
Paper Reading: Embodied AI 8
从一些 Embodied AI 相关工作中扫过。
MergeVLA#
Merge LoRA 进行多任务学习的 Pi-like VLA
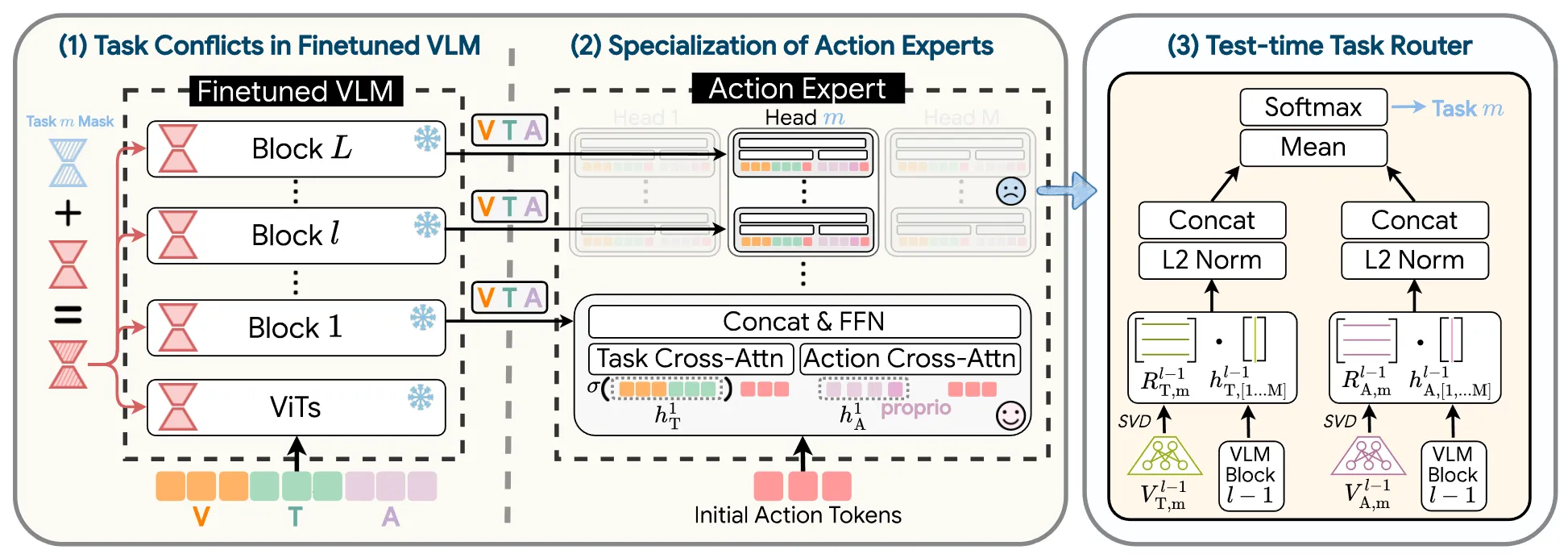
MergeVLA 本身自己设计了模型结构,减去 self-attention 模块,并且把 tanh gate 改成 sigmoid gate,来让表征更加统一,从而对于 Action 这种不同 Task 之间可能有冲突的内容更加 Cross-task align。本身这些设计都是为了后续 Merge LoRA 做准备。本身对于很多的 Task 训练了很多的 LoRA 之后,可以通过若干 Merge 策略来整合,之后在推理的时候,使用一个 Mask 来选择性激活其中的部分参数,这个 Mask 由本来原生的 Task LoRA 和 Merged LoRA 的方向决定。然而对于 LoRA 相关的内容,问题是显然的,为什么要使用 LoRA 以及为什么要 Merge。毕竟事实上,目前大多数的 VLA 可以直接进行 Co-training,效果上也不错;而假如说我想要某一个 Task 的效果好,我直接训练这一个 Task 的 LoRA 就已经可以了,把不同的 Task 的 LoRA 混合在一起可以 Benefit 本身这一个 Task 的效果吗,论文中没有给出非常充分的解释。使用 LoRA merge 来进行一个类似于可持续学习的故事是说不通的,毕竟人间正道还是训练一个 co-training 基模,之后直接训练小 LoRA,对于多任务,直接手动 Route 加载对应 LoRA 就好。
Compressor-VLA#
