
Paper Reading: Embodied AI 7
从一些 Embodied AI 相关工作中扫过。
VITA-E#
VLM+VLA 的双系统框架,讨论了交互模式
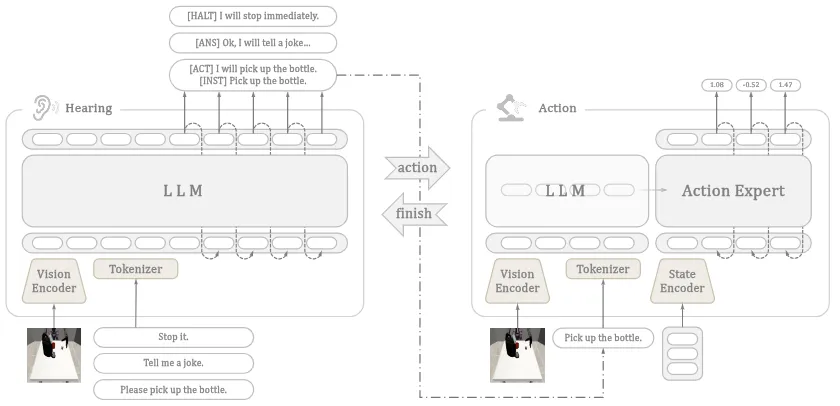
VITA-E 如图所示,这篇工作提出了一个标准的双系统,其中一个是 VLM,在一般情况下待机,用户交互的时候有可能输出 [act] token 并且让 VLA 进行推理。从性能上来说,VITA-E 的性能低于 GR00t,硬要说的话,可能算是某种产品设计。
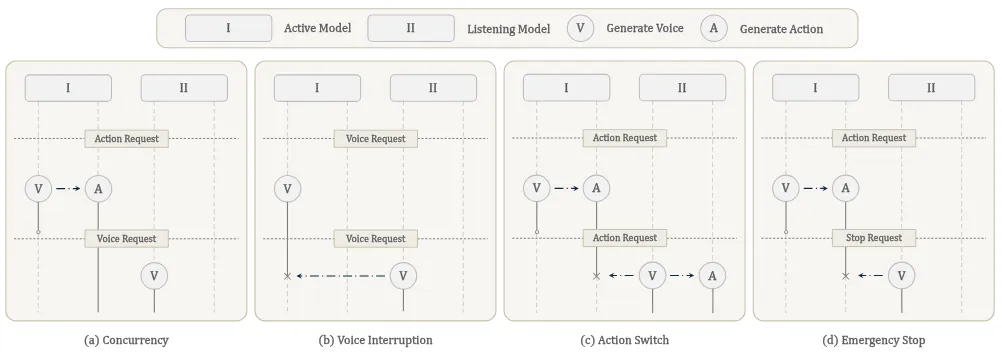
如上所示,给出了一些不同的交互模式,大概这就是这篇的全部。
OmniDexGrasp#
使用图像生成以及其他的基模组成的 DexGrasp Modular Framework
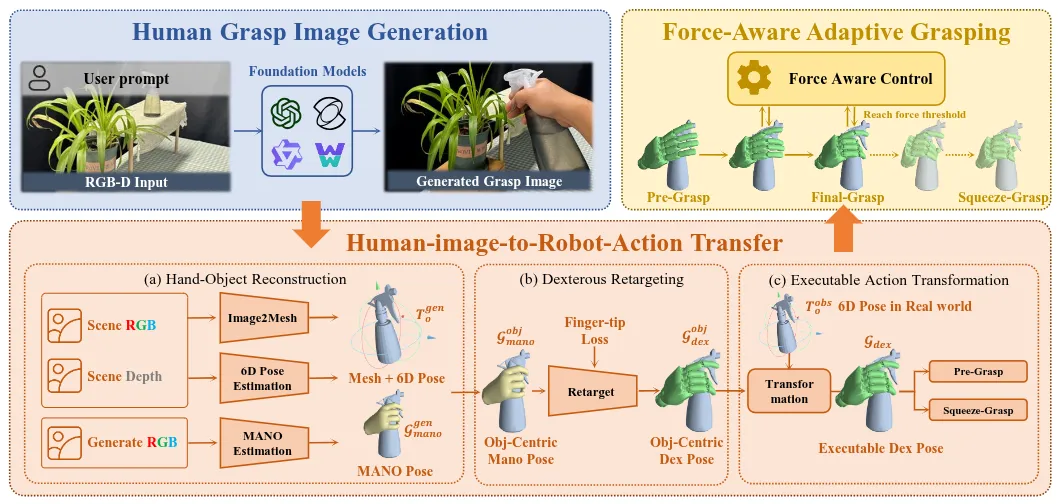
OmniDexGrasp 的内容如图所示,基本的方法就是使用图片生成模型以及图转 Human DexPose 的模型,来对于当前的任务生成 Grasp pose,之后转到 Dex Grasp,并且使用 GPT 预测力的大小来进行所谓的 Force-Aware Adaptive Grasping。事实上大多数 Modular Framework 都具有不灵活的 Limitation 并且包含了大量的调试才获得 Demo,这个方法依然如此,甚至 Limitation 到了几乎 Grasp。同时,这里所谓的 Force-Aware Adaptive Grasping,引入 GPT 似乎也没有必要,给一个比较小的力就好了,就不会出现论文插图中捏爆物品的 Case。
Dexbotic#
VLA 工具箱
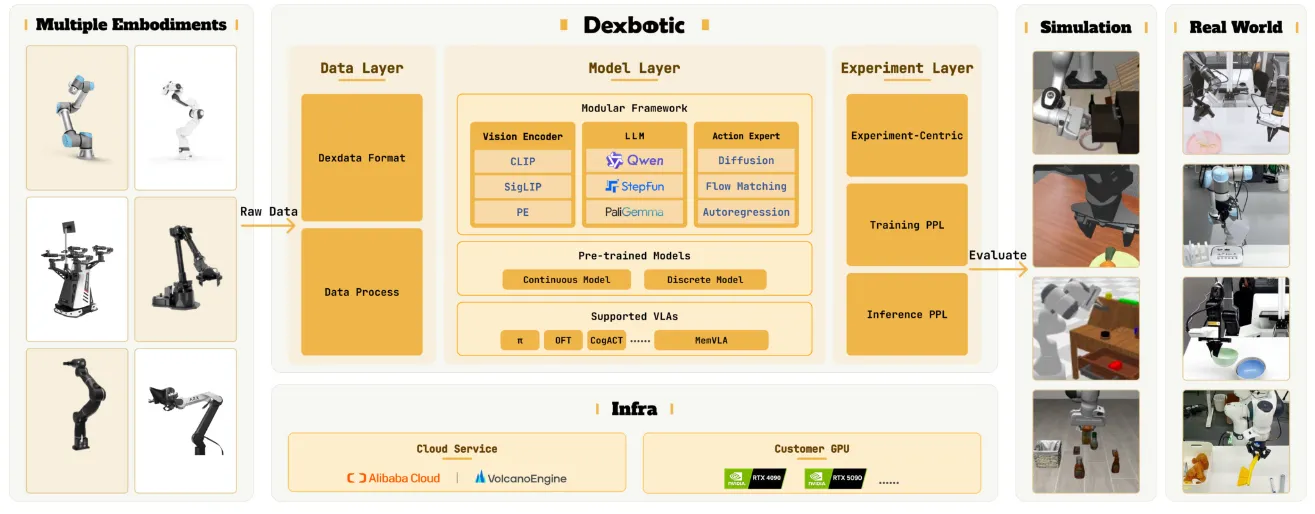
Dexbotic 是 Dexmal 的 VLA 工具箱,包括了数据、模型以及测试部分,从仓库居然还在更新而不是弃用来看,还是有一定决心的。本身 Dexmal 还是想要做 all in one 的,不过在这里主要说一下 Limitation。一方面就是仓库做的又大又满,做的一些抽象也不是很恰当,导致用户需要写大量的内容;另一方面就是其中复现了很多论文,显示了使用 Toolbox 带来的性能提升,但是问题是,假如说就是普通的复现,为什么每一个模型都会有性能提升,这是什么原理?假如说是原来模型的训练代码有 Bug,那么也可以指出,但是假如说只是使用一套 Infra(而且似乎底层的优化不多),性能提升从何而来?有的时候这似乎并不一定是一件好事,反而引人担忧。
RobotArena #
使用 Framework 从视频中恢复仿真场景并使用 VLM/Human in the loop 的 VLA 测评

