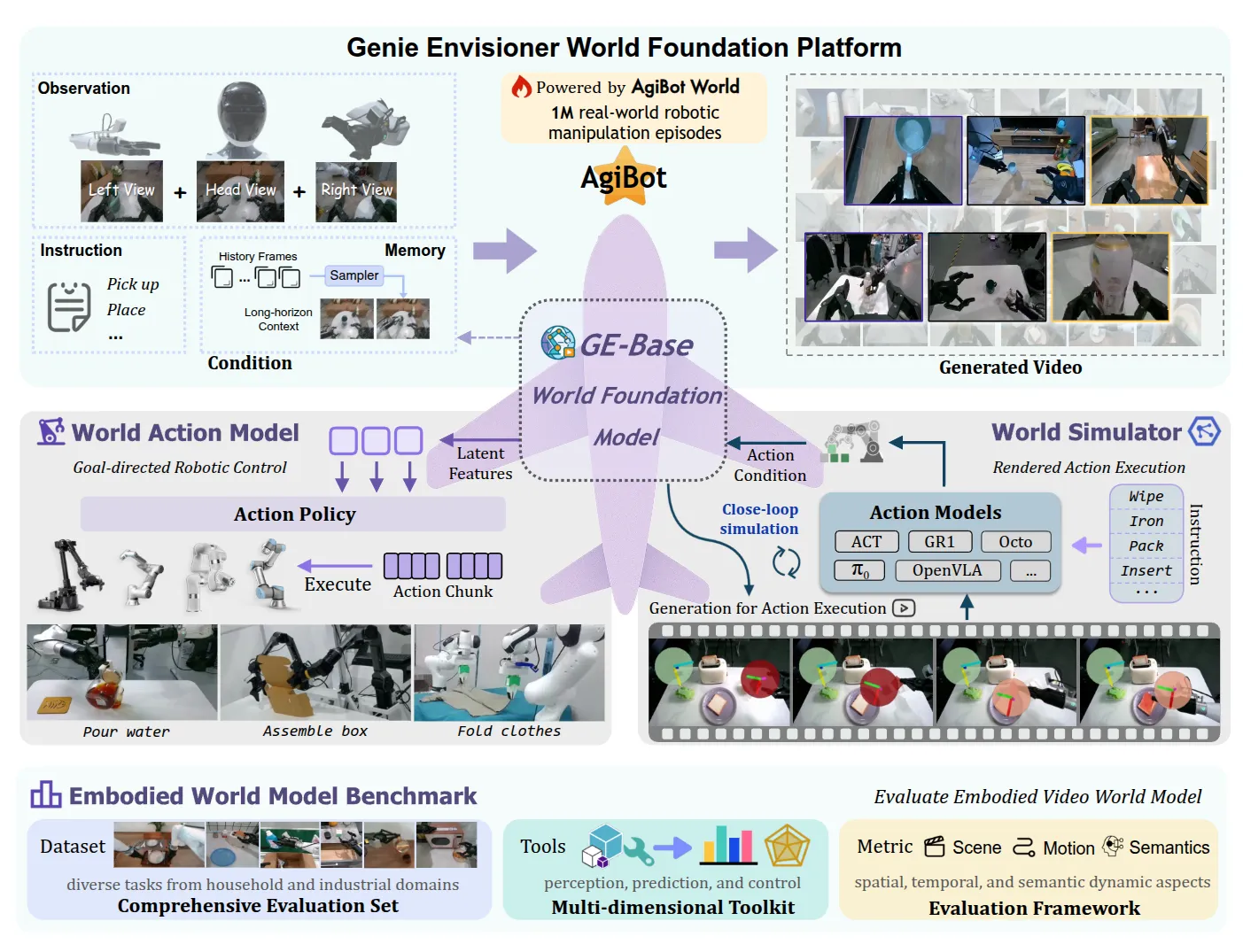
Genie Envisioner 本身是用 AgiBot 的数据训练了一个 video generation model,或者说 world model,称之为 GE-Base。
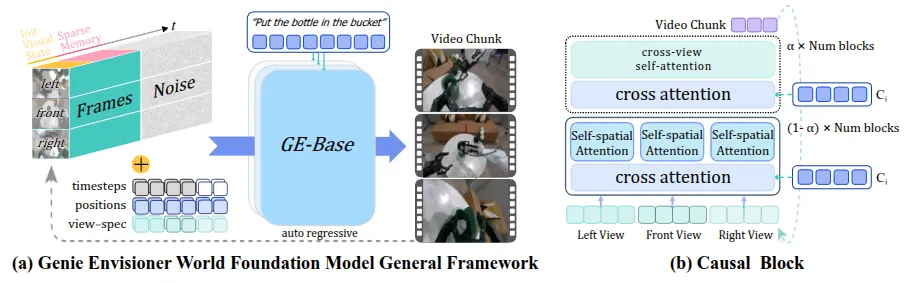
GE-Base模型本身就是经典的 DiT 设计,输入是三个视角的视频编码 token + 稀疏历史记忆 + 噪声图 + 文本嵌入,每次输出一个 video chuck。模型在 AgiBot 的数据上进行了预训练,作为了后续一系列设计的一个基石,这其中预训练包括两个环节,一个是在不同帧率的视频上预训练,之后为了对齐 Embodied 这边的频率,在 5Hz 的频率上进行了微调。
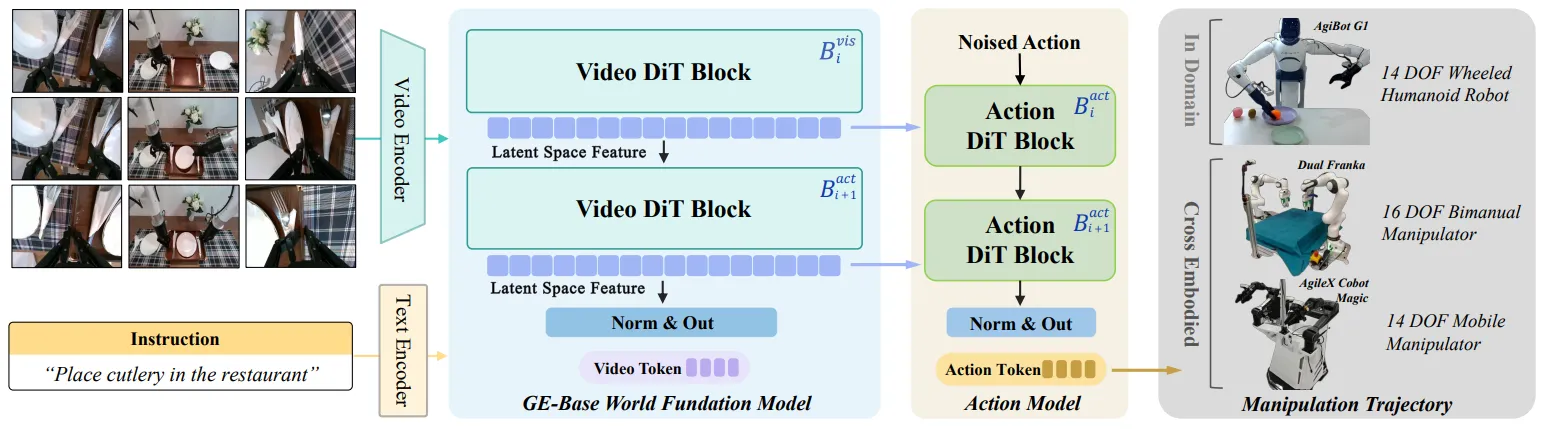
另一个设计是将 GE-Base 外接一个相同架构,但是 Hidden state 更小的模型,来改造成一个 Action model,这里就是直接将 hidden state 拿出来作为 Action policy 的 condition。
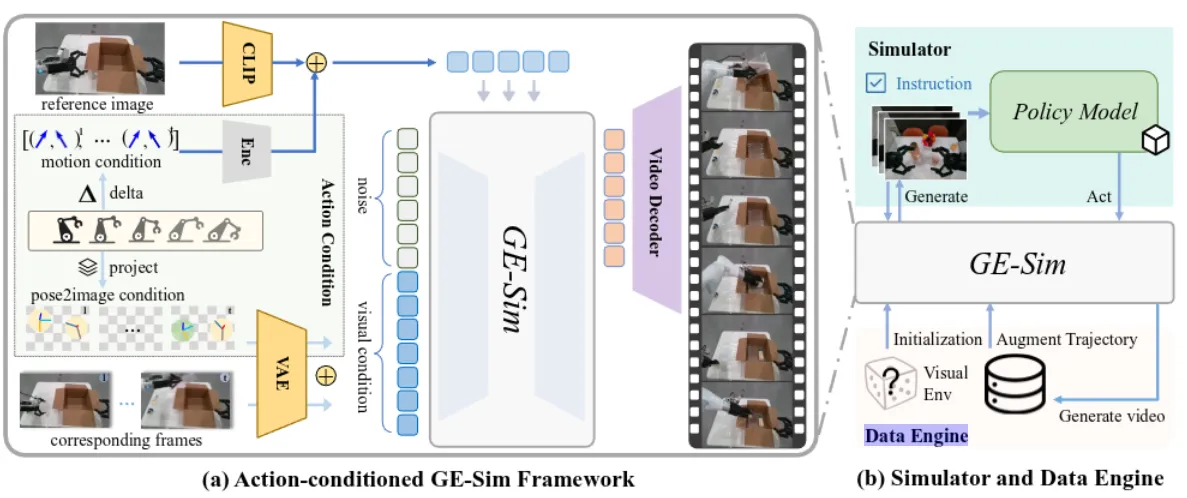
同时 GE-Base 也可以作为 World Model Simulator,也就是接受 Action condition 来输出视频,作为一个仿真器。
这篇工作本身一气化三清的思路非常有意思,也是充分在 Large scale 的 pre-training 之后充分运用了 world model 的潜力。
StreamVLN#
流式记忆模块的 VLM
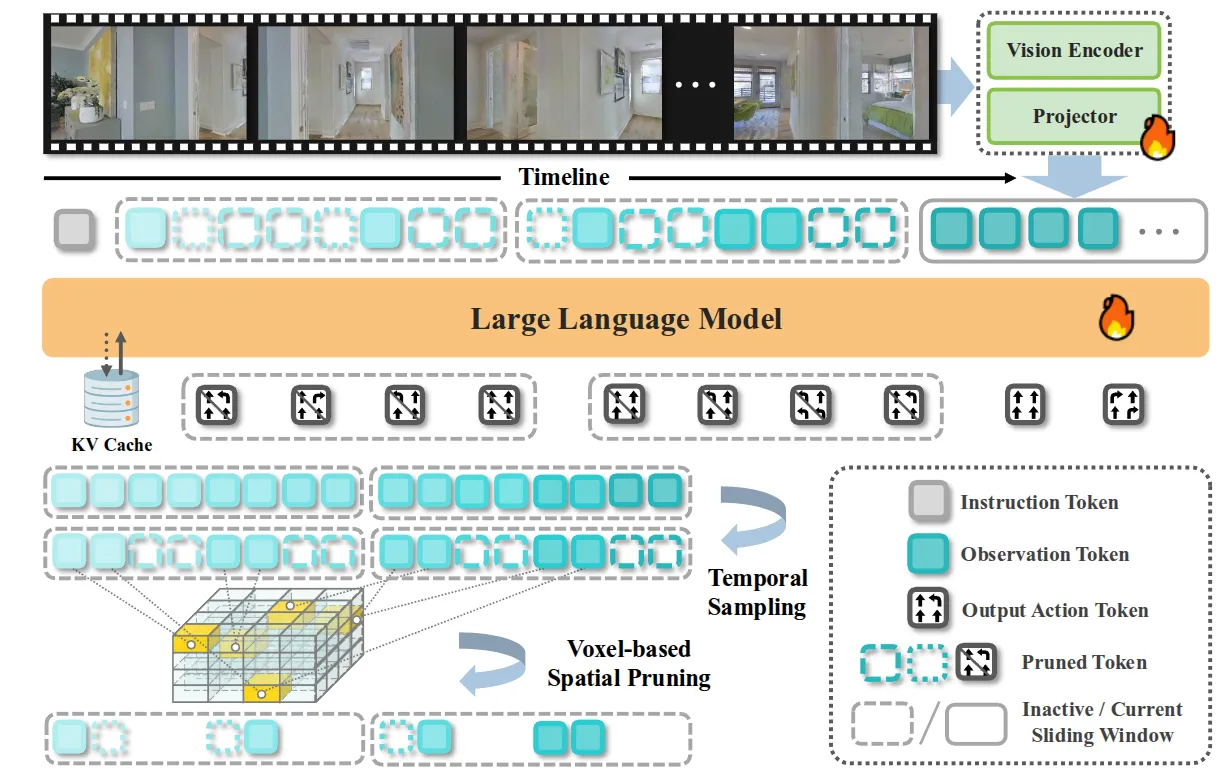
StreamVLN 本身算是如标题所示,也算是在 Navigation 这个任务中第一次引入这种 Memory bank,类比到 Manipulation 可能有点类似于 4D-VLA 里面的做法。本身模型就是使用 LLaVA-Video 的架构,然后进行连续的多轮自回归生成即可。同时引入了使用 KV-Cache 来进行加速,但是尽管进行了 KV-Cache 的复用,但是显存开销会随着历史长度的增加而线性增长,于是对于 KV-Cache 进行压缩,使用滑动窗口来缓存。同时对于记忆,把每一帧的图像 token 通过深度信息映射到 3D 空间,如果多个帧的 token 落在同一个体素里,就只保留最新的那个,来实现 Memory bank 的采样。
StreamVLN 从思路上还是比较有趣的,不同于 4D-VLA 的 Memory 思路,StreamVLN 的 Memory 看起来更加可解释,类似于每个区域都只能包括最新的记忆,通过 3D 的空间来描述。
V-JEPA 2#