通过减少计算量和视觉token数量来提高 VLA 效率
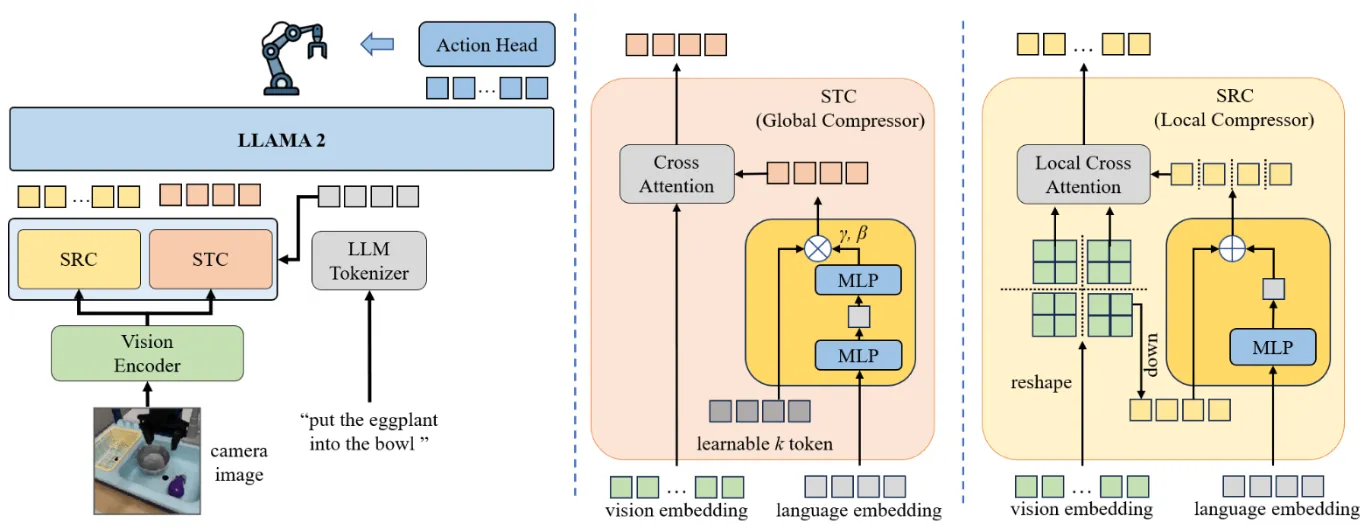
Compressor-VLA 本身目的就是削减 Vision Token 输入到类 OpenVLA 模型的数量,从而优化效率。本身通过一种 Language-condition 的方式来选择,且不说这样会不会损失细粒度信息,而只保留语义,从而带来可能得性能开销。这种方法似乎与 VLA 也没什么关系,放到任何模型都可以,思路也没什么意思。
VIPA-VLA#
使用人手数据进行空间预训练的 Pi-like VLA
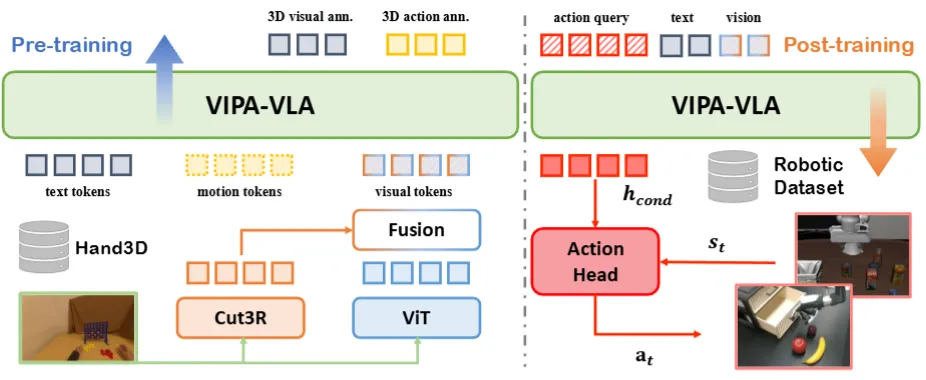
VIPA-VLA 如图中所示,还是一个 VLM-VLA 的一个惯用的范式,也就是先使用一些 VQA 的所谓 Grounding 或者空间感知的数据进行预训练,然后之后在机器人数据中进行后训练。本身这里的故事可能偏向于使用 human data,但是确实使用的是 annotated 的数据,并且最后的用法也是作为 VQA 去使用,相对来说的意义就不是特别大。然后说回具体的内容,就是用 Human Data 组成了一些 VQA,之前在 Human 的预训练环节里面,输入人类的轨迹以及 Vision 和 Text,其中 Visual 里面用了一个 Cut3R 的 embedding 来增强一些可能的空间能力,然后和 ViT 进行 Fusion;到了后训练,就是正常的 VLA in A out 的设计。本身中规中矩,并没有给如何利用广大的 human data 一个好思路。
Openpi Comet#
如何将 Pi0.5 的 VLA 在 BEHAVIOR 挑战赛上进行工程优化