RobotArena 的内容如图所示,基本的方法就是使用 Framework 从视频中恢复仿真场景,大概就是经典的 Depth 估计以及 3D 生成模型,之后生成一些物理参数,做出来仿真场景(事实上这个场景可以预料,loop 里面还是有相当多的 Human 在里面的)。本身论文通过这种方法从几个经典的数据集中生成了大量的 Benchmark,然后使用 VLM/Human in the loop 对 VLA 进行测评。事实上我并不认为这种方法对于当下是恰当的,当然效仿 LMArena 的想法是很有趣的,因此值得一个赞扬。Limitaion 主要在于,对于当下的 VLA,绝大多数任务的评价标准都是绝对的,比如说是否完成这种事情,在仿真中利用特权信息直接判断是绝对准确的,完全没有必要引入 VLM 或者 Human 进行评价,至于操作是否稳定作为标准,肉眼可见的很长时间内并非是社区的关注点。
World-Env#
使用 VLA Rollout 训练 WM Simulator,使用 WM Reward 来 RL 训练 VLA
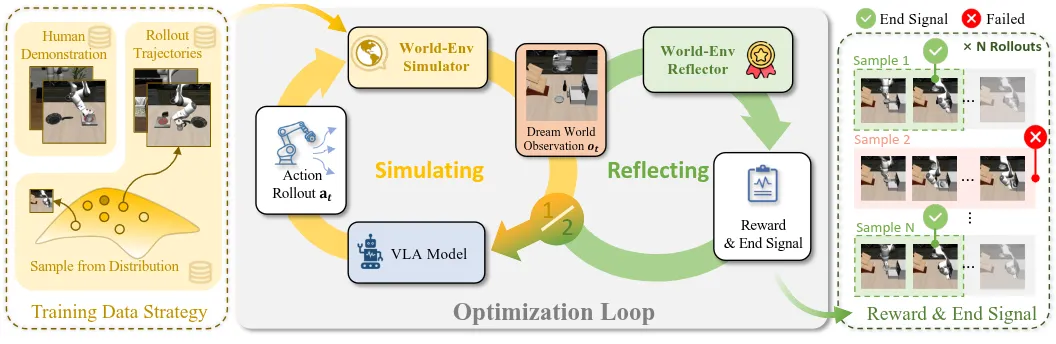
World-Env 的内容如图所示,基本的方法就是使用 VLA 在仿真器或者现实中的 Rollout 以及一些采集的数据,训练 WM Simulator;之后使用 WM Simulator 以及 Reward 来 RL 训练 VLA。World-Env 给出了十分清晰的框架,并且肉眼可见是 Scalable 的,相较于一开始就各种叠 Buff 的 WM-Simulator-RL-VLA 类型的工作,这篇毫无疑问值得一读。
为数不多的问题可能依然在于 Reward 问题,也是 WM Simulator 笔者认为比较明显的问题,即存在 Bias。假如说从 Rollout 里面均匀采样,多半 Simulator 倾向于输出失败信号;从训练数据里面学习,最后 Simulator 都会输出成功信号。二者联合起来不知道能否在一定程度上解决这个问题,还是说需要一个精心设计的动态 Dataloader 来 balance 这一切。整体这篇底子不错,剩下的就只需要基模提升以及范式继续 Scale up 了。
DUST#
Joint Diffusion 的 Pi-like VLA
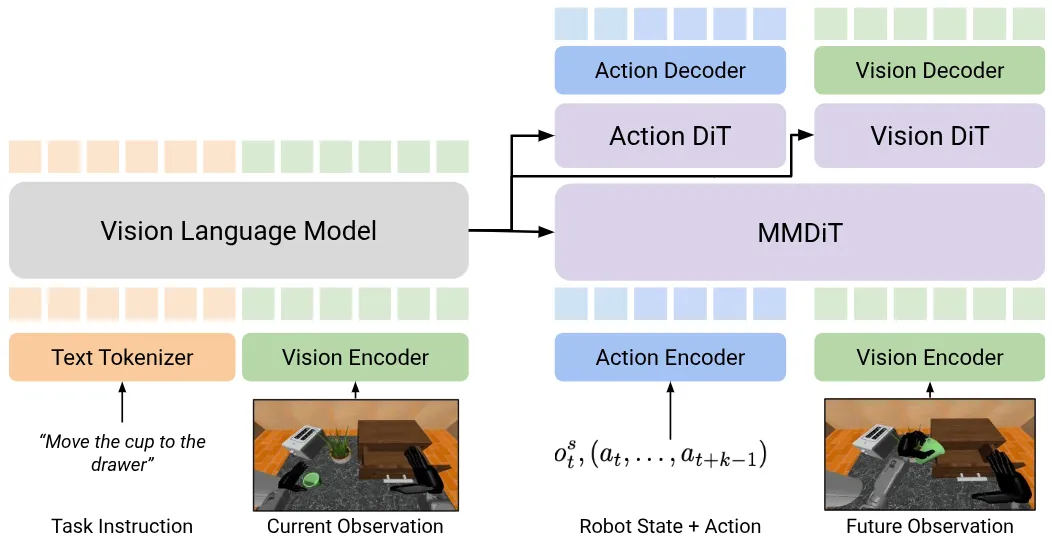
DUST 本身的设计就是常见的 Pi-like 模型,但是有趣的地方在于进行了 WM 的建模,并且是通过 Joint Diffusion 的方式来进行的。具体来说,就是 VLM 的 Condition 给到 DiT,然后 FM 部分是 MMDiT + 各自的一小段 DiT 组成的,在训练的时候进行协同优化。其中包括一些有趣的细节,比如说之前有研究证明每种模态使用独立的噪声注入,就可以将两种模态扩散的联合目标分解为单峰值扩散损失之和,运用这一点,就可以直接将 Loss 加在一起;还比如说,因为 Image 按理来说 Diffusion Step 数量应该多一些(因为需要更多迭代才可以高质量),因此两者可以频率不同进行推理,类似于图片推四步而 Action 推一步;当然,还有比较经典的,WM 部分预测 hidden state 而非 Pixel。本身工作是相当有趣的,一个引人思考的点在于,这样子是否相当于引入了一个 WM,那么引入一个预训练的 WM 会不会有好处。