自回归训练的 World Model,可以用于 Action model
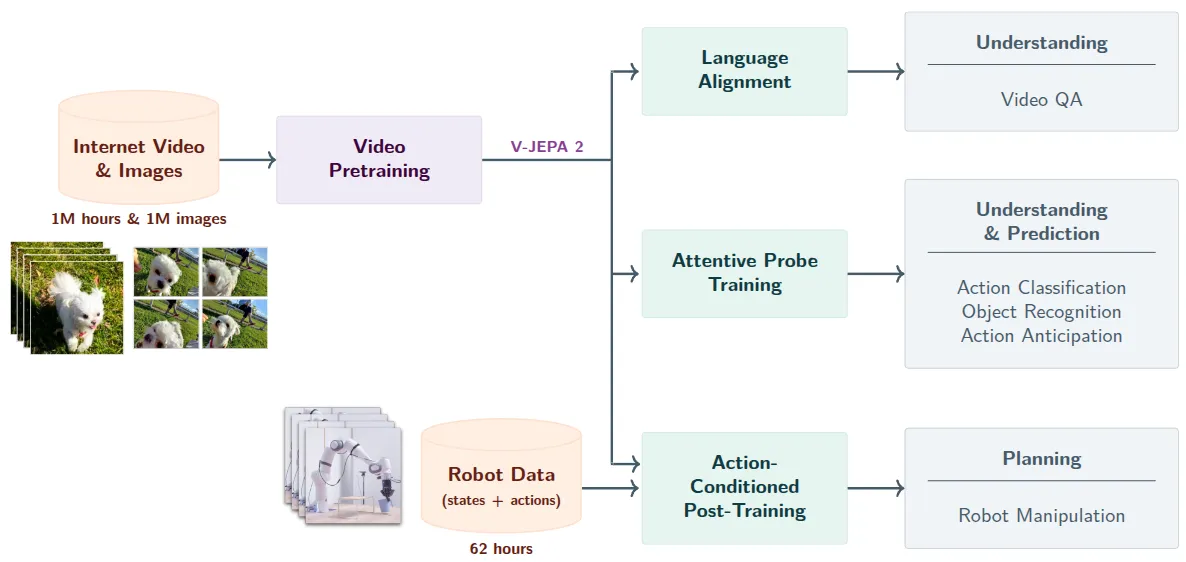
V-JEPA 2 是 LeCun 的新作,本身还是按照 LeCun 一直在说的 World Model 的范式,使用自回归的范式进行训练,并且在大量的预训练之后支持了图中的动作分类、目标识别、动作预测和视频问答系统等,同时也可以作为一个 action model 来使用。
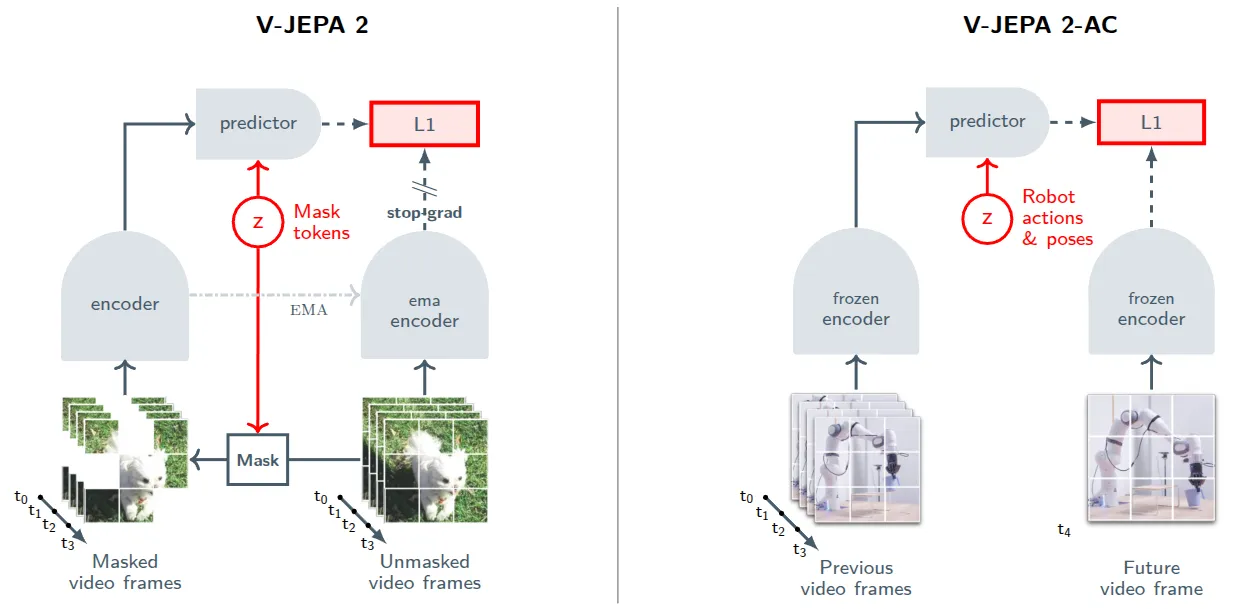
V-JEPA 2 本身本质上就是如图中左图的自回归范式,也就是将视频变为 token 之后,使用自回归的方式进行训练。如图中所示,其实本质上 V-JEPA 2 做的其实就是掩码降噪生成,也就是使用 DiT 的思路进行降噪。同时用停止梯度和 EMA 避免模型崩掉。模型本身都是 ViT 组成的。
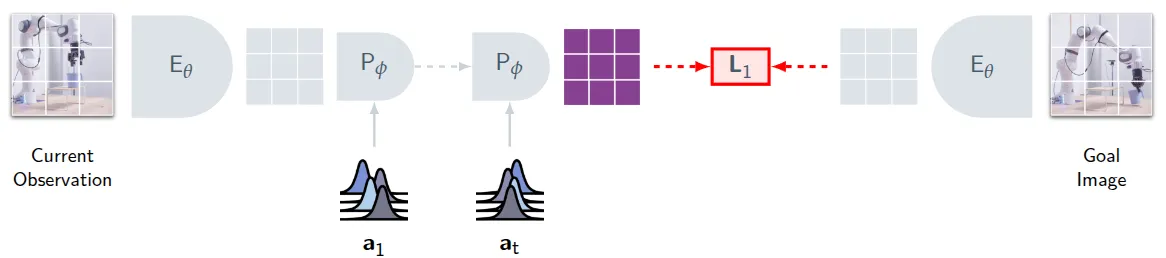
在此基础上,使用 V-JEPA 2 的 world model 做了 V-JEPA 2-AC,可以用于动作生成。这个本质上就是预测未来的 image,并且有一个可以以 Action 为 Condition 的 world model。本身在过程中就是使用交叉熵的方法来优化 action chunk,来确保此时的 action world model 的输出尽可能接近正常 world model 的输出。
V-JEPA 2 在运动视频中理解能力很强,并且里面其实很多诸如约束 Gaussian 分布的内容很讲究,建议读者品读。
MolmoAct#
OpenVLA-like 架构的 VLA 家族,引入动作推理数据进行 cotrain
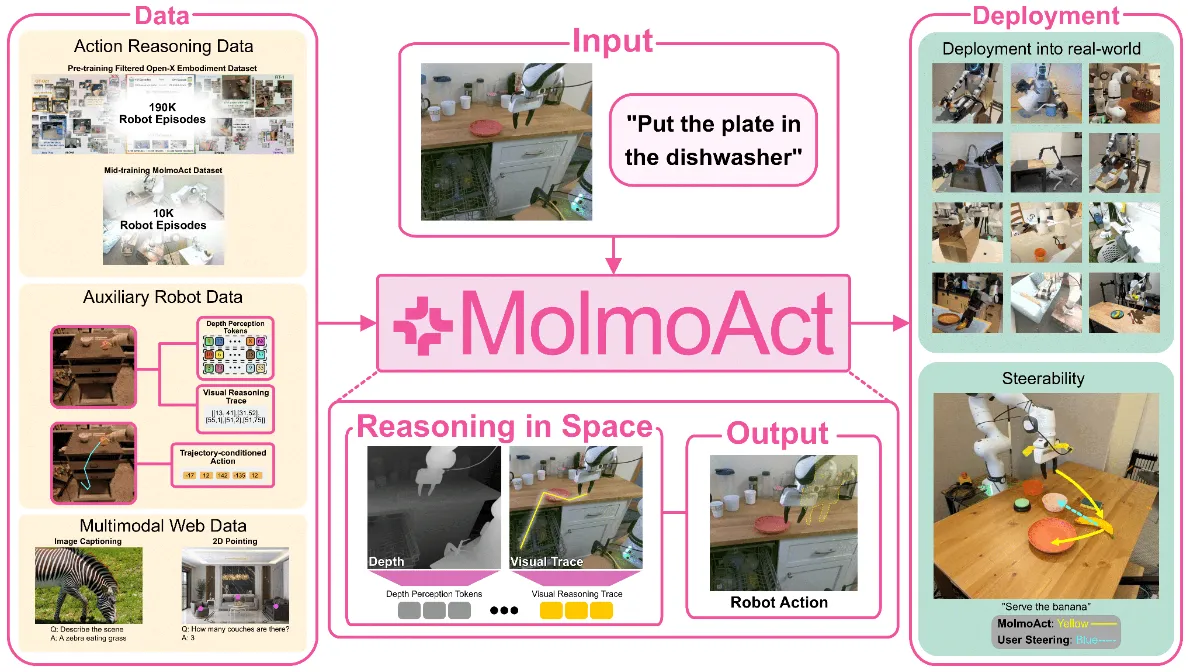
MolmoAct 是 AI2 在 Manipulation VLA 领域中的新作,本身是 follow OpenVLA 的设计,同时包括了经典的 reasoning 以及 VQA 等 VLM cotraining 的任务。
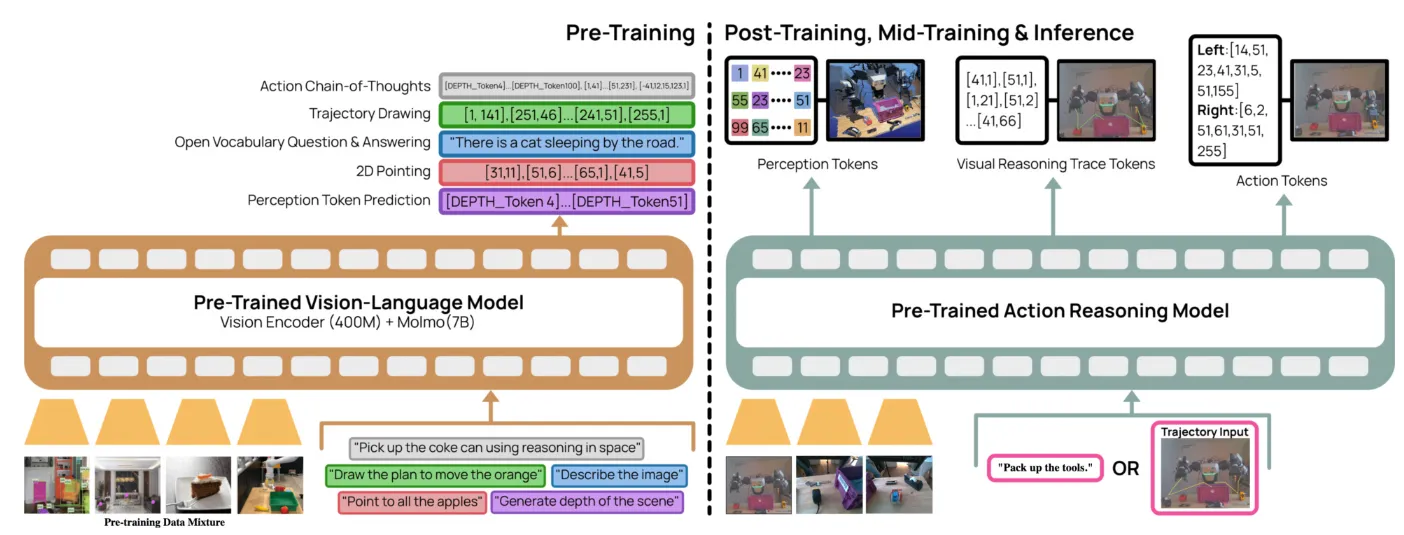
MolmoAct 本身这图长得和 Pi 很像,但是实际上是 OpenVLA-like 的架构,也就是由 VLM 直接输出 Action Token,而并不是使用 DP 来输出。本身 MolmoAct 认为在 VLA 执行过程中有几个点是很关键的,比如说深度感知以及轨迹,因此本身 MolmoAct 在训练以及执行的时候会依次输出三种不同的 token,也就是深度感知 token,轨迹 token 以及 action token。在大量的数据上进行预训练之后,MolmoAct 同样需要构造自己的深度感知 token 以及轨迹 token 来让模型自回归地学习。