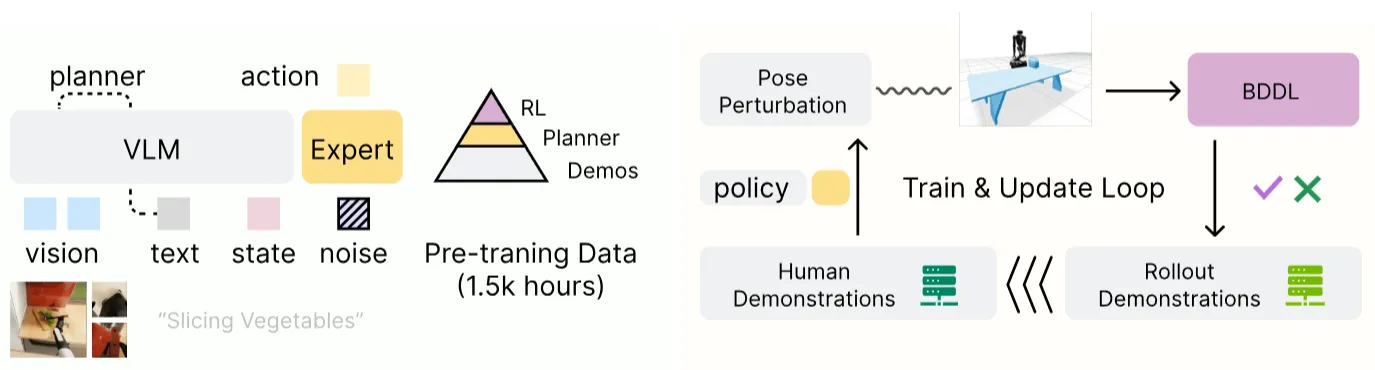
Openpi Comet 是 2025 BEHAVIOR 挑战赛的亚军方案,基于 进行了一个工程优化,可以说还是很有 insight 的。本身 BEHAVIOR 挑战赛是一个非常困难的挑战赛,并且第一名使用了一个很复杂的优化,但是相较而言,第二名的方案相当直接,并且很有启发性。具体来说,Comet 本身首先进行了 RFT 的 rollout,所谓 RFT,其实也就是将模型部署在仿真里面,然后闭环 rollout 数据,再用 rollout 的数据来训练,因为本身 bddl 可以检验成功,所以说可以有天然的验证器来筛选成功数据。然后之后的训练的过程中进行了消融,有一些关键结论。首先是对于控制,还是要尽量把每一次的轨迹都执行完,也就是所谓的 Temporal Horizon 的策略,而不要用 Action Ensemble 策略之类的;然后在这个情况下,Action 长度需要适中,因为太短会抖而且监督少不好学,太长的话闭环周期很长;然后输入模态只需要 RGB,不需要点云或者深度;分辨率输入的时候大一些好。本身还是很有意义的报告,很不错。
Evaluating Gemini Robotics Policies in a Veo World Simulator#
基于 Veo3 实现的 WM Simulator 方案以进行 VLA 评估

这篇论文由 Gemini 提出,旨在使用 Veo3 作为 WM Simulator 来评估 Gemini 的机器人策略。本身 Veo3 就是一个 Action-WM,之后在机器人数据上进行了一些训练。