#
两种在 Pi-like 模型中引入 RL 的范式
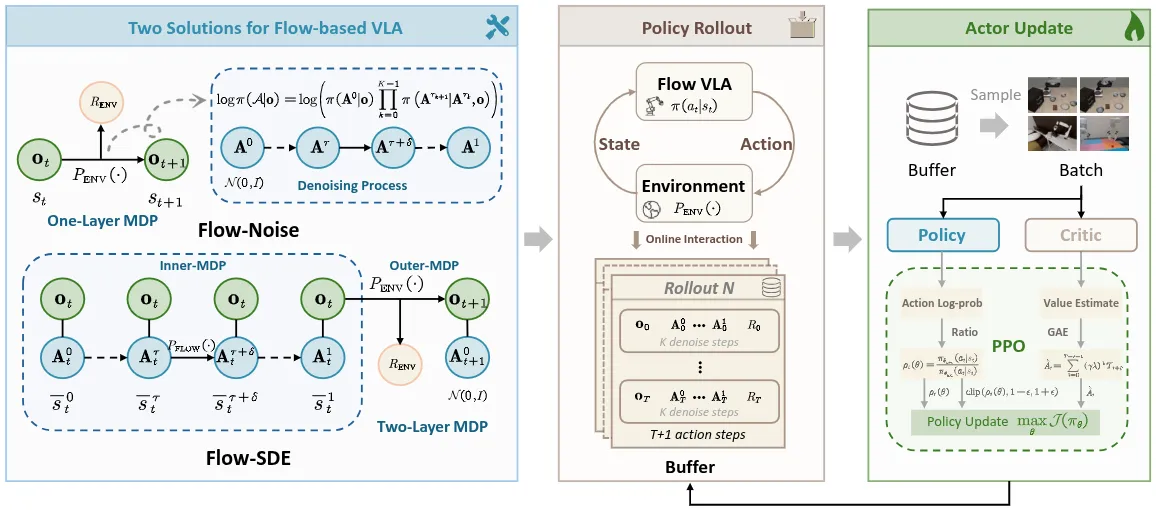
对于 RL 方法来说,一般来说都需要获得到 的值,从而进行诸如 GRPO 的内容,但是在 FM 里面,因为涉及多轮迭代,这一过程并不容易计算,因此论文提出了两种方法,Flow-Noise 以及 Flow-SDE 来解决这个问题。首先,对于 Flow-Noise,将降噪阶段建模为离散 MDP,可以直接计算 logits;对于 Flow-SDE,则是在最后构建了一个两层的 MDP,这些细节都可以在论文中看到。
同时对于 Critic 模型,也有两种方案,也就是从 VLM 里面构建以及从 FM 里面构建,可以说都是进行了全面的探索。本身论文是 RLinf 他们做的,基于 RLinf,可以说对于 VLA RL 进行了十分 Solid 的探索。
RobustVLA#
在 RL 流程里面引入扰动来增强 VLA 鲁棒性
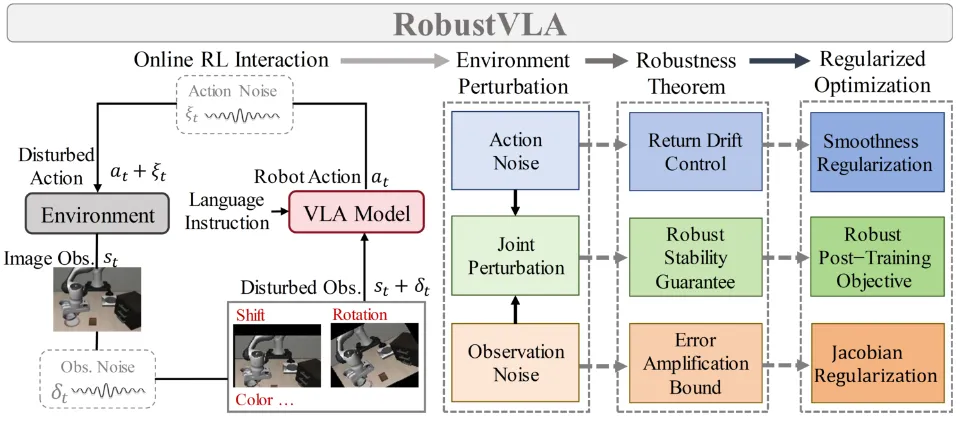
RobustVLA 这篇论文比较好理解,如图所示,就是在 RL 流程里面引入扰动来增强 VLA 的鲁棒性。主要的 Limitation 在于几点,首先,在训练 RL 的流程中引入噪声,这显然就是之前的 Locomotion 的常见做法,从创新性上几乎没有;其次,试验中明显也是对于自己添加 Randomized 的方向进行测试;最后,本身通过此类干扰是不能真正让模型鲁棒以及泛化的,不同于 Locomotion 在现实中因为电机等问题的 Sim2Real,因此在力方面需要有大量的训练,VLA 更多的问题在于指令以及视觉特征的泛化,显然 RobustVLA 在这方面具有相当大的局限,也是为什么从 Locomotion 直接照搬方法显得如此不恰当。
Cosmos-Predict 2.5#
Nvidia 的 World Model 技术报告
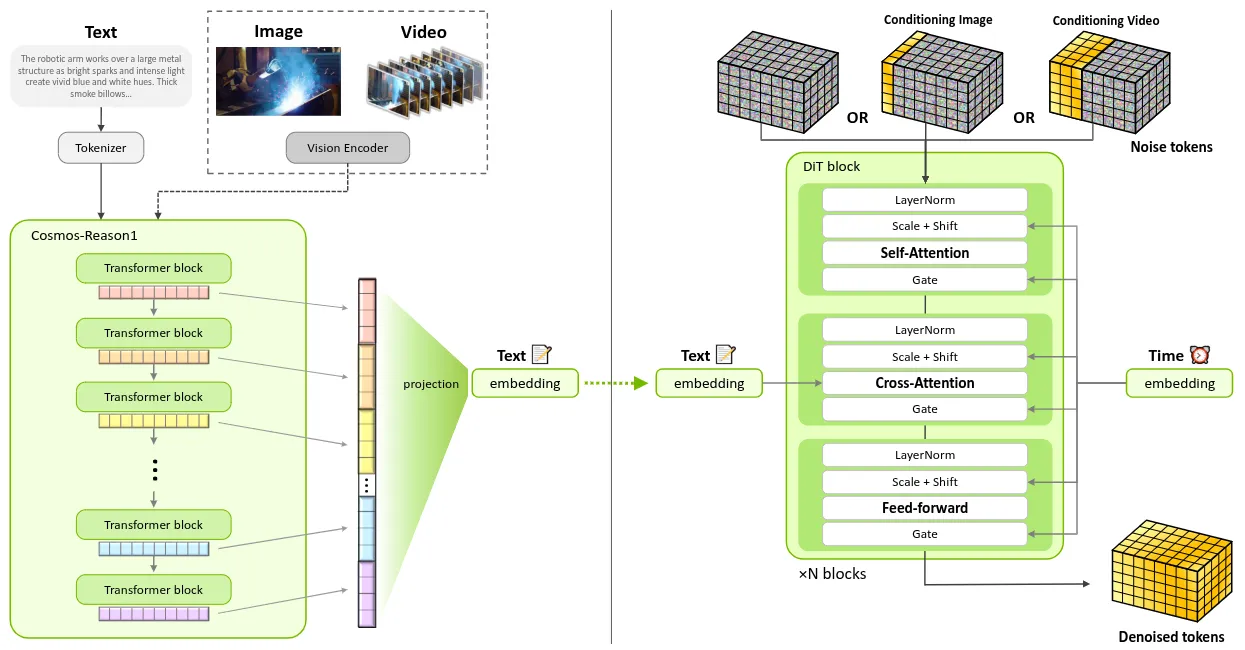
Cosmos-Predict2.5 是 Nvidia 的最新 World Model 技术报告,如图所示,主要就是对前作进行了升级,包括了更加丰富的数据集以及更加全面的训练。本身模型基于 FM 构建,将 Text2World、Image2World 和 Video2World 统一集成于单一模型中,并利用物理 AI 视觉语言模型 [Cosmos-Reason1] 提供更丰富的文本基础与更精细的世界仿真控制。论文里面还介绍了包括说各种数据管线,以及一些下游用法。从性能上似乎不如 Wan2.2。