其中深度感知 token 是使用 VQVAE 来自回归机器人数据集中使用 Depth-Anything V2 预测的结果,并且将 VQ 中的 codebook 结果作为 token。以及轨迹,直接使用 2D 点来表示。这些东西共同组成了 post training,而预训练依然是经典的各种 grounding 数据一起上。从结果上 MolmoAct 可以提供 in-domain trajectory,并且具有一定的 zero-shot 能力。
MimicGen#
mimicgen
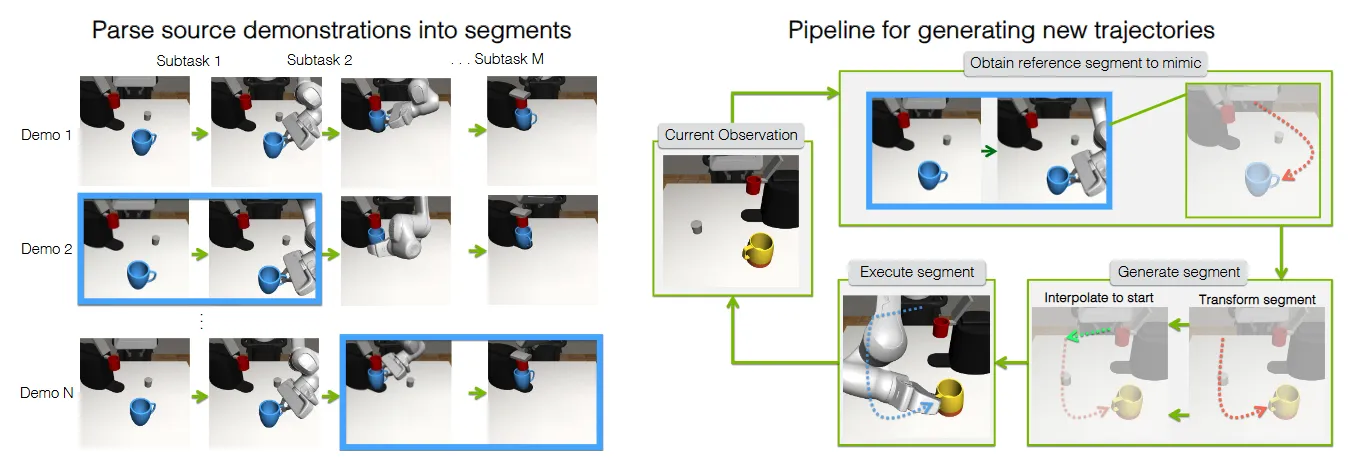
MimicGen 本身是经典的数据生成方法,本质上是将轨迹转化为 Object centric 的 grasp pose list,并且进行切片。这里的切片本质上就是将 trajectory 划分为若干的 primitive skill,比如说开抽屉或者抓起来某个物体。那么在新的 Layout 下面,根据当前的仿真可以获得每个物体的 pose,就可以根据 object centric 的 pose list 进行变换得到新的 world frame 下的 pose,并且将不连续的片段的首尾之间使用 motion planner 进行连接,也算是十分好用了。事实上如 GR00T 等模型使用了这类方法来生成数据。
SpatialVLA#
输入 semantic depth 信息的 OpenVLA-like 范式
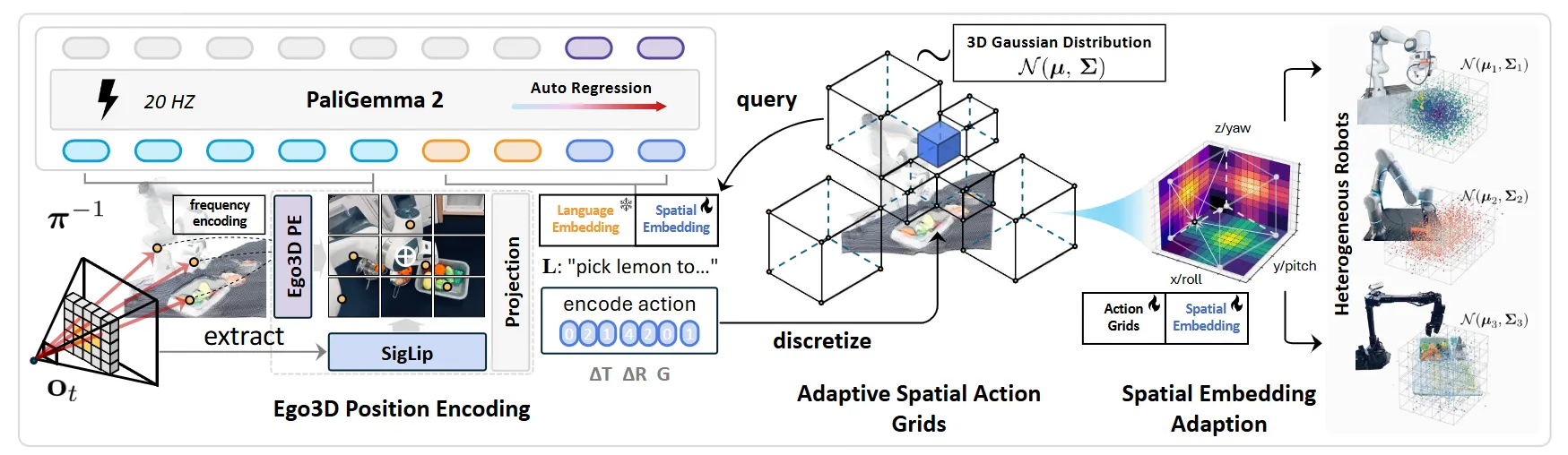
SpatialVLA 本身是十分 Work 的方法,但是这里的图是在不是很直观,简单可以理解为提出了一种将 Spatial 信息编码为 VLM 可以使用的输入,并且使用类 OpenVLA 范式的模型进行 inference。本身的输入包括了 text 的 token 以及 Ego3D visual token。这里的 Token 的获得大概是这样的流程,通过 SigLip 获得 semantic embedding,然后用 ZeoDepth 来获得 Depth,将 semantic 投影到 3D 空间,之后再用 MLP 拿到 Token。
从本质上来说,这种 embedding 的方法综合了 depth 的表征以及本身的 semantic 信息,而不像是一些其他的工作一样,直接使用 Depth encoder 去进行处理,而且本身这里的范式因为引入了 ZeoDepth,算是从 input 上的 depth free 的范式,还是很有意思的,本身的点数也都很高。
TraceVLA#
使用 2D Trace 标注作为历史信息提示的 OpenVLA-like 范式
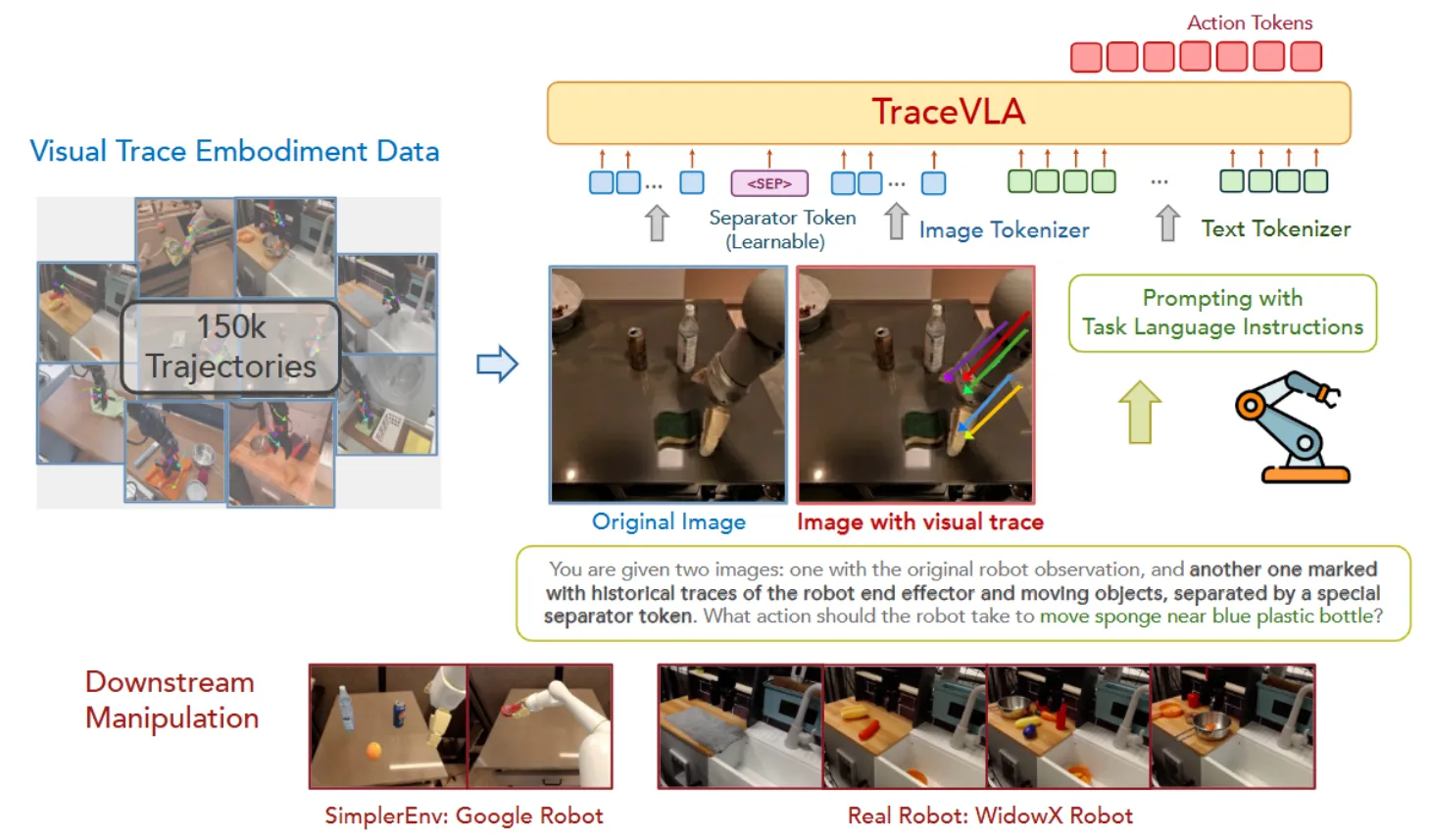