WM Simulator 很大的问题一直在于,如果本身 WM 在此之前没有经过大量的训练,或者说之后容易灾难性遗忘,那么很难做好诸如精细操作等内容,因为模型的训练数据中大多数的操作都是偏向于成功的,那么很有可能在作为 Simulator 的时候,就容易直接让物体“吸附”在手上从而强行成功。为了某个任务强行采样似乎也是不可持续的,这一现象在此之前的其他论文放出的 Demo 中我们经常可以看到,Veo3 这篇似乎并没有提出解决方案,比较遗憾。当然其还是一贯表现了 WM 的好处,也就是可以 Zero-shot 生成一些 unseen 的场景,并且进行评估。
VideoVLA#
同时预测 Action 和未来的 Image 的 DiT
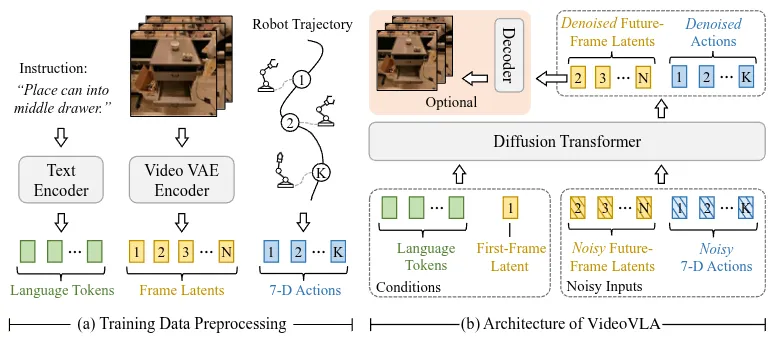
VideoVLA 的方法比较直接,本身就是基于 CogVideoX-5B Pretrain 的 DiT 模型,然后同时预测两种类型的 token,一种是由 Video Encoder 编码的 Image token,另一种则是 Action。本身从效果上来说并不是很显著,不过也算是正在利用 Video WM 搭建 VLA 的一种尝试了,类比的话有点像是 OpenVLA,本身的动作嵌入方式不是很合理。
Video2Act#
基于 Video WM 的 Pi-like VLA 模型
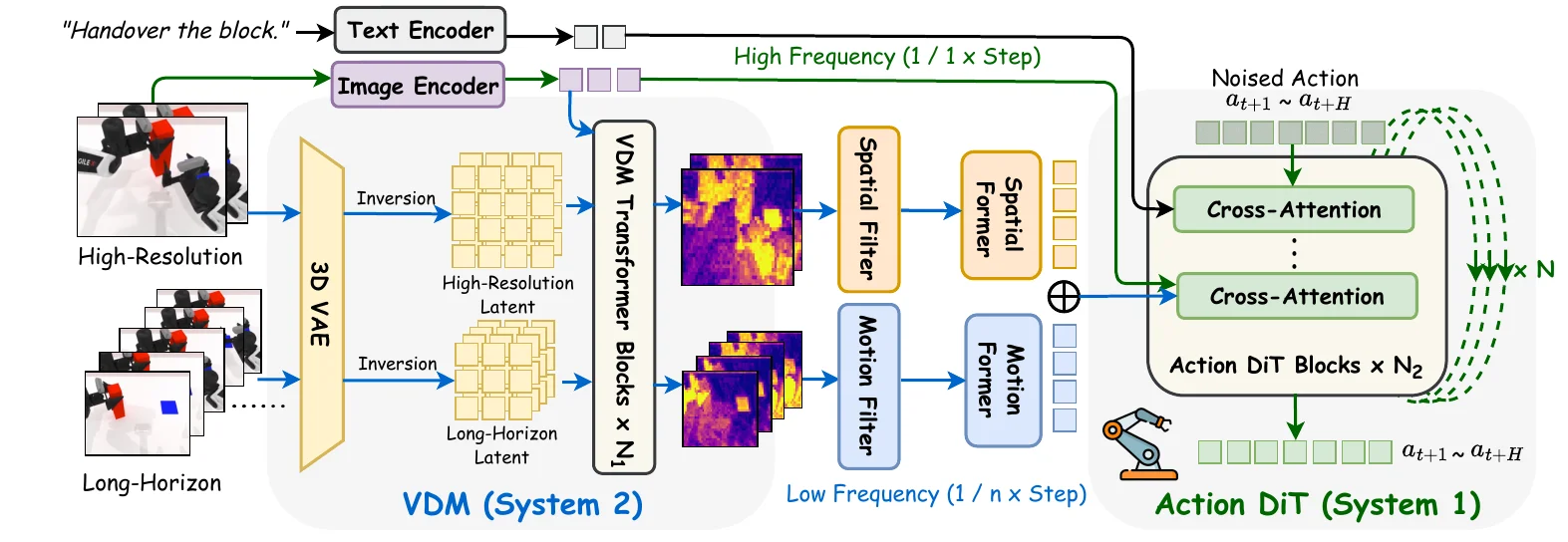
Video2Act 如图中所示,从本质上来说其实是一个 Video WM 加上 DiT 的 Pi-like 范式。本身输入包含高分辨率图像以及长程图像两种,都经过 Hunyuan 作为 Encoder 并且把其中的 hidden state 和单帧过 image encoder 的 feature 进行 concat 作为 condition,然后由 DiT 预测 Action。本身其实思路还是比较偏向于传统的 Policy,只是使用了大模型,然后也是比较经典的高精度与长时序的双路信息输入,从性能上来说不算突出。