PLD#
使用残差强化学习收集数据重新训练 VLA
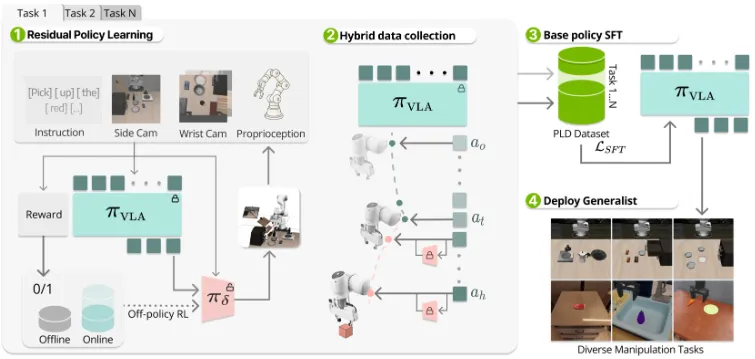
本文提出了 Probe, Learn, Distill (PLD) 框架,通过残差强化学习实现视觉-语言-动作模型的自我改进。该方法分三个阶段:探测基础模型的薄弱环节、收集恢复轨迹数据、将样例蒸馏回模型。从本质上来说 PLD 就是一种强化学习思路,大概就是用一个残差网络来学习 VLA 的残差,并且进行强化学习,之后强化学习完成的数据可以去回流,然后模型重新 SFT。这种思路看上去是很有趣的,按理来说对于主模型来说是存在的一种 offline RL,并且可以收集更多的数据来进行 cross-task co-training,这是传统 VLA-RL 不太擅长的。
不过论文的一些问题也比较显然。看似 PLD 提出了一种数据飞轮,但是实际上只是一种数据增强,毫无疑问的是,PLD 既然是残差学习,因此一定依赖本身的主模型具有一定的性能,也就需要主模型具有一定的后训练数据(在当下的模型泛化能力的视角上来看),因此本身 PLD 从数据角度来看,更多地还是引入了如恢复以及更多的多样性,从而让模型的性能更好,同时可以无限 rollout。另一方面,一些疑惑在于,比如说残差学习和直接 VLA-RL 来 rollout 的区别如何,RL + 数据回流的故事是合理的,但是残差在这里面的效果有多大,似乎也并没有很多的阐述。不过总体而言还是很有意思的论文。
PixelVLA#
引入视觉 prompt 作为提示的 OpenVLA-OFT like VLA
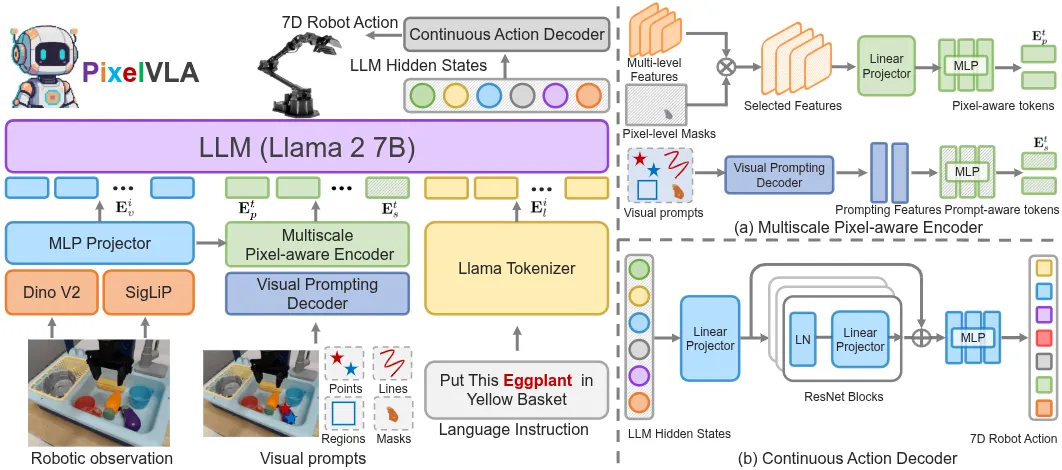
本文提出 PixelVLA,通过增强像素级场景理解和视觉提示能力来改进机器人控制。该模型结合了多尺度像素感知编码和自动生成的 Pixel-160K 数据集(包含像素级标注)。本身 PixelVLA 的结构就是一个 Llama 后面跟上 MLP 来输出 Action,之后输入 vision + text + visual prompt。本身似乎没什么特别的地方,大概是意料之中的模型,中规中矩。
RL-100#
Real World RL 的实践案例
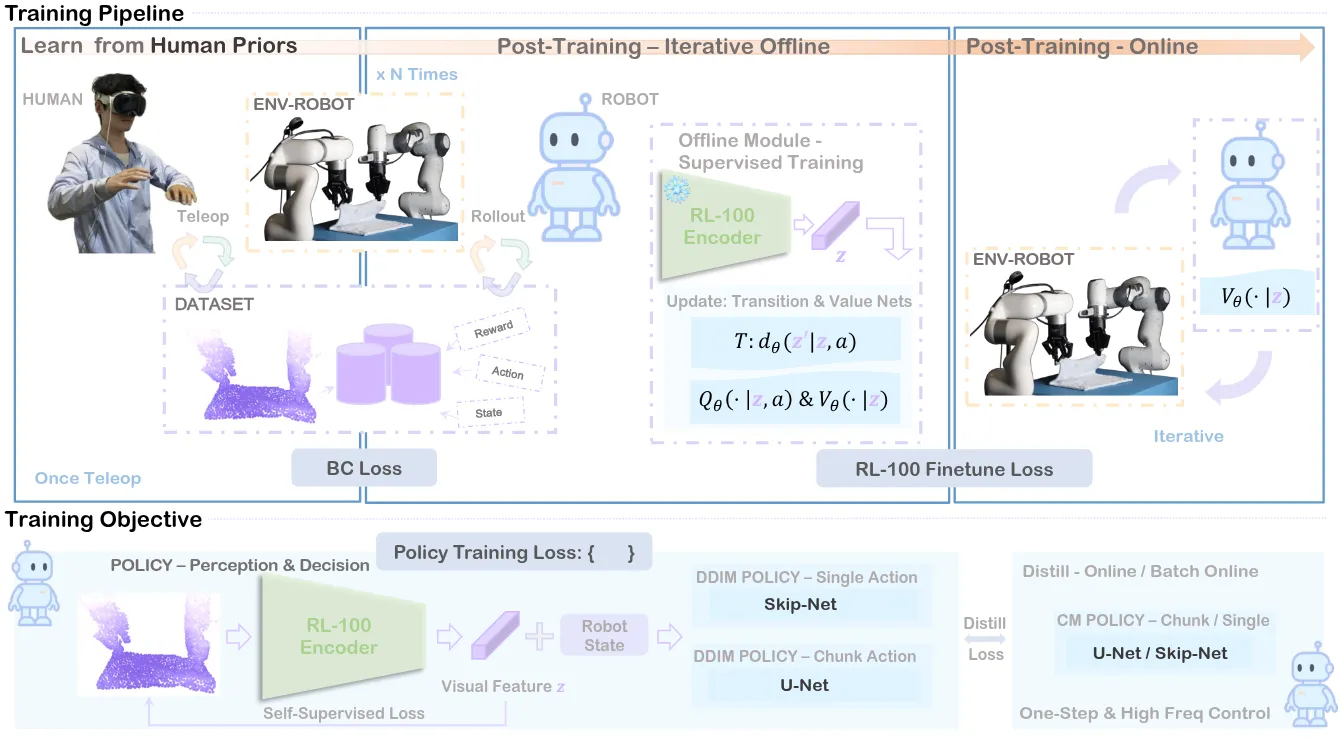
本文提出 RL-100 框架,将基于扩散的视觉运动策略与强化学习相结合用于机器人控制。通过 PPO 风格目标统一模仿学习和强化学习,大概和 使用类似的思路,都是将降噪描述为 MDP 来构建公示。另一个 Trick 是使用一致性蒸馏将多步扩散压缩为单步控制。本身的思路就是对于一个 Task 分为三个环节,先 IL,之后 offline RL,然后 online RL。本身内容没有开源,但是还是挺有意思的。