TraceVLA 本身采用了 OpenVLA-like 的范式,如图中所示,不过不同的是加入了一张别的图片,也就是标注了 2D 视觉轨迹的图片。TraceVLA 的故事点在于,OpenVLA 是单帧输入多帧输出的模型,但是 VLA 模型有必要输入历史信息,但是使用 action history 进行输入不是很直观,于是直接计算 2D 视觉轨迹并且标注在图片上,是一个不错的做法。同时因为在图片上进行标注会遮挡本身的图像信息,所以原图也同样输入。
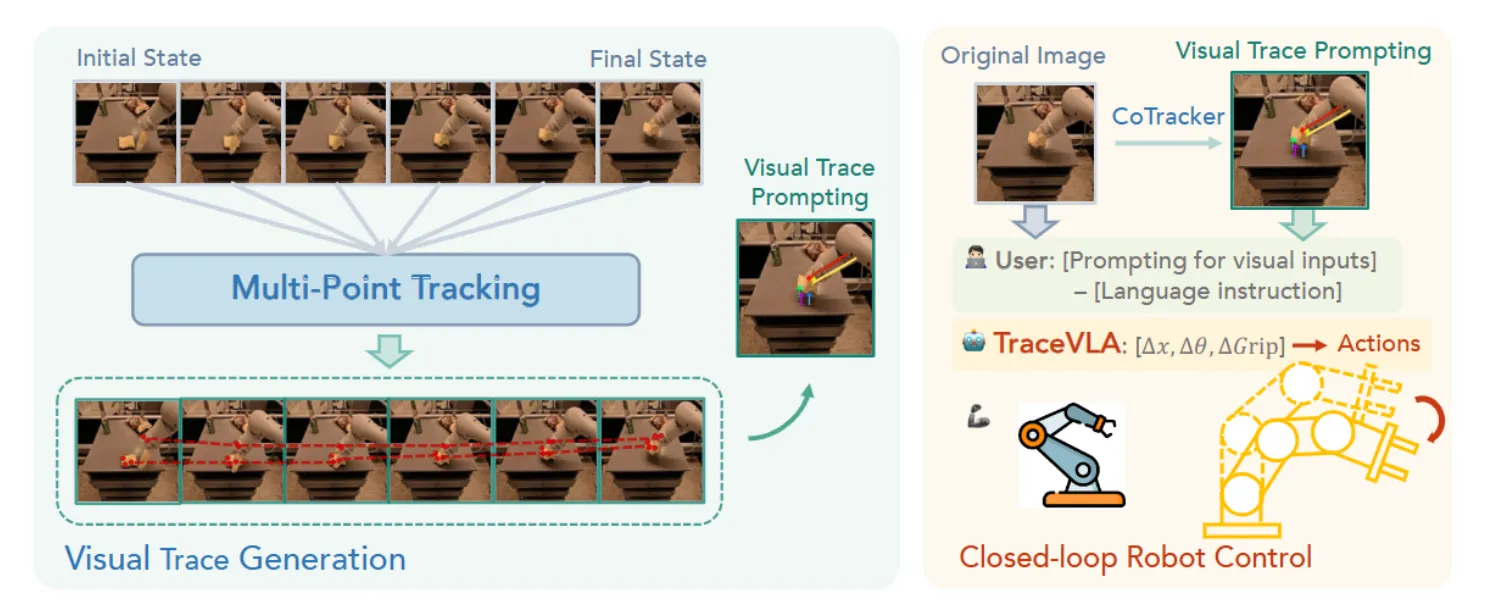
具体来说 Trace 的生成,就是保留一定的历史帧,使用 Co-tracker 来提取轨迹,并且保留运动的点,标注在图片上。从本质上,让 VLA 了解历史信息确实是十分必要的,不然对于单帧输入来说,假如说在 Pick and Place 的过程中前后有相似的动作,那么模型可能就难以分清前后了。标注 Trace 是一个很直接且有效的方法,问题只是在于,这看上去并不是最优雅的方法,会带来额外的计算开销。理论上类似的方案,可以直接使用机械臂的 URDF 的标注以及 Action 信息来直接计算出来这些轨迹点,并且投影到相机的像素坐标系下直接作为轨迹。
当然,有一些有趣的 ablation 其实在论文中并没有体现,但是其实是值得关注的,例如 Trace 的条数能否更少,或者说这个 <SEP> Token(用于在 Trace image 和 Image 之间进行分割)是否必要。
Hume#
双系统判断最佳动作候选的 Pi-like 架构
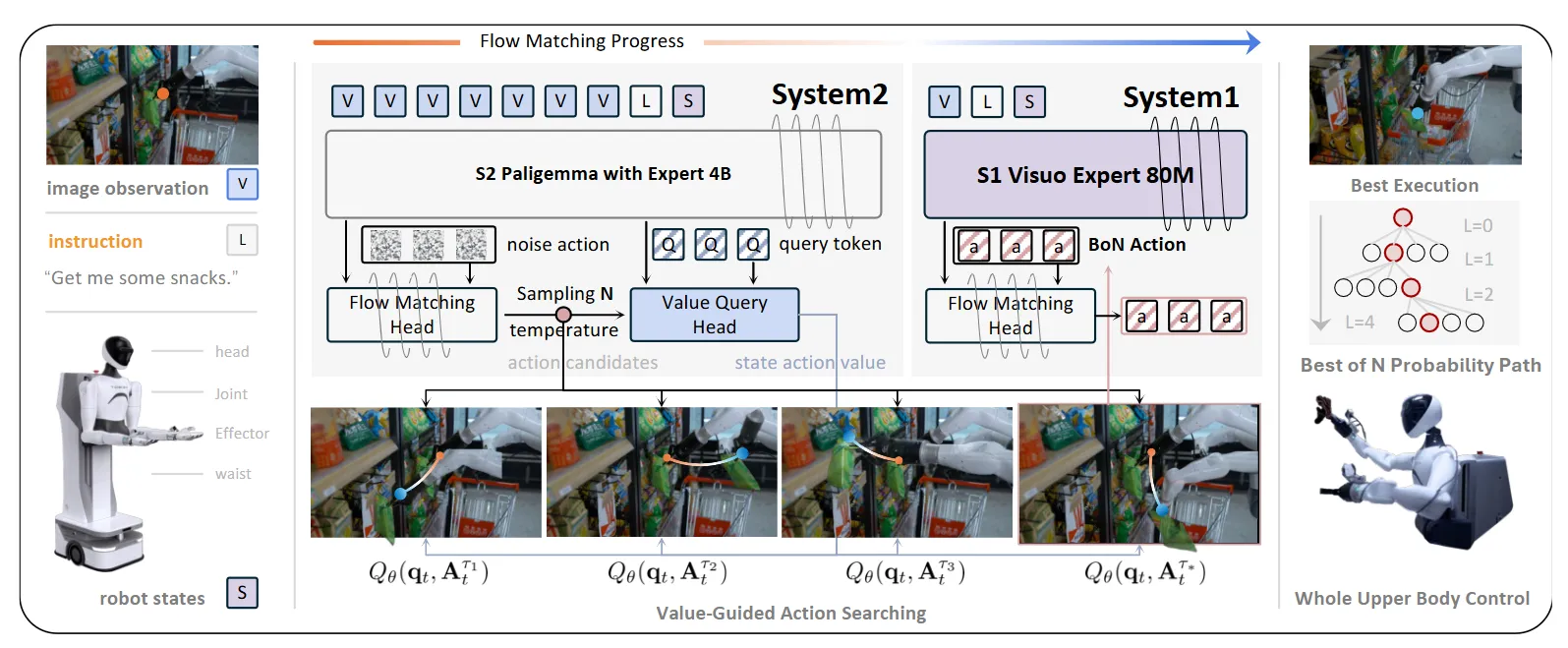
Hume 本身也算是 Pi-like 的架构,直观理解,可以认为将 Pi 的 System 1 部分分为了两个环节,首先生成候选,再在选择的候选的基础上进行进一步的降噪。本身 System2 这里已经是 VLM + Flow Matching 的完整结构,但是在 FM Model 推理的过程中,降噪十步,把十步的输出组成一个十个 Chunk 的候选动作,评价网络从中选择 Best。System1 本身也是一个 Transformer + FM,不过这里更加轻量,同时 FM 在 Best of N Action 的基础上进行继续降噪。这里可以理解为这里的 Transformer 只是作为 fusion 存在。
本身 Hume 算是在 Pi 的基础上创建了类似于快慢系统的设计,不过这里的候选动作确实在一个降噪过程中的不同步,而非不同降噪过程,那么和在降噪过程中直接输入 Fusion 的实时 Obs 信息,如 FiS-VLA 等设计,在某种程度上是类似的,而并非如 NavDP 一样的设计,那么这里所谓的 Best of N 个人感觉并非必要的。
RICL#
在 VLA 中使用插值实现的上下文学习
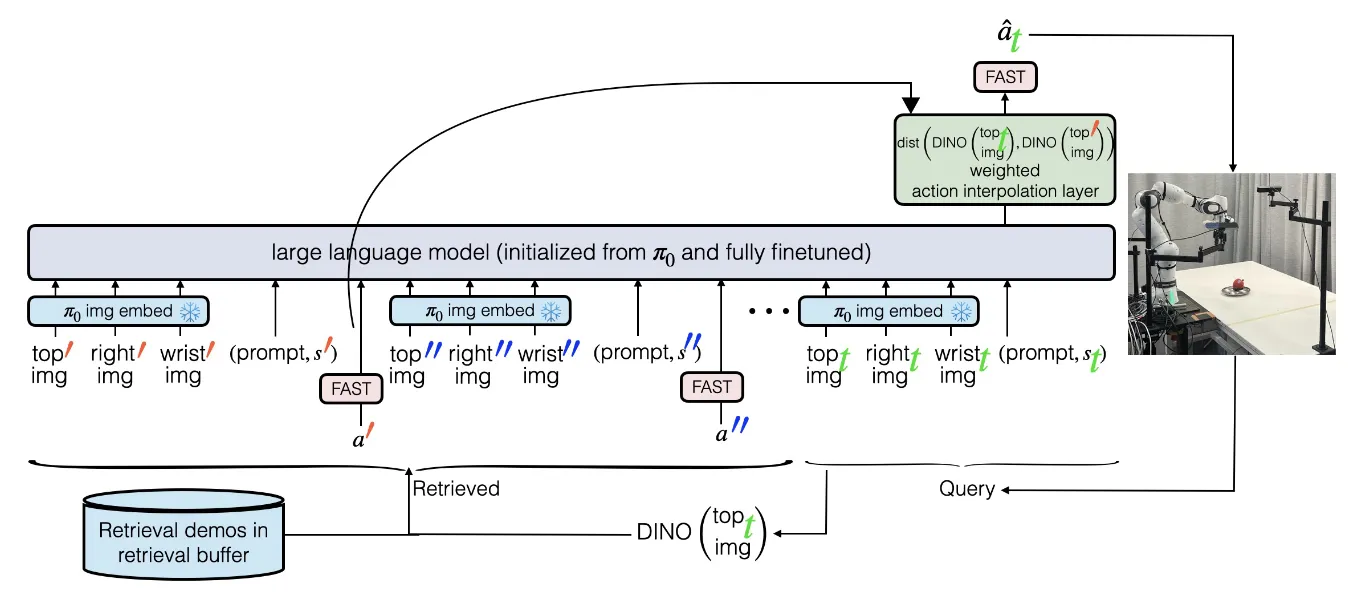