RealAppliance#
包含 100 个家电资产的数据集

RealAppliance 包含 100 个家电资产,并且其交互方式与家电本身的说明书一致,算是不错的资产数据集,如果仿真存在相关的需求,是可以参考并且使用的。
GR-RL#
Pi-like VLA + RL 的范式
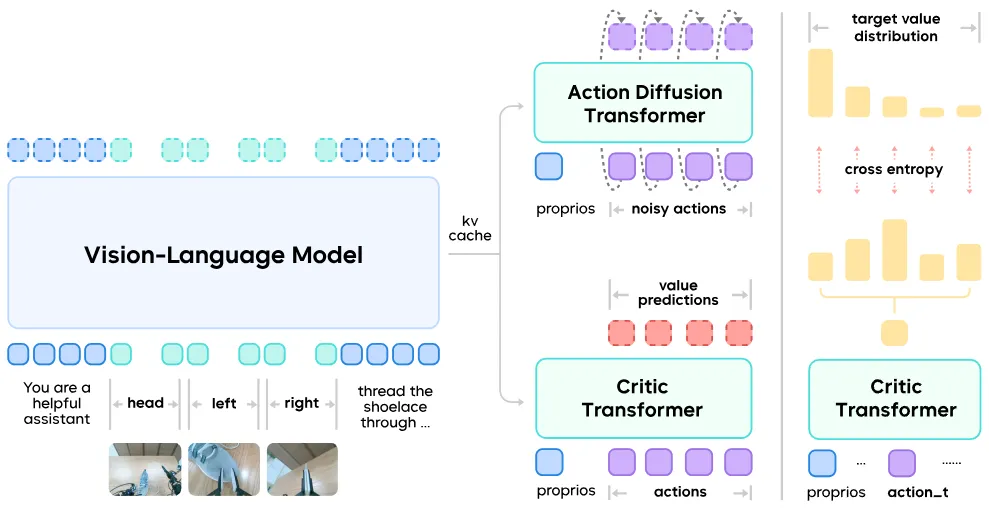
GR-RL 整体就是两阶段的训练,然后来完成最后的任务。首先对于第一阶段,其实就是如图所示的,依然是 Follow 了 GR-3,也就是使用 Qwen 的 MoT 来做 Action 预测。对于数据来说,他们用 TD3+BC 来训练了一个评论员来给进度打分,从而可以筛掉数据里面的无意义部分,之后就用比较好的数据进行第一波的训练。之后对于在线的强化学习,本身因为 DiT 难以直接 RL,所以其实各家都是各显神通,比较典型的见之前的 ,对于 GR-RL 来说,他们的策略就是训练一个噪声预测器,本身的 RL 施加给这个噪声预测器,这个预测的噪声可以直接输入给 DiT。从结果上来看在线调优还是有好处的,虽然其实我认为这种没有直接对 DiT 的优化可能相对有限,但是至少可以作为一个补充。
ManualVLA#
使用 Janus-Pro 作为 Backbone 来用图像 CoT 的 Pi-like VLA
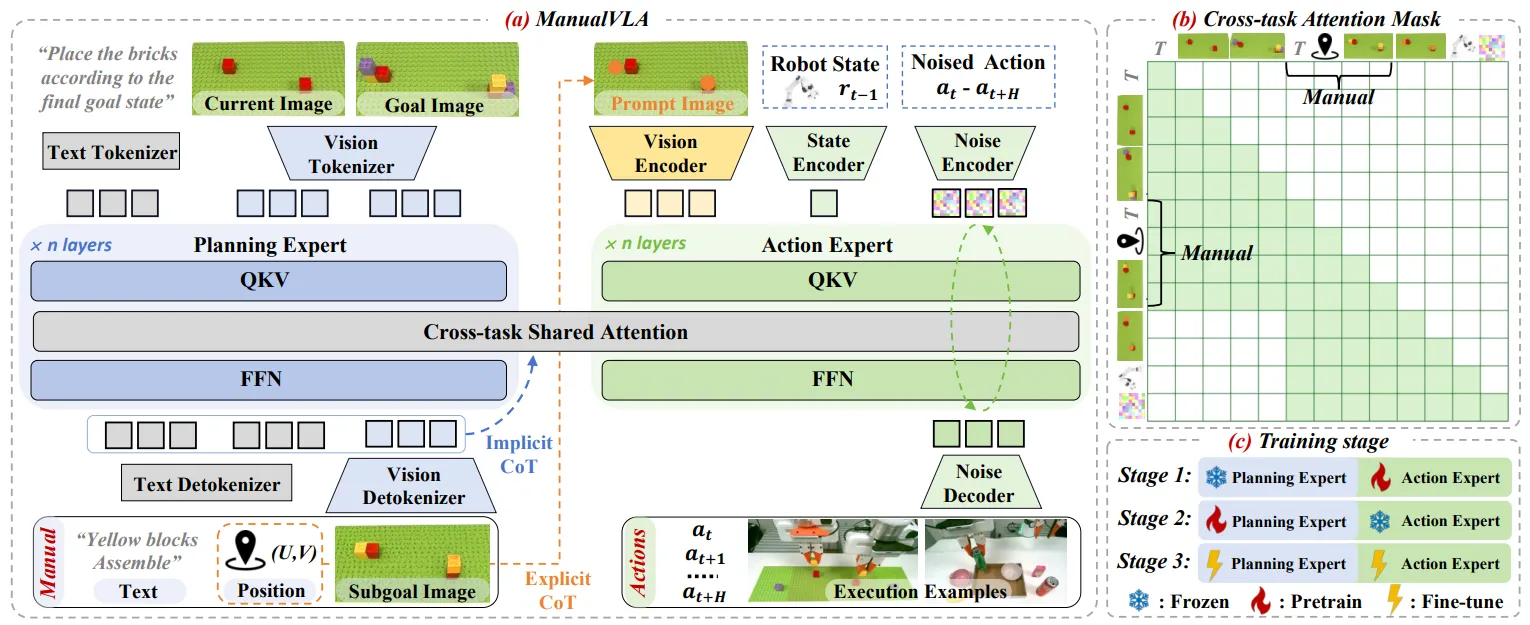