TWIST2#
全身遥操作的数据收集系统

本文提出 TWIST2,一个可扩展、便携且全面的人形机器人数据收集系统。该系统利用 VR 技术结合定制机器人颈部实现第一人称视角,无需运动捕捉设备即可进行全身控制。本身 TWIST2 就是一个采集系统,大概还是用一个通用运动跟踪 RL 控制器来控制全身,PICO 以及两个腿部 Tracker 来获得位姿。然后用称之为 Holistic Retargeting 的内容来进行重定位,大概就是上半身只对齐了旋转,进行了一些工程妥协。同时似乎还加入了脖子的自由度,对于成功率有帮助。算是还可以的数据采集的 infra 内容。
iFlyBot-VLA#
同时使用 Fast Token 以及 Latent Action Token 的 Pi-like VLA
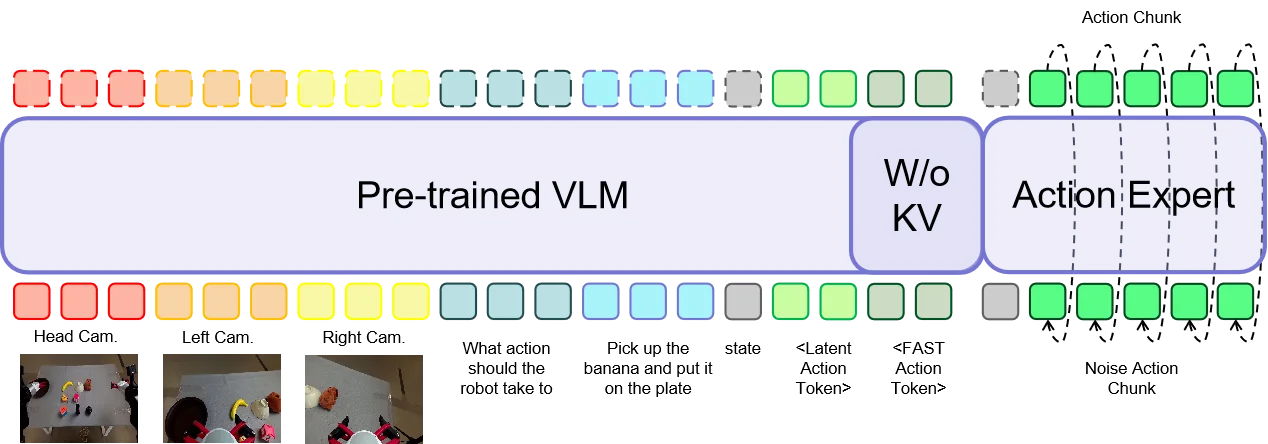
本文介绍 iFlyBot-VLA。本身 iFlyBot-VLA 算是全缝了,也取得了不错的效果。其中 Latent Action 就是 LAPA 故事下的内容,获得 Latent Action,同时使用了 Fast Token,然后以及 Language 的输出,之后用 MoT 的方式接到 Actor 上面(一个细节是不加入 Fast 相关的 KV 部分)。不过还是很好奇不包括 Fast 的原因,似乎本身没有很多的消融。
Isaac Lab#
Isaac Lab 仿真平台

本文介绍 Isaac Lab,作为 Isaac Gym 的继任者,本身是在 Isaac Sim 的基础上搭建的。这篇论文算是一些技术报告相关的内容,介绍了很多的 Feature,包括了很多的实现,以及讲了一些将来的规划,不再赘述。
PhysWorld#
Image to Video to Data 的数据孪生管线

本文提出 PhysWorld,结合视频生成与物理世界重建用于机器人学习。本身的方法也是比较显式的,就是用图片生成视频,以及重建出来一个仿真场景,然后本身用 RL rollout 来生成数据,RL 的 reward 是 follow 操作物体的轨迹,也算是一种 dense reward,算是偏 paper 向的数据管线,本身可以 sim2real。
How Do VLAs Effectively Inherit from VLMs?#
VLA 如何有效继承 VLM 的知识的 Know How
本文探讨了视觉-语言-动作模型(VLA)如何有效继承视觉-语言模型(VLM)的知识用于具身智能控制。本身你论文里面设置了一个很有意思的任务,大概就是 touch emoji 的图片,因为本身 emoji 需要 VLM 的先验以及理解能力,所以说可以很好地进行 study。一些结论在论文中的实验部分给出了,可以详见论文中。在这里概括一些。