In-context learning 是一个 LLM 中非常重要的能力,也就是在推理的过程中根据历史输入而无需训练,泛化到未见任务上。这种能力明显在 VLA 中还没有进行充分的讨论,当下的领域聚焦于通过朴素的 Scaling up 来使得模型具有更多的动作能力,这篇文章对 ICL 进行了基本的讨论,并且给出了朴素的解法。具体来说,ICL 在 Manipulation 中的范式大概类似于,在开始正式任务之前,该任务已经采集了部分数据,这些数据大概与任务本身同分布,甚至完全相似,在执行的过程中,将这些可供参考的轨迹数据同样作为输入,使得模型可以参考这些数据,从而更好地完成任务。
在具身系统中进行上下文学习,本身需要两个环节,一个是索引,也就是找到上下文数据,一个是推理,也就是如何将上下文数据嵌入到模型的推理流程中。本身 RICL 使用的方法相当朴素,对于索引,使用 DINO 编码当前帧的特征来对历史帧的特征进行 RAG 即可;对于推理,则通过比较历史和当前的 OBS 的 DINO 相似度,作为加权的权重,将 FAST 编码进行插值。这一方法的朴素在于,首先,对于 ICL 的实现过于显式,使用 DINO 特征来进行解码意味着使用较短的片段,并且希望找到与当前任务完全相似的任务,这使得这一方法在语义相似但是场景不相似的任务上效果不佳;同时,尽管对于索引的信息依然作为了 Transformer 的输入,从而可以隐式在模型中进行学习,然而依然采样相邻帧,本身学习的依然是一种相当 low-level 的动作信息,而不是较为 high-level 的动作模式;最后,模型本身的范式似乎是可拓展的,但是也没有在大规模的实验上进行 scaling up,还有继续讨论的空间。不过总的来说,RICL 对于 ICL 的 highlight 本身已经足够出彩,尽管本身的规模不大,但是依然值得较高的评价。
OmniVTLA#
引入语义对齐的触觉编码器的 VLA
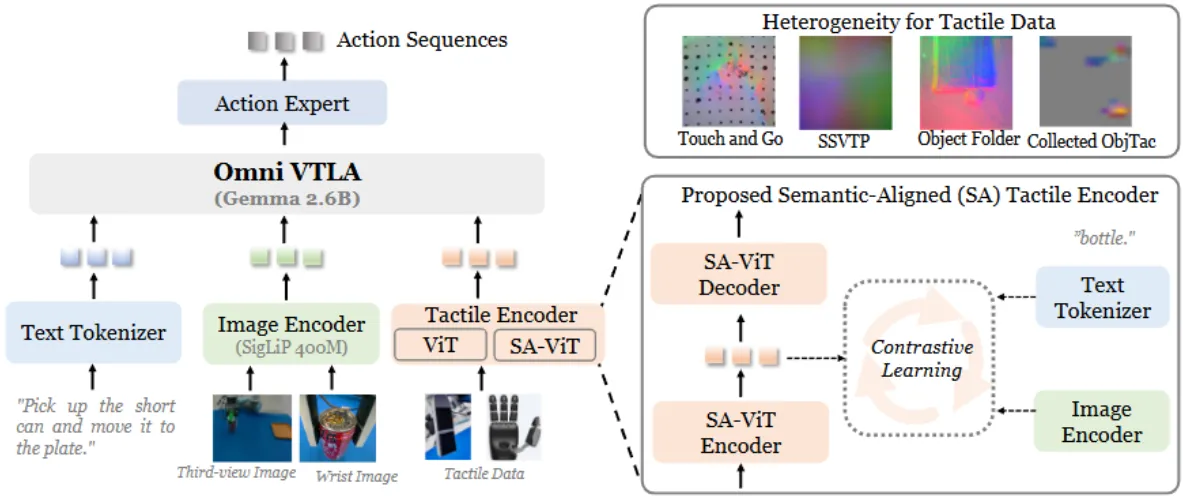
OmniVTLA 在 的基础上引入了语义对齐的触觉编码器,本身的对齐就是通过对比损失,在论文中自己采集的触觉数据集(触觉传感器接触不同的材质,其中图像是 camera 信息,文字是材质名称)上进行训练。在这里事实上从结果来看,因为只有真机实验,和 baseline 的效果对比并不显著,但是事实上触觉的存在还是有必要的。根据目前笔者的经验来说,大量的失败主要在于对于抓取时机的把握不准,也就是可能还没有到达指定的深度,就已经触发了抓取,这里使用深度或者触觉在一定程度上都可以解决这个问题,通过更加显式的信号来进行引导,触觉可能是可以带来更多用处的一个方法,也是值得探索的。
Spatial Traces#
引入 Depth 信息的 TraceVLA
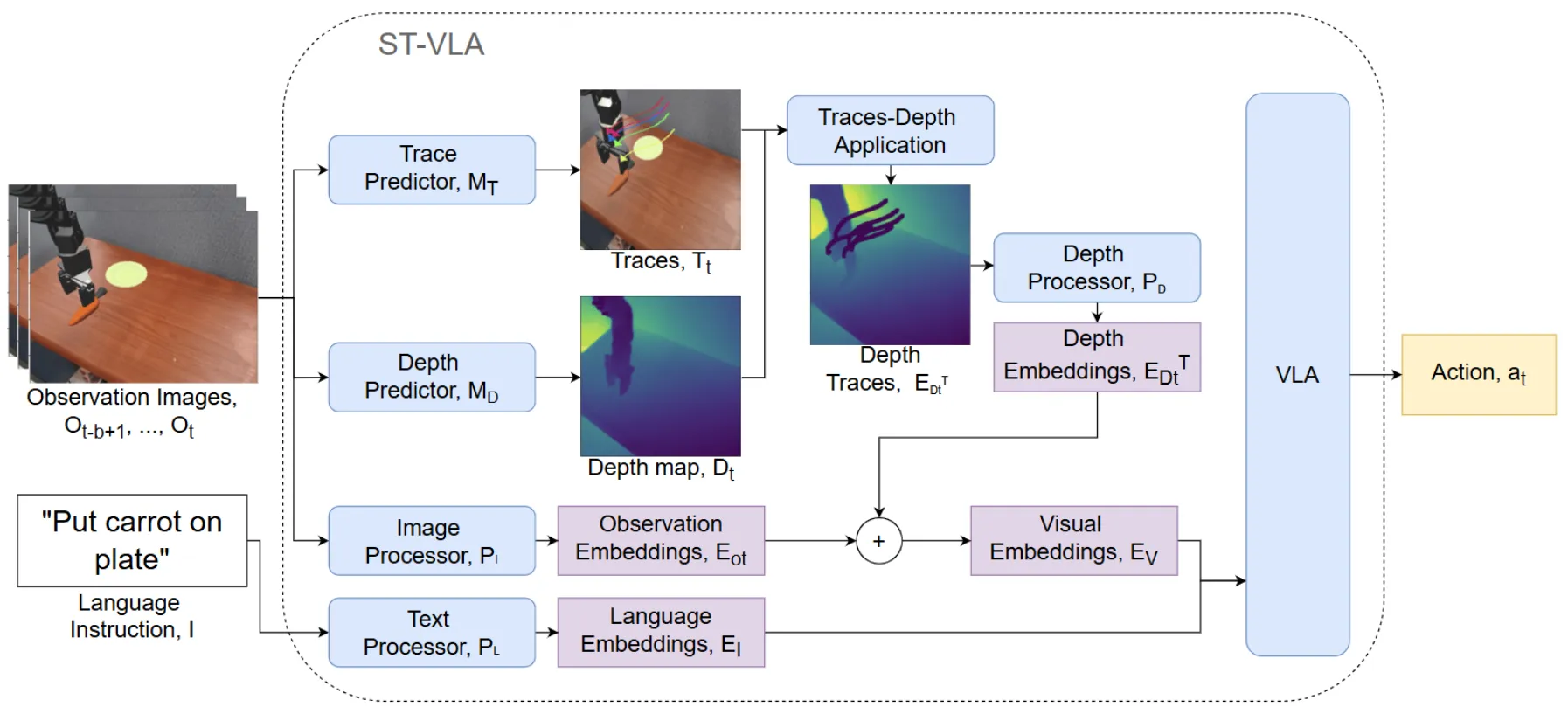