ManualVLA 本身也是采用了 Pi-like 的结构。本身 ManualVLA 采用了 Janus-Pro 作为 Backbone,而 Janus-Pro 是一个非常典型的 Unified 模型,也就是本身模型可以输出 Image Token 来直接生图,所以说 ManualVLA 利用了这个特性来达到,输入 Goal Image,先 CoT 一个 Subgoal Image,之后再用 Subgoal 输入来预测 Action。本身的思路很直接,类似于之前的 CoT-VLA 的思路。
不过个人感觉使用 Unified 模型来作为 Backbone 可能意义也不大,因为毕竟本身也不是训练在时序上,对于预测未来这个事情可以做到的还是相当有限;同时虽然 goal image 是一个有效的输入,但是本身带来更多视觉细粒度的信息,其实感觉对于任务完成的意义也不是特别大(本质上我们在期望模型拥有一种闭环直到 Obs 和 Goal 一致的能力,但是实际上理解这个闭环并没有那么简单)。
MM-ACT#
基于 dLLM 的 VLA
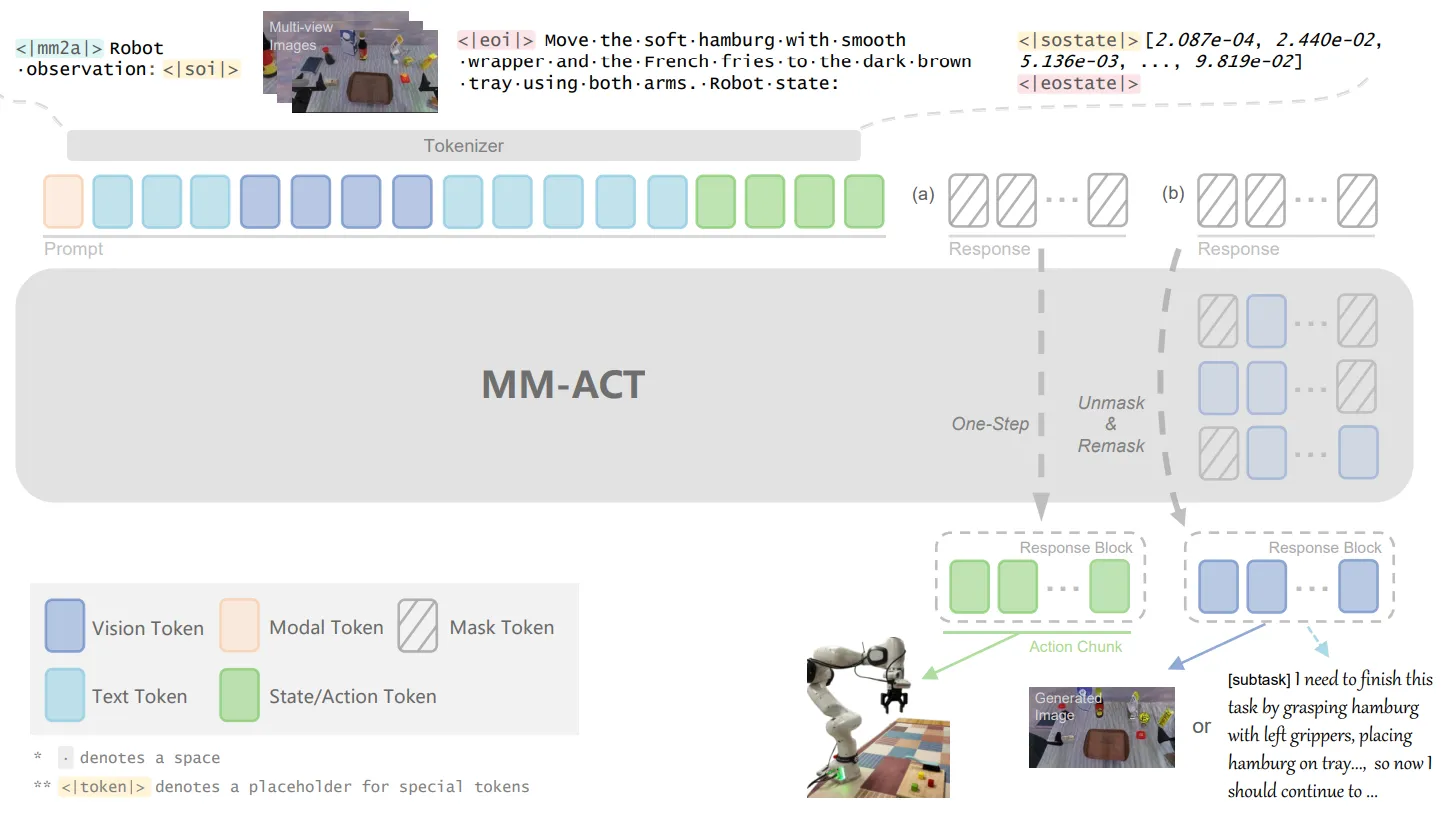
MM-ACT 本身基于 LLaDA 的模型以及 Show-o 的 Encoder,达到可以生成图像或者文本,同时也可以直接生成 Action,通过不同的特殊 Token 来区分三种不同的任务。本身类似的做法和 dVLA 之前看上去比较类似,然后本身在训练方法中,对于语言就是正常训练,图像是补全一些 Mask 的部分,然后 Action 是预测。从结果上来看中规中矩,并没有很显著。
VLA-Arena#
具身通用 Benchmark
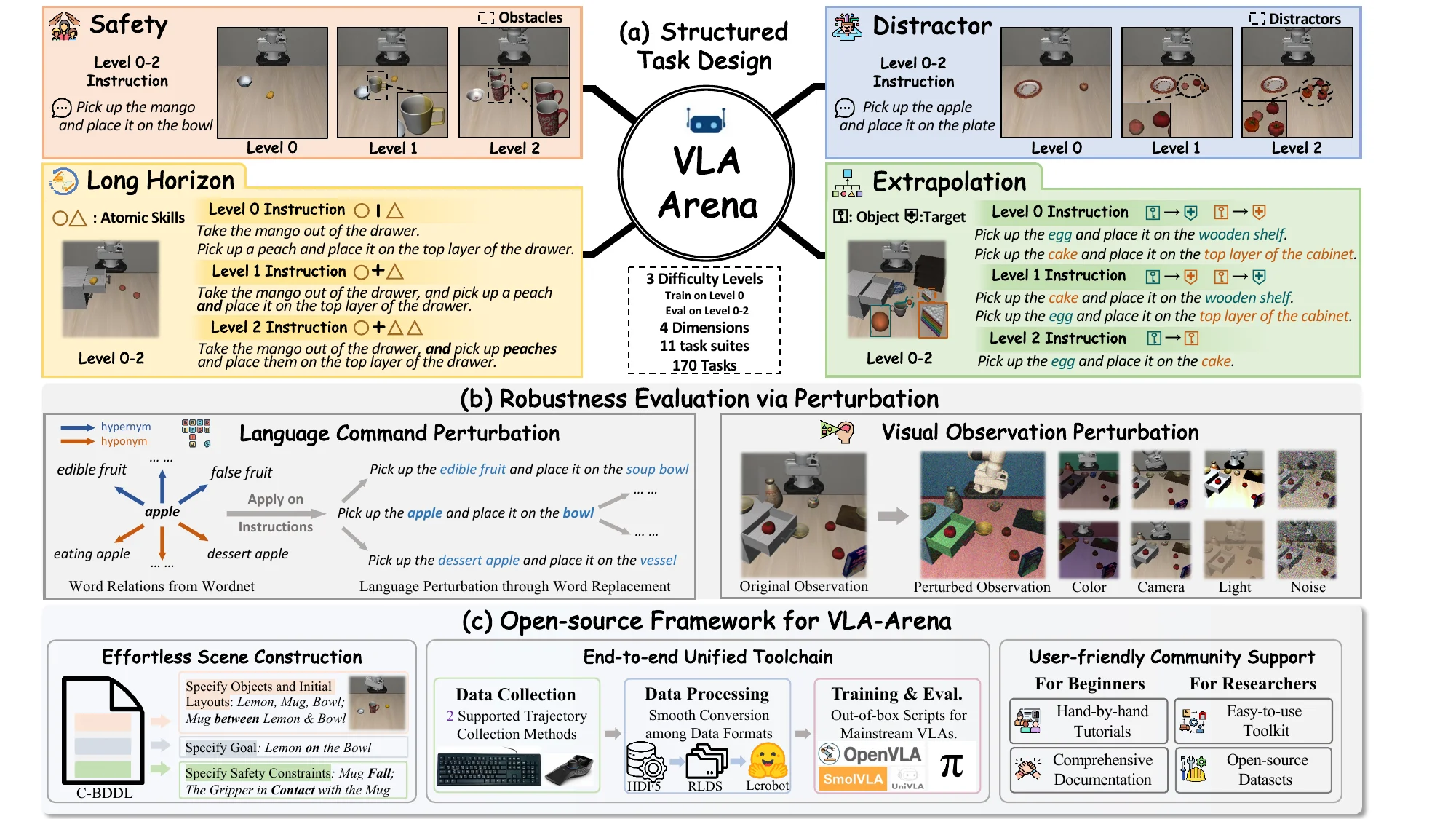