首先 VLM 的先验是有必要的,毕竟本身上面的任务就需要这种先验,而且本身不然的话,这么大的随机权重也很难 tune 起来;然后 LoRA 或者 Frozen VLM 虽然可以提升 SR,但是容易欠拟合,尽量还是要一起训练;一起训练的问题在于灾难性遗忘,因此 co-training 在里面被验证是有效的。LAPA 类型的 Latent Token 相较于离散 Token 对于训练效果更好。非机器人相关的 VLM 数据也可以 benefit VLA。这些内容基本上也和比如说 InternVLA-M1 的一些结论很一致。算是我很喜欢的类型的论文了,非常不错的 study 类型的 paper。
UMIGen#
UMI + DemoGen 的数据采集管线
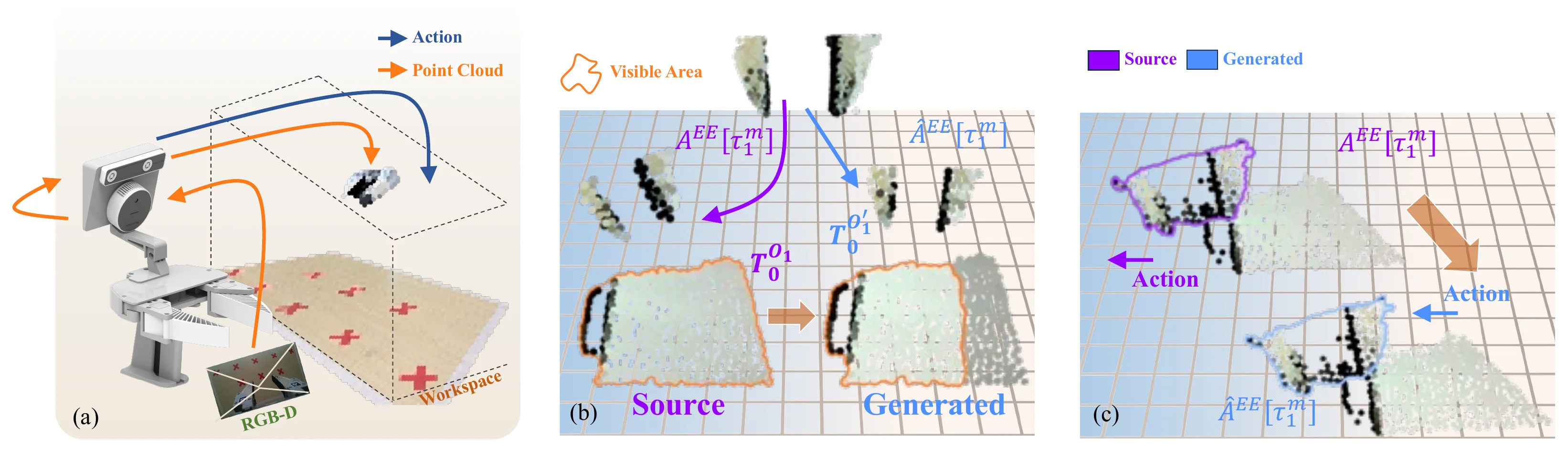
本文提出了 UMIGen,包括 Cloud-UMI 手持数据采集设备(无需视觉 SLAM 技术即可捕获点云和动作对)以及专为自我中心 3D 观察设计的优化机制,在采集了数据之后就可以使用 DemoGen 一样的方式进行数据的大量扰动(也可以称之为生成),之后用于训练。类点云尤其是类 DemoGen 的数据很大的问题就在于依赖 3D 表征,因此难以 leverage VLM 的能力(要不然就需要重新 FT),大概都是以使用 DP3D 作为模型为主,不过本身方法还算是有意义的 A+B。
RoboCOIN#
多平台数据集

本文介绍了一个面向双臂机器人学习的综合多平台数据集,包含来自15个不同机器人平台的超过18万个演示数据。研究团队开发了分层标注体系,涵盖轨迹概念、分段子任务和帧级运动学,并构建了CoRobot处理框架和机器人轨迹标记语言(RTML)用于质量控制和统一数据管理。实验表明该数据集在不同模型架构和机器人系统上均能提升性能,所有资源已向研究社区开源。本身 RoboCOIN 算是一个新时代的 OXE,提供了大量的数据集。当然这其中实验其实有一些问题,比如说我们其实更想要看到一些更加直观的预训练效果,但是似乎论文没有直观回答这个问题,而只是比较了 w/HAI 的提升。同时,RTML 是一个可以评估数据质量的体系,具有参考价值。
AdaptPNP#
古早的 modular framework 思路
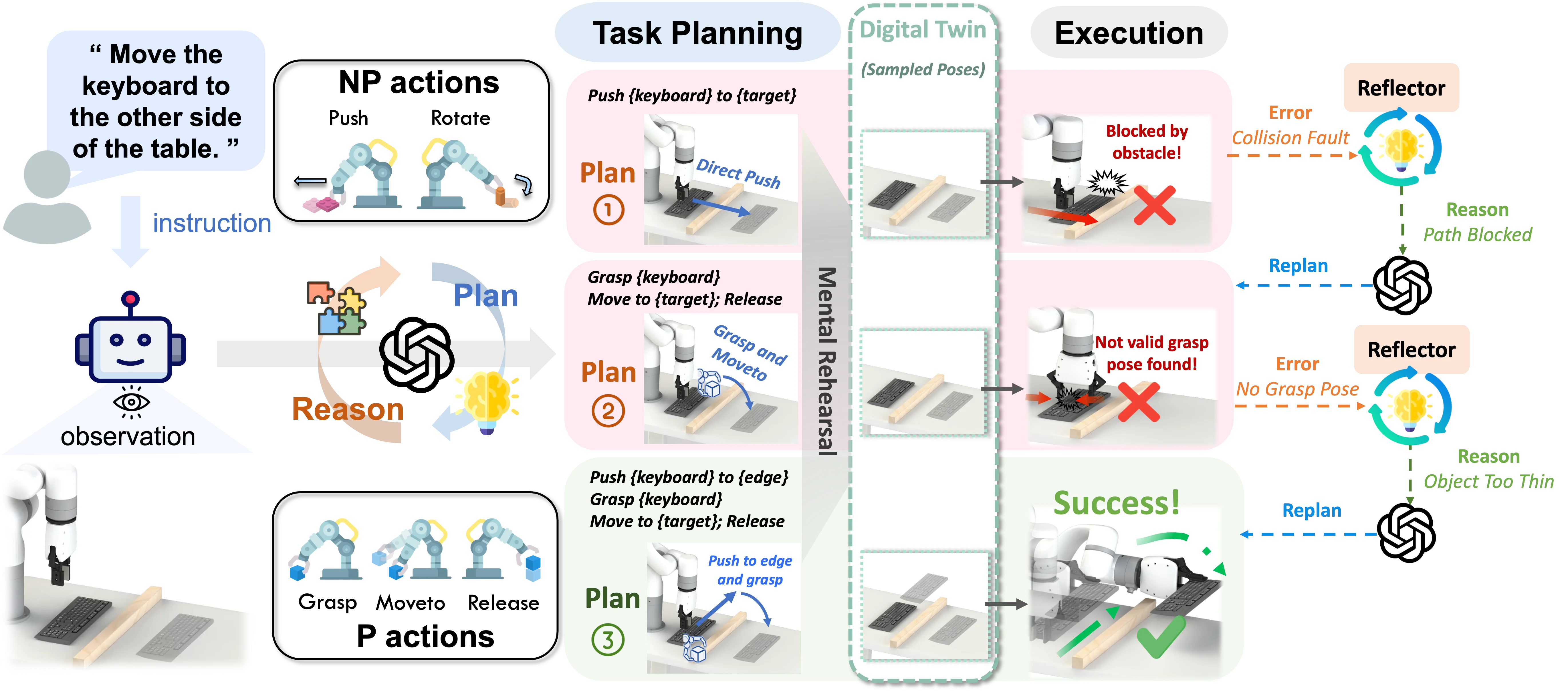
AdaptPNP 本身还是一个 Modular Framework 类型的内容,也就是类似于 OmniManip 的工作。从本质来说,AdaptPnP 并不比 OmniManip 多什么东西,因此在这里简单说一下内容。本身方法设置了若干的原子技能,比如说 Pick(调用 AnyGrasp)以及 MoveTo,然后交给 VLM 进行调度,同时方法是闭环系统,因此可以不断地尝试,从而提高成功率。相对来说和 MOKA 相比引入了 Digital Twin 从而可以处理 3D 的一些操作,但是可以预料的是依然鲁棒性不高。意料之中的 Modular Framework 工作。