本身算是在 TraceVLA 的基础上进行的后续工作。本身的 Motivation 也是相当朴素,也就是将之前 TraceVLA 的时间维度拓展到时空,具体来说其实就像图里的内容,将 trace 标注在了 depth image 上面。之后的方法其实是比较直接,将 Vision 的各种信息拼接在一起,一起输入给 VLA。VLA 本身从 SpatialVLA 初始化,也就是一个 PaliGemma2,并且是 OpenVLA-like 的设计。
Embodied-R1#
使用 Point 作为中间表征并且用 GRPO 训练的 Embodied VLM
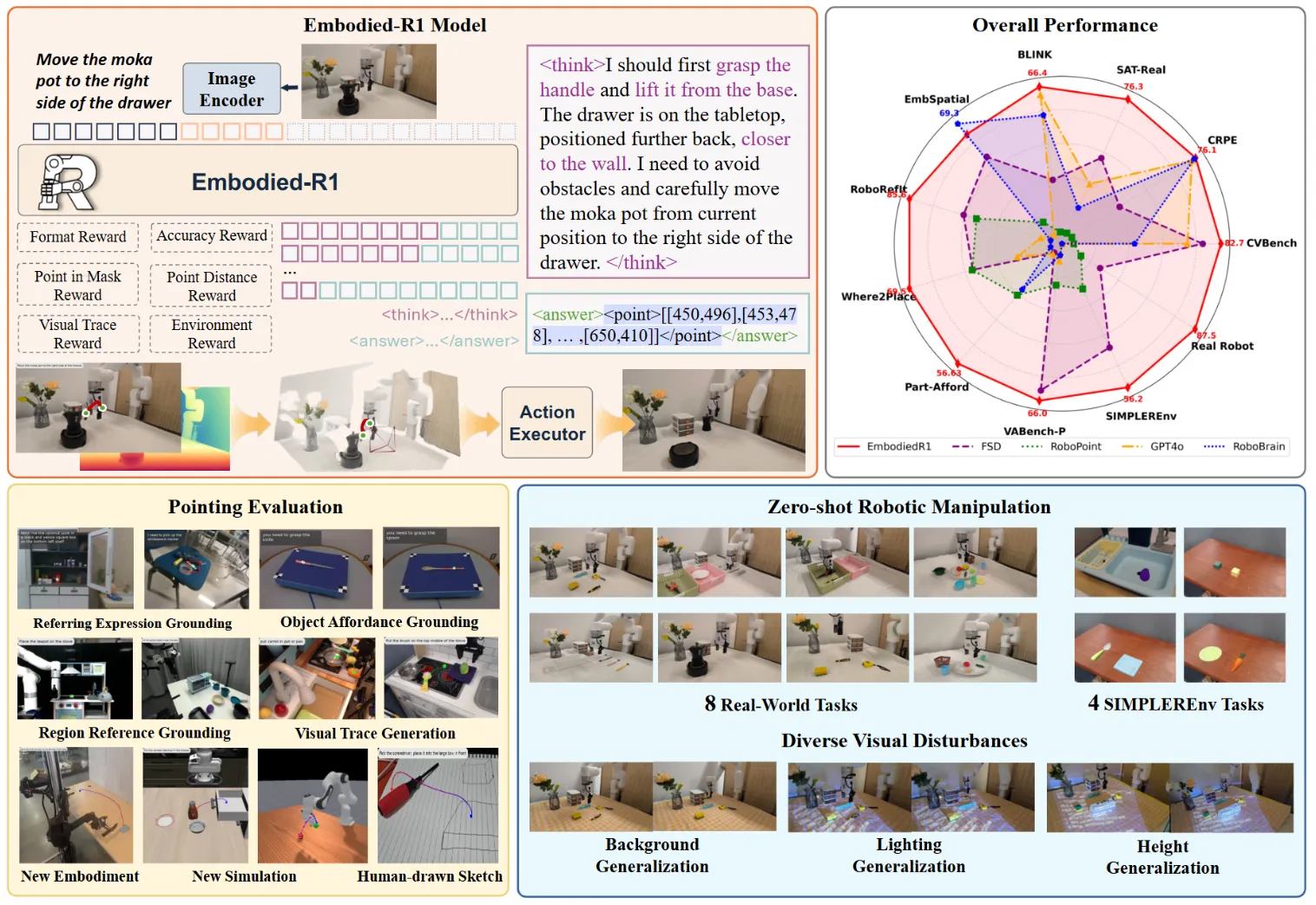
如图所示,本身 Embodied-R1,顾名思义,就是用 R1,即 GRPO 方法训练的一个 VLM。本身其实还是有不少的有趣的点以及有趣的解释的。首先第一点在于为什么选取点而不是框,主要还是因为更加灵活,以及指向比较明确,同时在整体论文讲述的时候非常关注 embodiment 无关,这也很重要。另一方面在于为什么用 RFT 而不是 SFT,也很好理解,SFT 一般适用于选择题这种答案唯一的,但是比如说描述一个区域,一个点只要落于区域内就算对,这时候 RFT 可以给全部满足条件的答案都给奖励。
模型本身的输出,在 reasoning 之后会给到 2d point,最后包括了两种模式进行动作执行。一种是 key point,也就是只输出关键点,中间过程使用 CuRobo 进行插值;一种是直接输出连续轨迹点。当然这里,感觉事实上即使是所谓的连续轨迹点,实际上最后还是要用 CuRobo 来插值。这里面 2d to 3d 的 projection 是直接使用的 depth 信息,这其实相对比较糟糕,意味着模型的全部过程点或者需要在空中的点,都会有一些问题。
其中补充的一些试验,比如说 RFT 数据里面是否加入 common sense 的数据,不加入会带来性能损失,这些角度也都是读者很关注的,读起来很流畅。本身其他内容还是没什么问题的,用 R1 也是大势所趋,整体看上去很不错。
RynnEC#
基于 VideoLLM 的 Embodied VLM
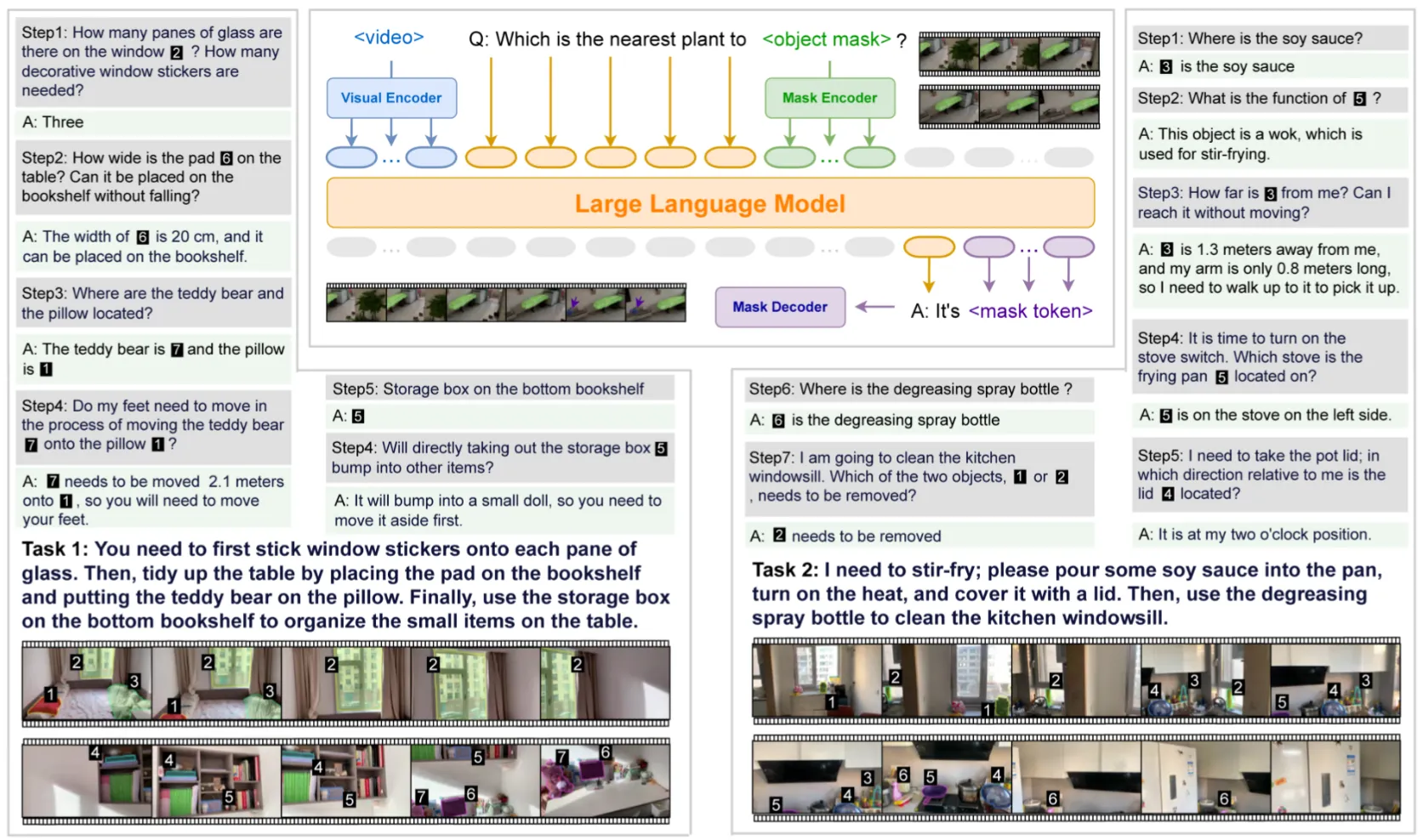
RynnEC 本身就是基于 VideoLLaMA3 构建的,本身的训练方法也就是标准的 SFT 方法。其中相对或许可以 highlight 的是引入了 Semantic Mask 的 encoder/decoder,从而可以让模型输出 mask token,从而使得模型具有 instance level 的 grounding 能力。
同时这篇论文也提出了对应的数据管线以及 Benchmark,可以说是比较大的工作量了。不过问题也比较明显,貌似这个工作很难以部署到 Action level 的下游应用,而是确实是一个很单纯的 VLM,而且也没有展现任何的真机部署。