VLA-Arena 本身应该是基于 RoboSuite 的套件创建的 Benchmark,本身从视觉上看上去和 LIBERO 比较相似,考察了安全、干扰项、外推法和长时程的维度,但是本身来说长程这方面相当有限,比如说把东西放到柜子里这种级别。本身 Benchmark 还是提供了不少的 Baseline,性能目前也不算很高,所以说还是可以尝试的。
Robo-Dopamine#
具身通用奖励模型以及配套 RL 框架
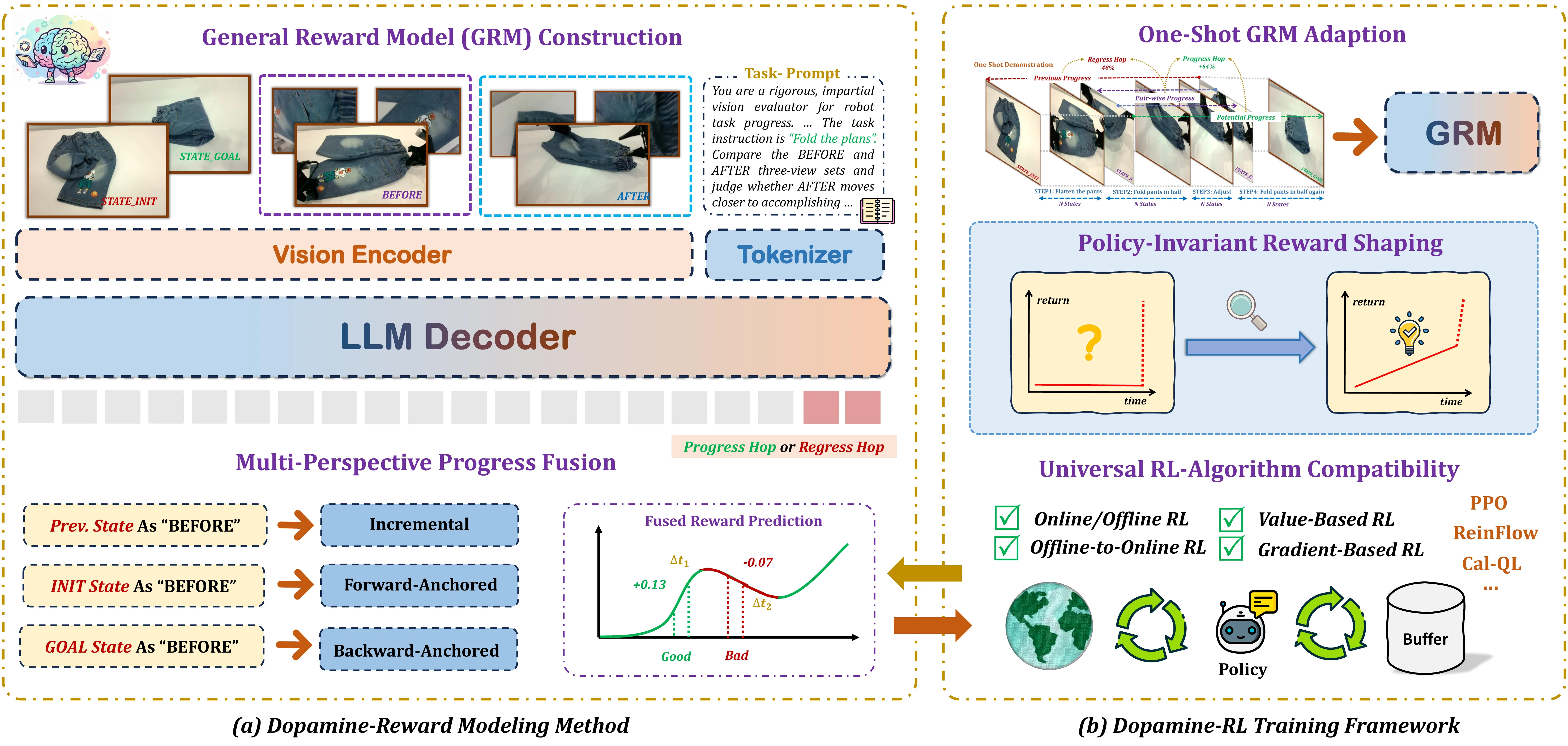
本身文章提出了 Dopamine-Reward,一种基于 3400 多小时数据训练的通用奖励模型,本身可以预测相对的进度变化,从而可以使得离线和在线 RL 可以运行;同时论文提出了 Dopamine-RL 框架,本身基于 Dopamine-Reward 来训练一个 RL 的策略。本身这里面可能稍微有一些 insight 的在于,分解了三个指标,分别是增量预测,也就是历史与预测之间的增量;前向锚定是起始的时候是 0;反向是结尾是 1。在训练的时候本身通过同时预测这三个量,他们之间本质上是同一趋势的,来表示综合的进度。本身论文的思路还是比较直接的,没什么问题。
Sim-and-Human Co-training#
利用仿真和人类数据之间的互补性来训练 VLA
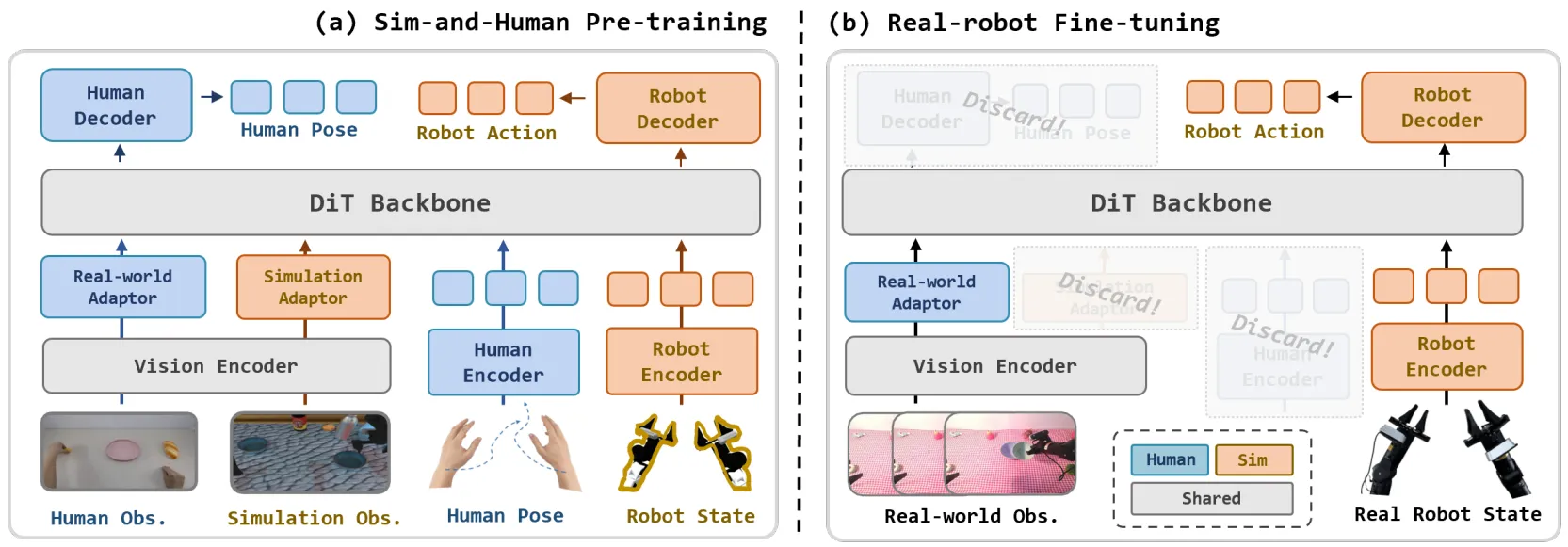
本身的文章意义不是很大,探讨 Co-training 人类和仿真数据,其实没有什么参考价值,不过因为笔者没有太读过如何 leverage human data 的文章,这篇算是一种可参考的范式,本身这里的仿真数据也可以换成比如说真机的灵巧手数据。本身就是采用两阶段训练,预训练的时候同时输入人类和机器人的 Obs 以及 State 预测两边的 Action,然后在后训练的时候 discard 掉人类的,而只使用机器人的数据,进行传统的后训练。本身中规中矩,没什么问题。