RynnVLA-002#
基于 Chameleon 的 VLM + WM + Actor VLA
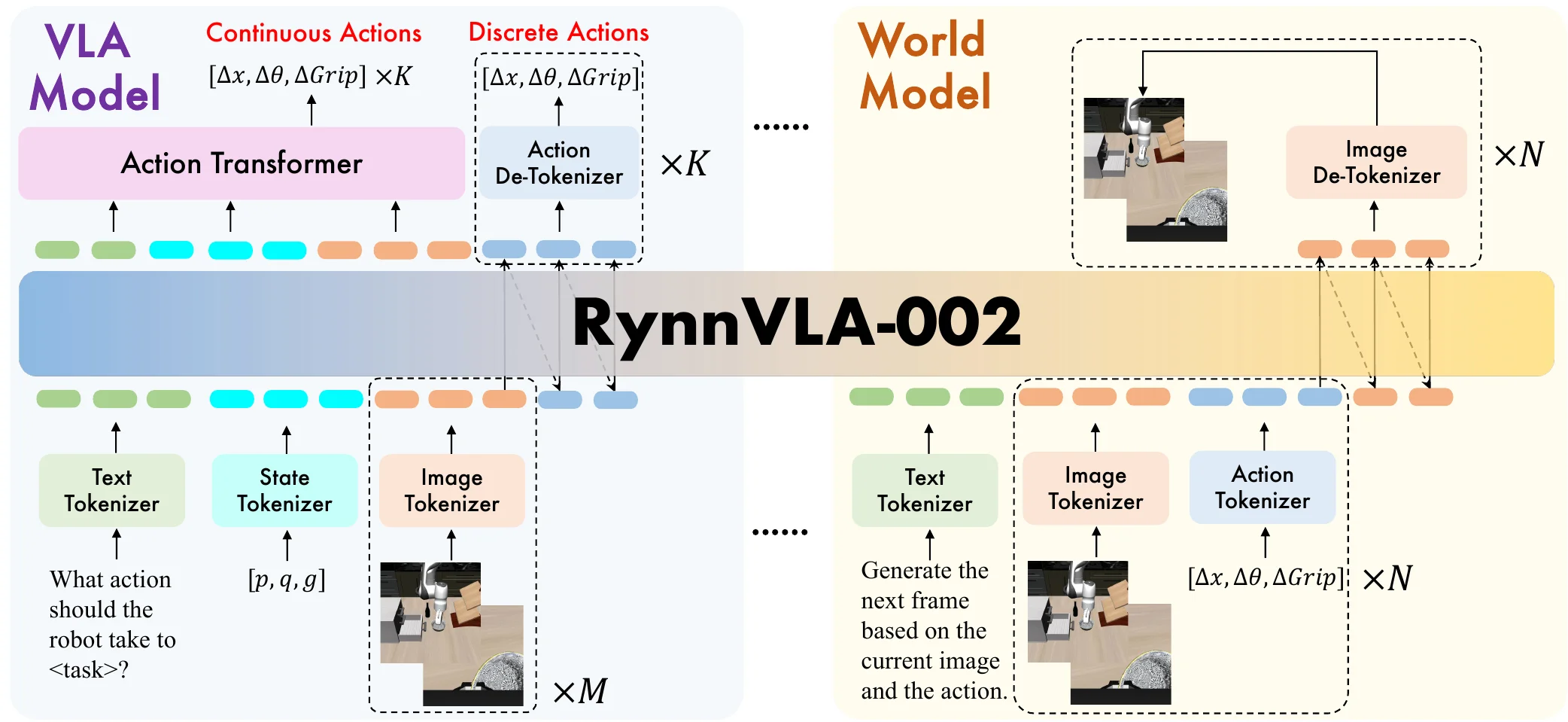
本文提出将视觉-语言-动作能力与世界模型相结合的统一系统,世界模型组件根据动作和图像预测未来视觉状态,VLA组件从视觉输入生成动作。RynnVLA-002 本身基于 Chameleon 这个 Unify 模型训练,也就是可以直接端到端生成图片的 VLM 模型,之后加入了 Action。模型本身同时输出离散 Action,并且 VLA Token 过一个 Transformer 直接输出连续的 Action Chunk,与此同时还预测图片。总体来说算是利用 Unify Model 来训练的意料之中的工作,实验结果中观察到各种预训练(其实就是利用预训练权重)带来的增益,但是本身自己的训练还是局限于后训练,没有给出太多的 insight(其中一些,比如说离散动作加速收敛,结论看上去给的相当草率)。模型本身的性能似乎不高,与之前的 001 似乎也不是在一条故事线上。不过对于想要了解如何将 Unify Model + VLA 走通,似乎是一个可以看一看的工作。毕竟本身相较于视频 WM,Unified 模型可以提供更好的一些 hidden state,这应该是对于整体的性能有好处的。
Motus#
VLM + WM + Actor 的 Pi-like MoT VLA
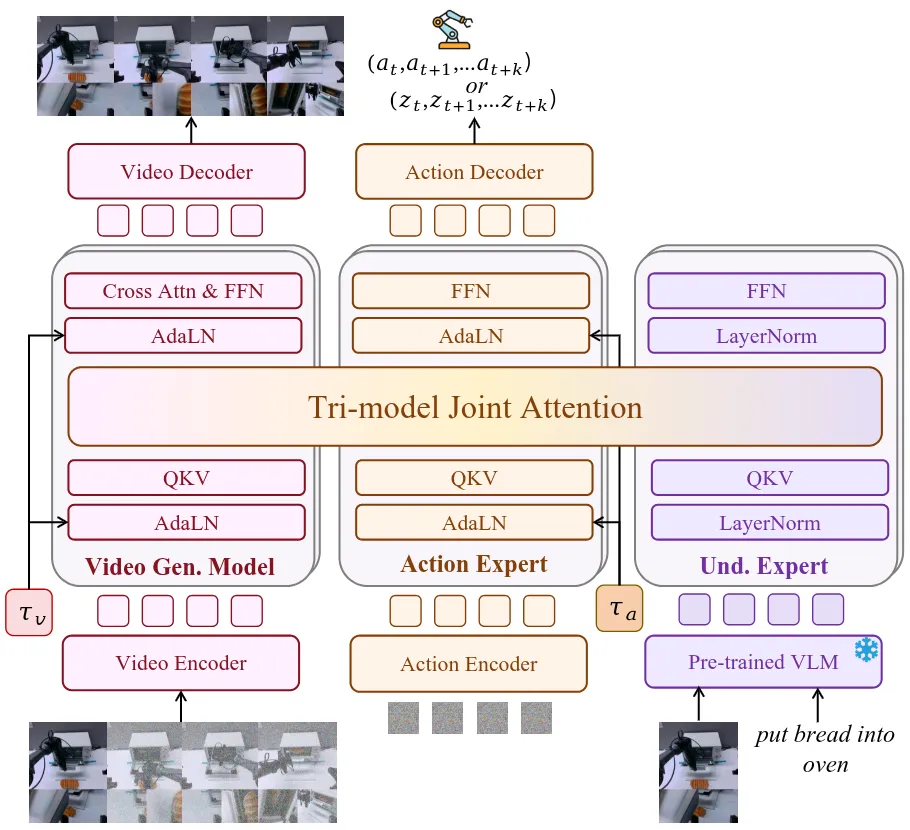
Motus 提出了一个统一的机器人学习框架,将感知、视频预测和控制整合到单一系统中。本身 Motus 做的事情和包括 F1-VLA 以及 InternVLA-A1 相当类似,也就是使用一个 MoT 将 VLM、WM 以及 Actor 一起作为 MoT 去使用。Motus 也使用了比如说 Latent Action 在内的内容,并且构建了自己的数据金字塔,并且有一套自己的训练范式,确实在更广泛的数据上进行了预训练,并且在 RoboTwin2 的 Benchmark 上面结果不错。当然其中还是有一些 Tricky 的点,比如说做低了大多数模型的在 RoboTwin2 的性能,因此只限制到了 40k step,对于他们的训练 Setting,即使用全部的 Clean + Random 数据,甚至跑不完 0.2 个 Epoch,而 Motus 本身的预训练数据中就已经包含了 RoboTwin 的数据,因此获得了更多的训练机会,显然是不公平的。但是总的来说,我其实一直看好 F1-VLA Like 的工作的进一步探索(虽然我不知道为什么他们没有 cite),因为 VLM + WM + Actor 理论上可以 Leverage 到尽可能多的数据,之前 F1-VLA 没有进行这方面的探索,被 Motus 补齐了,而且伴随着不同的 stage 的训练,模型性能还是获得了提升的。总体来说是瑕不掩瑜的佳作。