TinyVLA#
使用 LoRA 的 Pi-like VLA
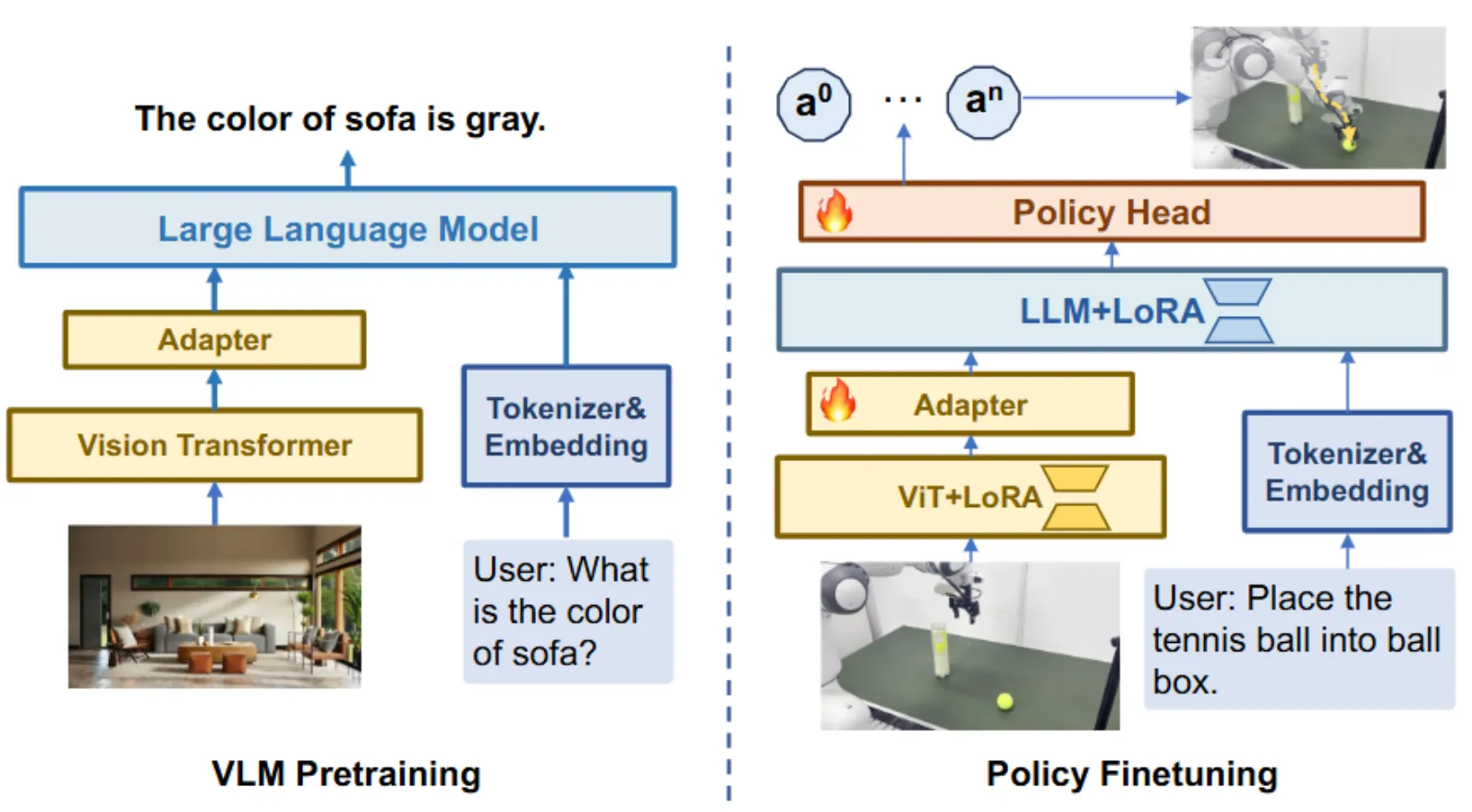
TinyVLA 实际上是首次提出了 VLM + DP 范式的模型,这个范式相当本质,有效缓解了模型的灾难性遗忘并且使得 VLM 和 action expert 各司其职,同时 leverage 了 DP 优秀的动作能力,后续的无数的工作都是基于此范式。
具体从方法来说,模型使用 Pythia 作为 backbone,使用 LoRA 在 Finetune 的时候在 LLM 里面使用 LoRA,从而不过分破坏 LLM 的能力,这在 Pi0-KI 出现之前,可以说是相当有效的做法,并且使得模型可以高效微调。本身最后的性能也不错,可以说是领域内的奠基性工作了。
RoboRefer#
进行 SFT 以及 RFT 的三维感知 VLM
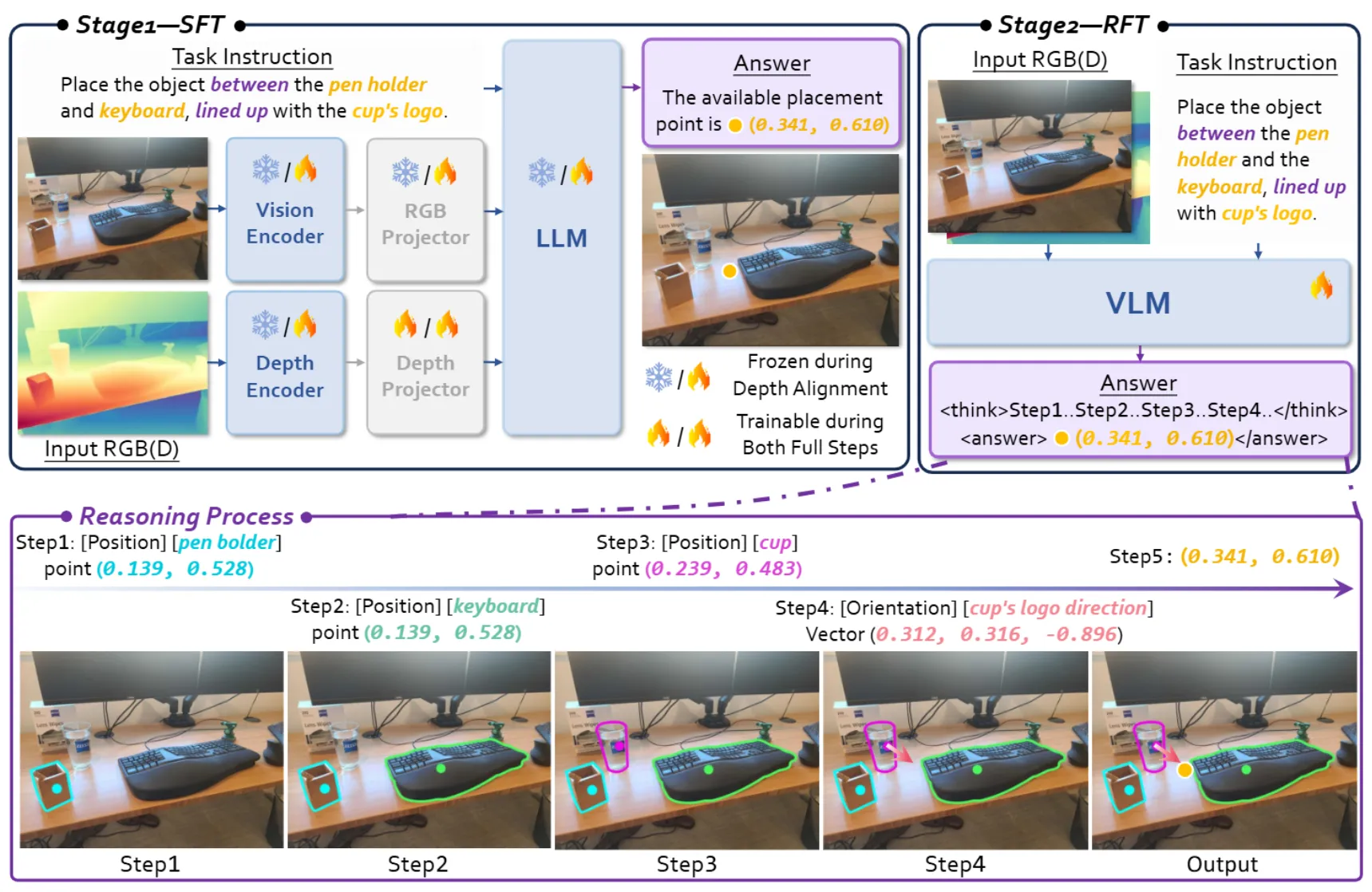
RoboRefer 使用 NVILA 作为基础模型,在输入的部分加入了 Depth 输入。SFT 训练先对齐深度,之后再进行全量微调,并且在 SFT 之后使用 GRPO 进行 RFT。RoboRefer 可以说是使用空间信息 VLM 数据训练 VLM 的集大成者,可以说考虑了很多的事情,既有对齐也有引入深度,同时输出也是 Point。同时论文还提出了 RefSpatial 的数据集以及成熟的数据管线,大量的细节在论文里都有提及,可以说是诚意满满的工作了,尽管更多的是 engineering,但是确实很闭环而且很清晰。
HERMES#
使用 RL + DAgger 实现的 Moblie Manipulation
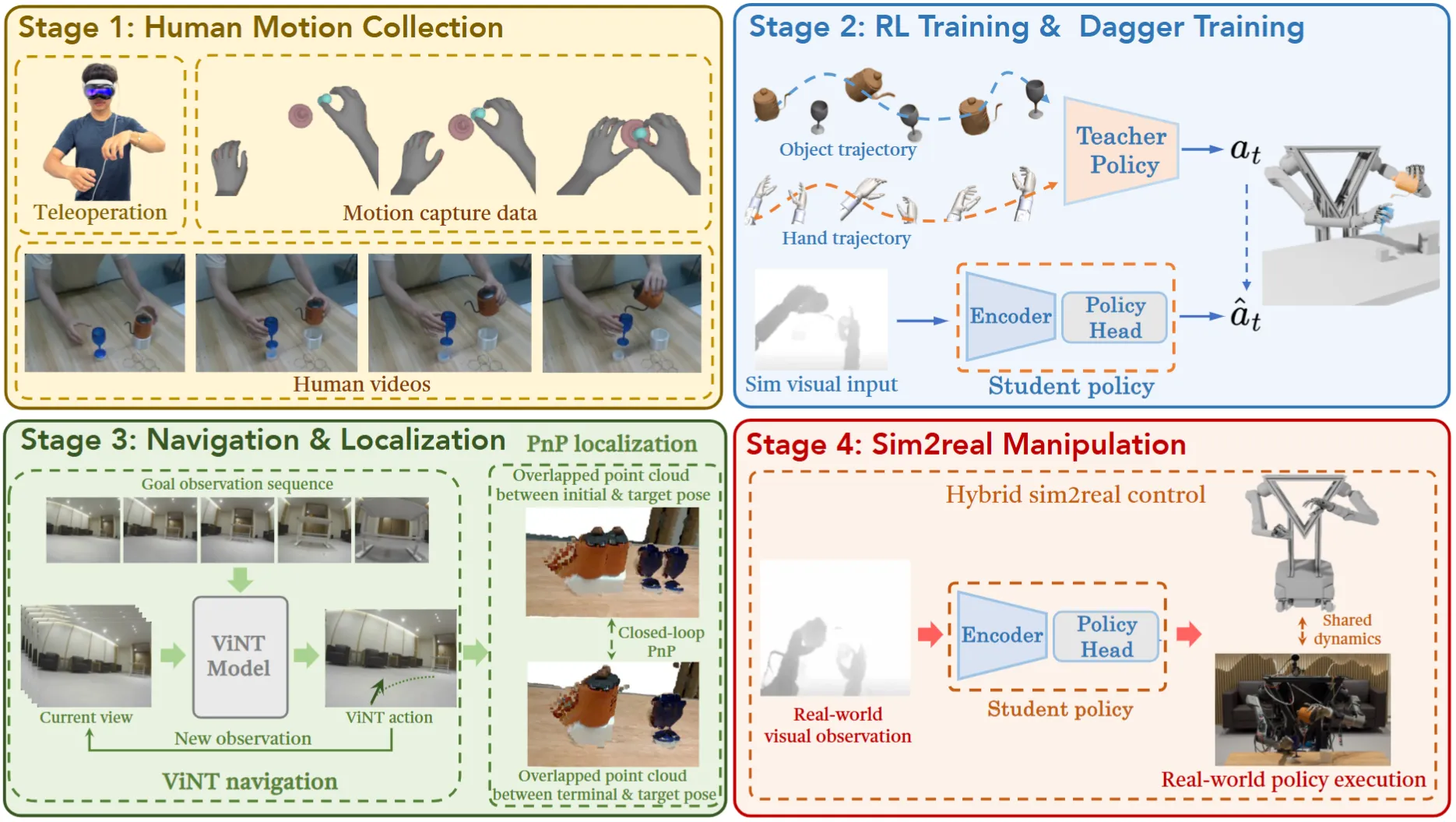
老实说,HERMES 本身其实从图中来看也可以看出来,内容相当的 technical,在这里简单写一下整体的流程以及我比较 naive 的理解。从故事上来说,HERMES 本身想要实现的是使用 RL 来让模型从多源数据中学习,这里面使用的技术就是各种方法来提取 hand 以及 object 的 pose,但是提取之后需要放到 Sim 里面进行执行,这也就意味着需要 recover 出来模型本身的 mesh 并且放到仿真中,所以总体来说有点像一种版本的 mimic,而且并不 Scalable。在构造了 RL 模型之后,就可以使用 DAgger 来训练一个 Student 模型了,对于不了解 DAgger 的读者,可以理解为,从单个或者多个 RL 模型中蒸馏一个 learning based 模型。在之后就是弄了一个 VLN,组合在了一起,来实现 Moblie Manipulation。不过讲实话,整体的不少内容有点混乱。
Discrete Diffusion VLA#