WholeBodyVLA#
上下肢分离并使用 LAM 的全身 Manipulation
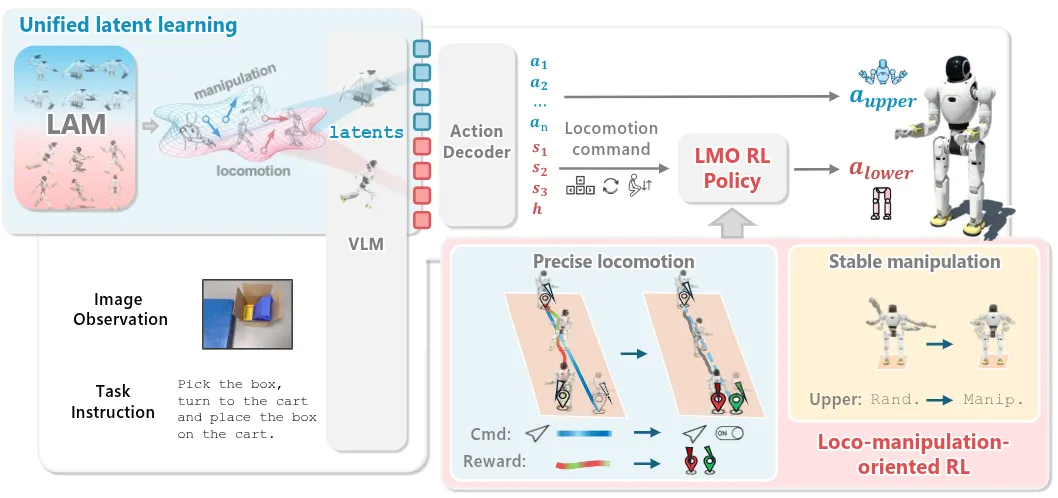
WholeBodyVLA 针对人形机器人全身控制提出了统一的视觉-语言-动作框架。本身还是 follow 了 LAM 的思路,训练了两个 LAM,一个在静止环境,一个在移动操作环境,从大量低成本的无动作视频中联合进行运动–操作学习,然后从而让 VLM 输出 Latent Action,再由 decoder 变为上肢的 Joint Position 以及下肢的动作信号,动作信号大概就是行为级别,需要过一个 LMO 的 RL Policy 才可以变成正常的移动。本身算是比较合理的实现思路,但是并不是大家意料中的,所谓 WholeBody 是一个模型直接高频控制全身。
NORA-1.5#
Pi-like VLA + WM DPO RL 的 VLA
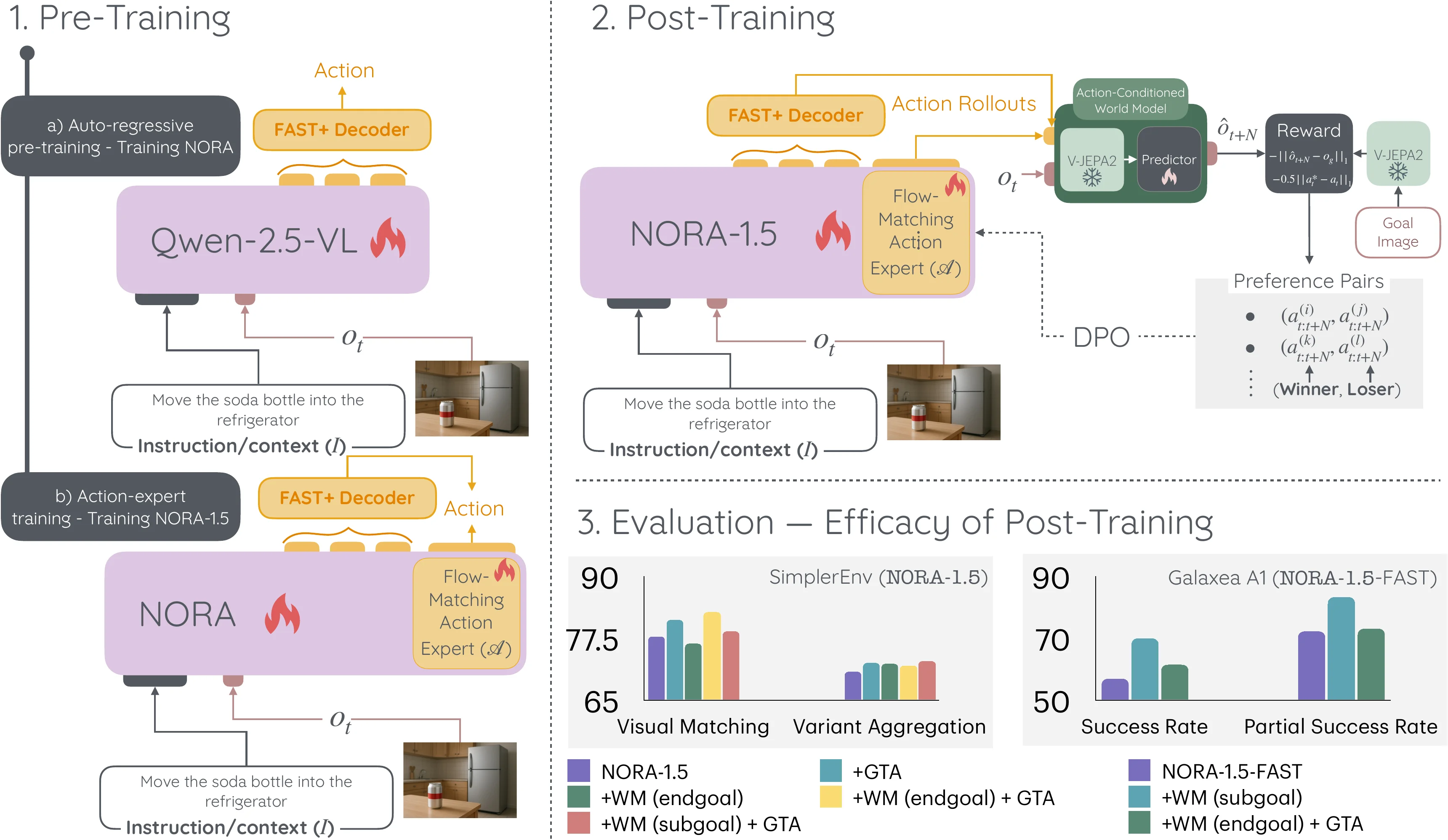
本文提出了 NORA-1.5,一个使用世界模型和基于动作的偏好奖励训练的视觉-语言-动作模型。本身模型训练一共有三个 Stage,首先训练 VLM 输出 Fast Token,之后接一个 FM 然后输出连续 Token 以及 VLM 输出 Fast Token 来 co-training,然后用 DPO 来训练模型。这里的 DPO 的 Reward 包括和 GT Action 的距离,以及 V-JEPA-2-AC 预测下一帧图像来和 GT 图像的距离。NORA-1.5 算是比较少见使用 DPO 的方法,好处是可离线并行生成 preference,也带来了部分的性能提升。
InternData A1#
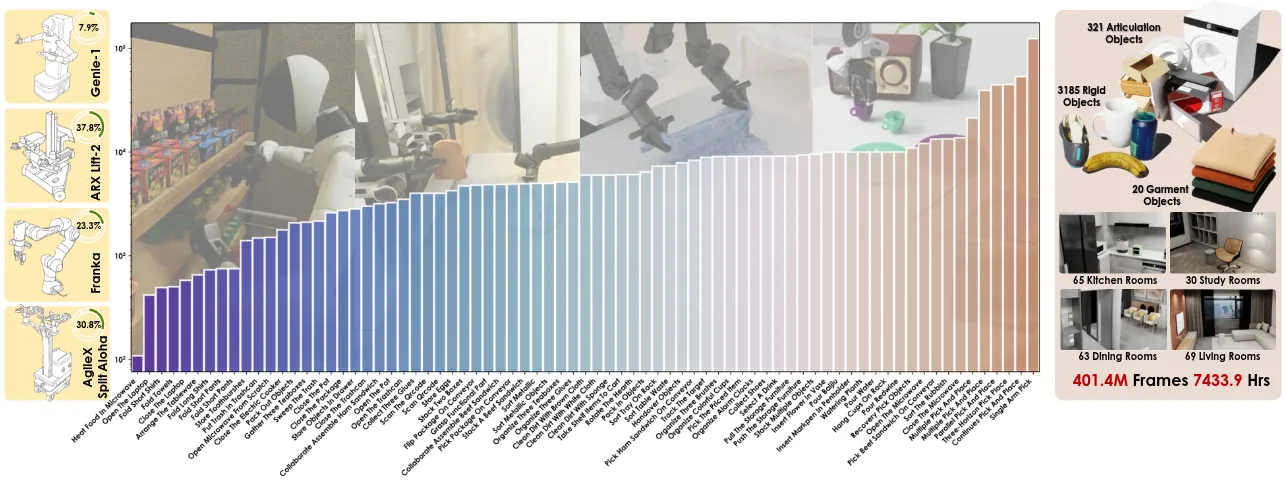
大规模仿真数据管线以及数据集

本文展示了大规模合成数据可以达到与真实机器人数据相当的视觉-语言-动作模型性能。InternData-A1 数据集包含超过 63 万条轨迹和 7,433 小时的数据,覆盖 4 种实体、18 项技能、70 个任务和 227 个场景,包括刚性、铰接、可变形和流体操作。本身 InternData-A1 还是为社区提供了大量优质的数据作为一个数据集,同时还有一个很好的仿真合成管线,这个管线有开源计划。
A1 的数据本身做了两个很不错的 milestone,一个是预训练在一些 Benchmark 上面击败了 Pi0,另一个则是实现了完全的 sim2real 单任务后训练,可以不使用真机数据就有不错的效果。更多的内容我其实专门写过一篇博客,见 这里。总体的结论来说,仿真数据依然展现出来了比较明显的边际效益,A1 大概将其推到了一个不错的 limit,但是继续更进一步也就需要更多的努力了。不过也期待社区后续的 follow up。