Bert-style 的 OpenVLA-like VLA,多步 refine action
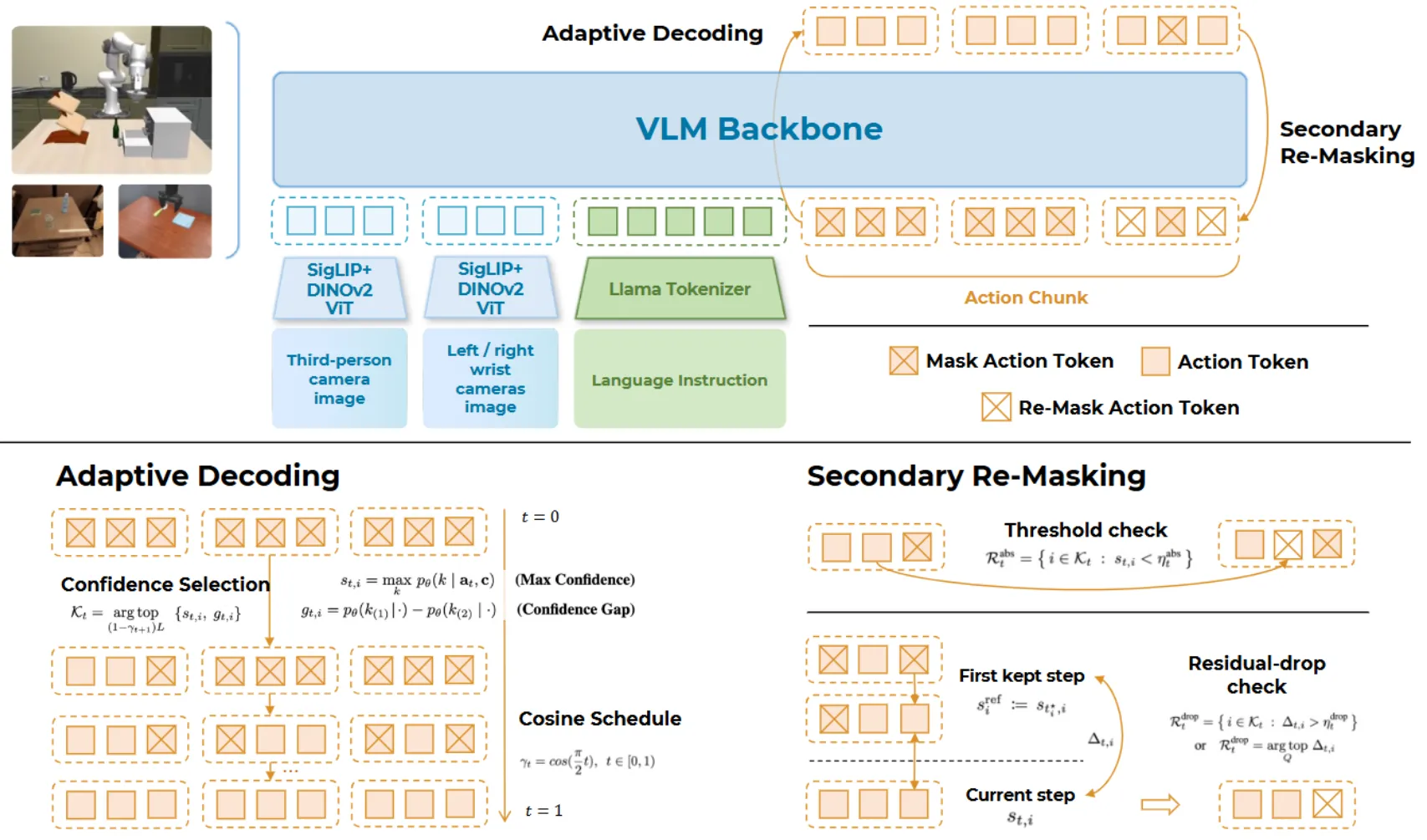
尽管 Discrete Diffusion VLA 的论文中在不断强调自己的 Diffusion 身份,但是实际上在理解上,从范式上去看,本身就是 Bert-style 而已,因此并不具有真正的降噪或者加噪过程。这一过程在论文中被描述为对于 action 的加/减 Mask 的操作。同时因为采取了 Bert-style 的范式,具有了比较高的并行度。除此之外的内容主要就是一个 OpenVLA-like 的范式,还算有意思。
G0#
Post-training VLM + 两阶段训练的 Pi-like VLA 的预训练工作
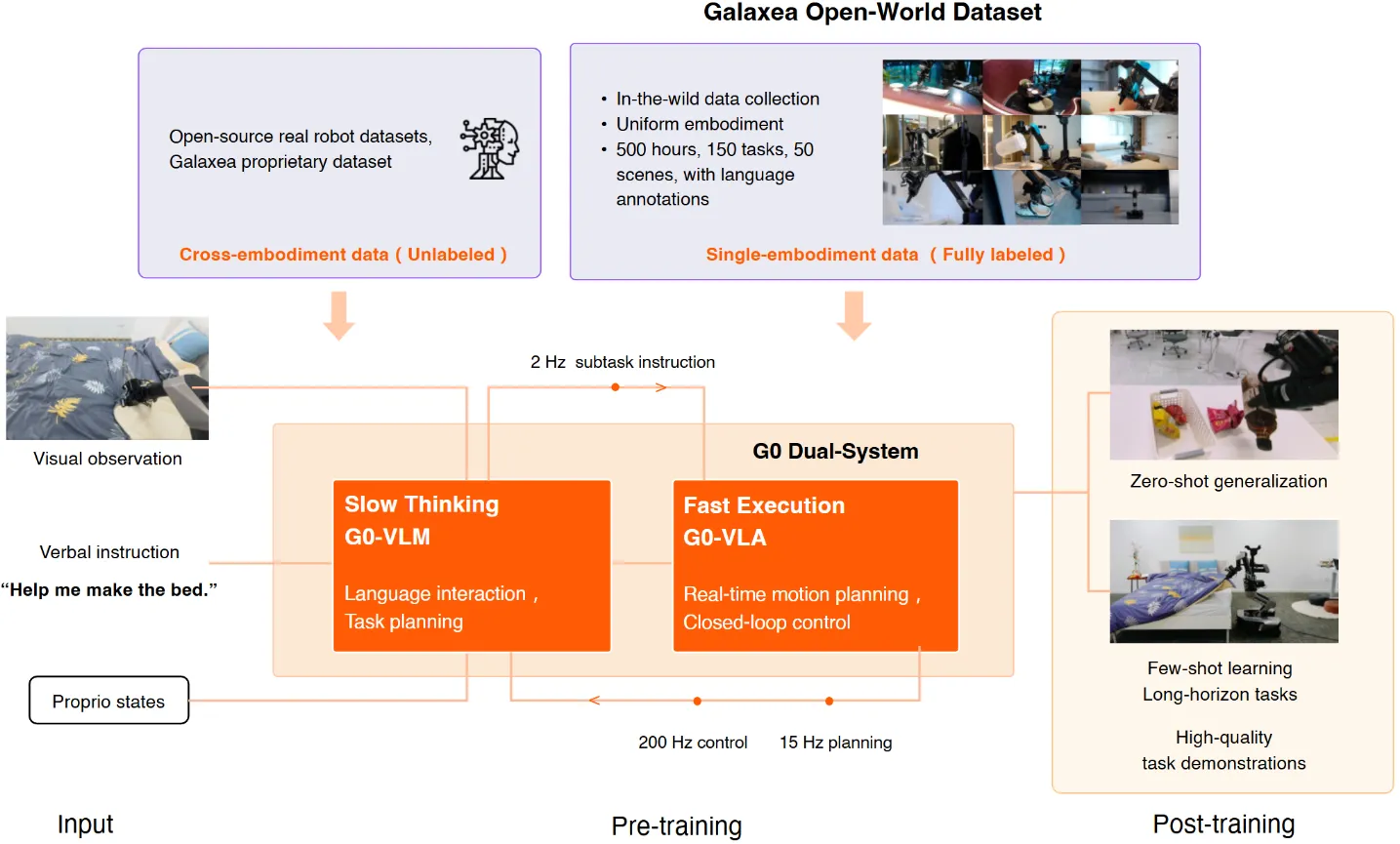
G0 是一个大型的 VLM + VLA 的 Pre-training 工作。本身的结构算是双系统,其实本质上也是类似于 Pi 的设计,从 PaliGemma 初始化,由 VLM + Flow Matching 的 DP 组成的。本身 G0 提出了一个大型的基于其本体的数据集,同时对于不同的任务进行了划分,来实现比较粗粒度的任务规划以及一些交互选项。
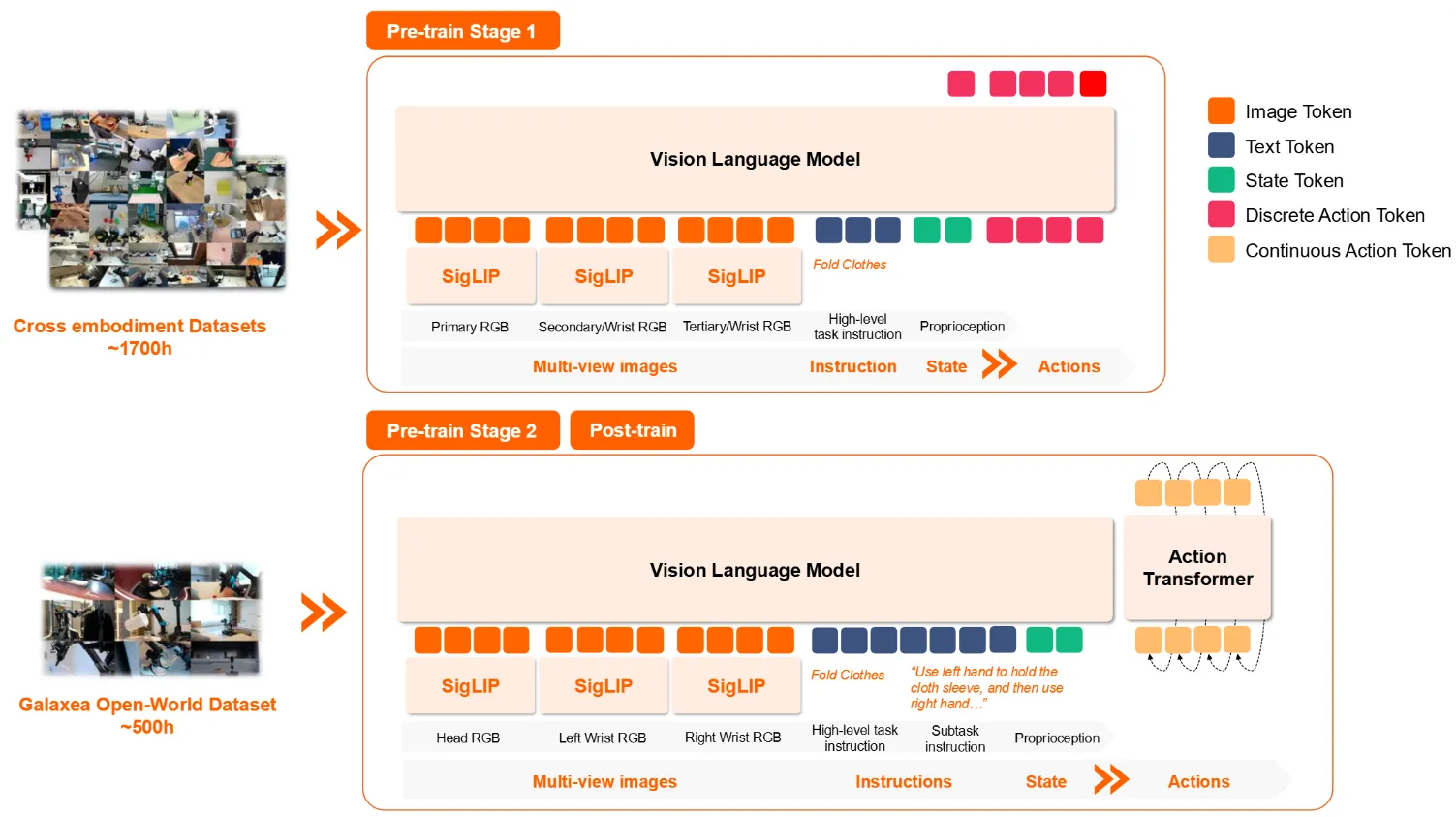
对于 VLA,分为两阶段。第一阶段在大规模异构数据上面预训练,其实还是类似于 Pi 的做法,只是没有 co-training VLM Data,而是只用了 FAST 进行 action tokenization 的离散动作来进行 next token prediction;第二阶段在他们自己的数据集上后训练,添加了 Action Expert,并且用 Flow Matching 来进行训练,本身没有什么额外的细节。在两阶段之后可以认为得出了一个预训练模型,这里之后就可以到具体的下游任务上进行验证使用了。实验部分的实现来看,其实预训练某种程度上没有那么有效,各种内容其实也没啥递增的一致性,只能说最后混在一起训练了一波,结果还算说得过去。
对于 VLM,就是从 Qwen2.5VL 开始训练,用 G0 数据集中标注以及 rewrite 的 VL 任务拆解数据进行训练,本身没什么好说的。
整体来说 G0 算是中规中矩的预训练工作,处于工作量来看应该算是还可以吧。
InternScenes#
大型场景资产数据集
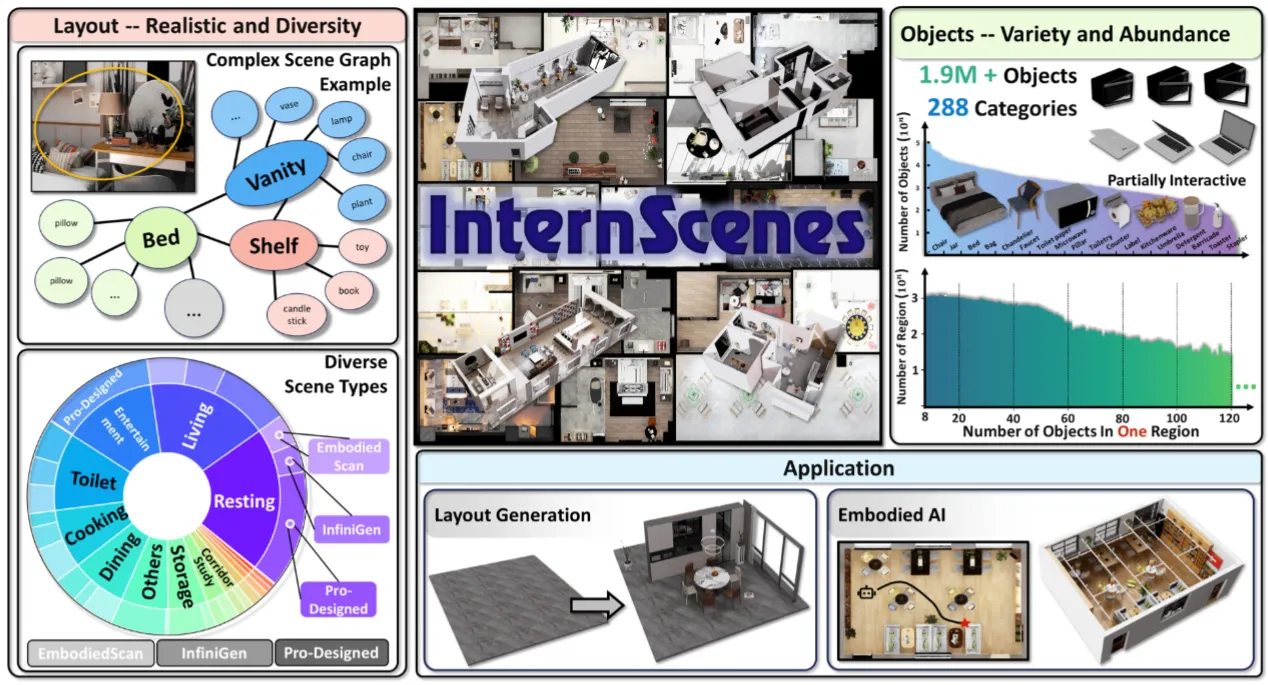
非常巨大的场景资产数据集,包括了大量的场景资产,涵盖 40K 个场景以及 1.96M 个物体资产。整体源自于 EmbodiedScan, Infinigen indoors 以及设计师设计的资产,并且可以替换场景中的物体来带来更多的多样性。