DuoCore-FS#
双系统 VLA
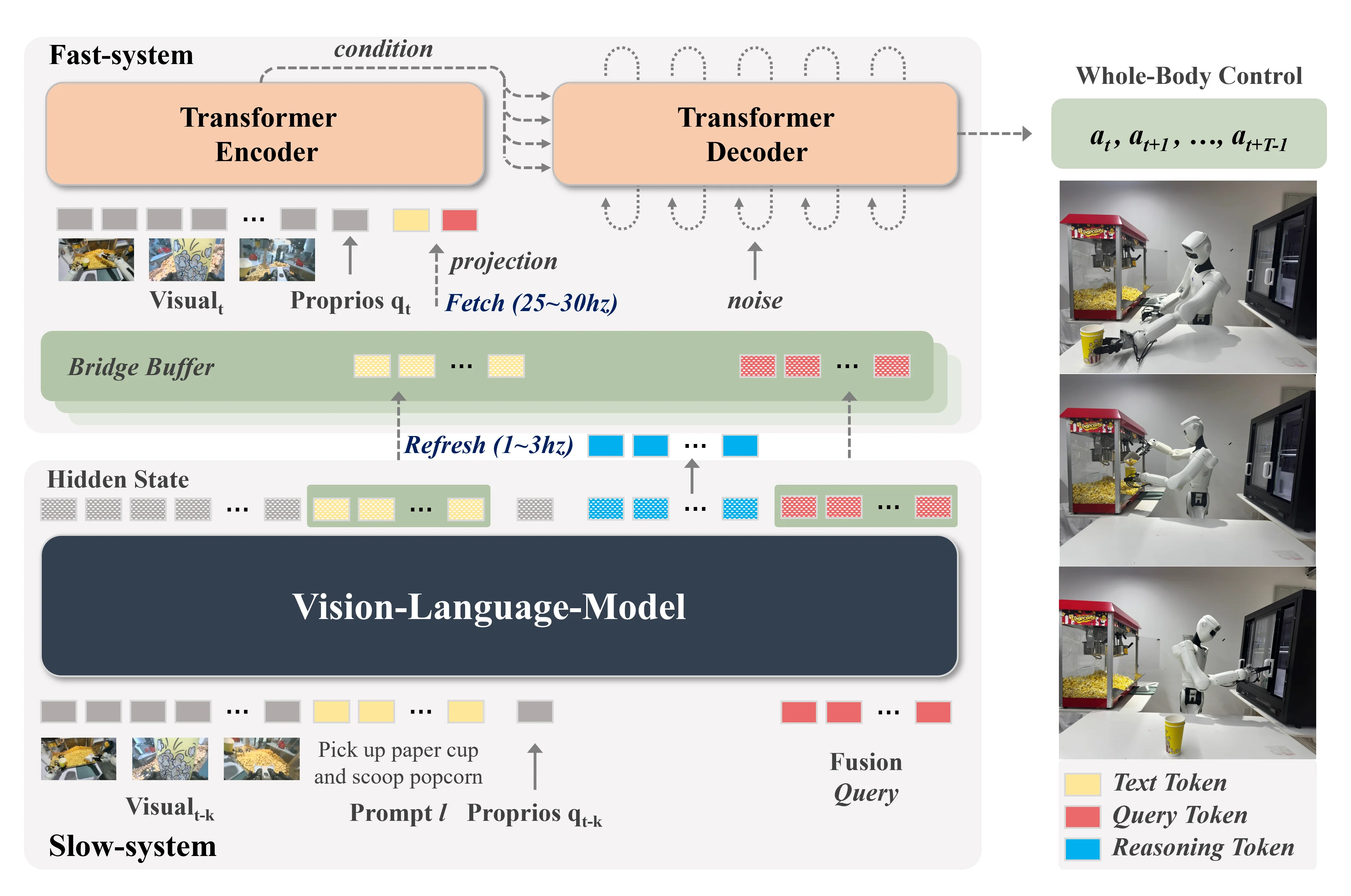
DuoCore-FS 算是比较标准的异步双系统 VLA,本身上游是一个 VLM,下游是一个 DiT + 一个用来 Fusion 全部的上游信息变成统一 Condition 的 Transformer,然后 Condition on DiT 来输出 Action。从结果上来看特调下和 Pi-0 相似,可以说平平无奇,本身使用 Transformer 一下子 Fusion 全部的 condition 也不是少见的做法。
Dream2Flow#
Modular 的 Video to Flow to Action 工作
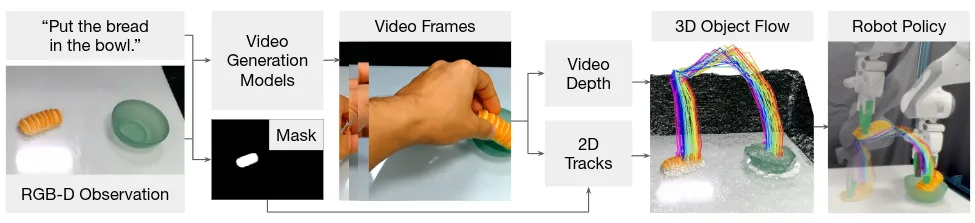
Dream2Flow 的 Motivation 是 Leverage Video Generation Model 的 Zero shot 能力,不过本身从结构以及实现方式上来说神似两年前的 Im2Flow2Act,本身也算是他们比较喜欢的模块化方案,没什么问题。
Genie Sim 3.0#
仿真基础平台
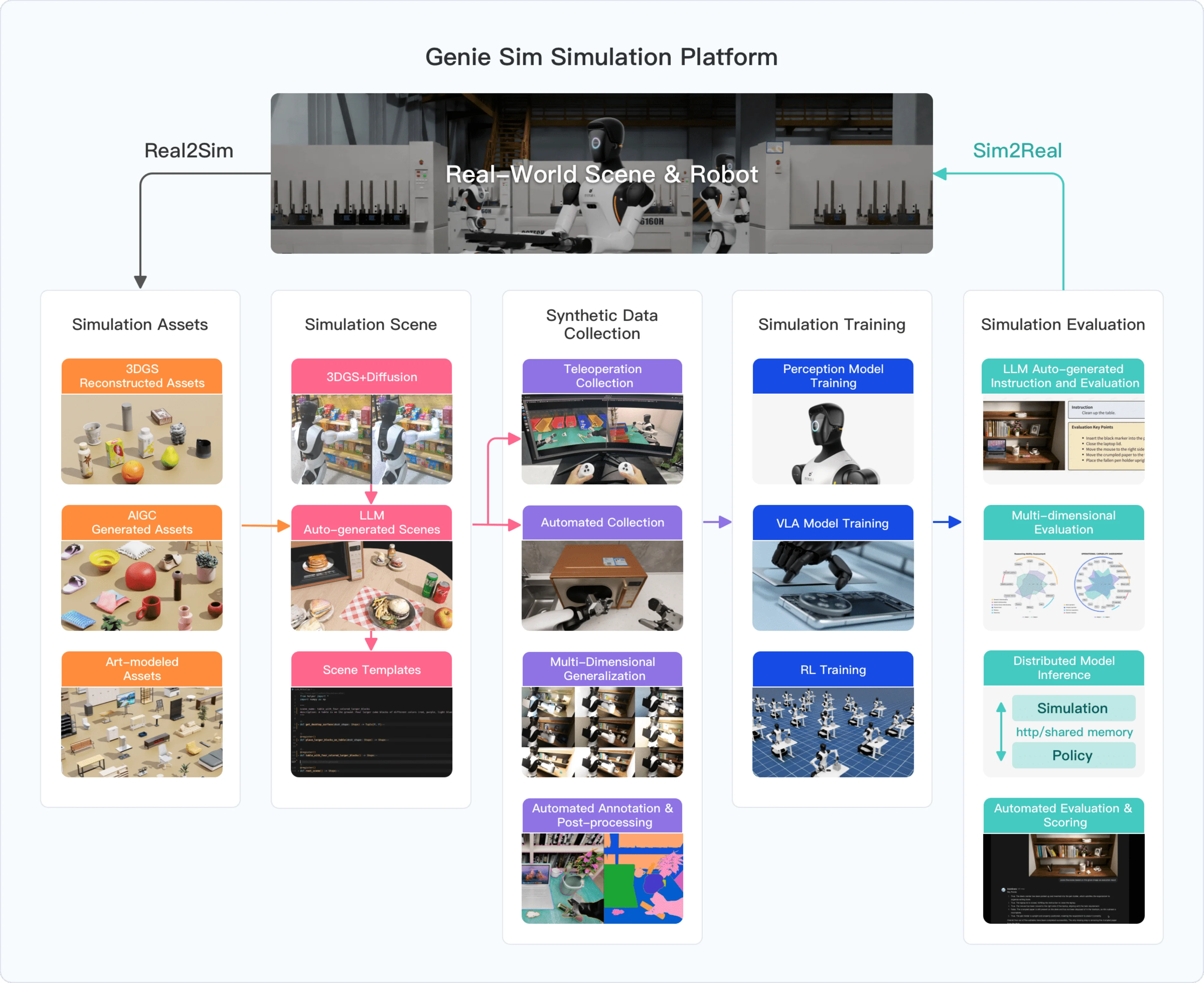
Genie Sim 3.0 是智元机器人的仿真基础平台,包括了测评以及数据生成相关的内容,算是比较大型的基建内容,不过从内容上似乎数据生成乏善可陈,同时文档可读性一般。不过本身看上去 scope 还是很大的,而且确实做了不少的 dirty work,未来可期,很有价值。
InternVLA-A1#
VLM + WM + Actor 的 MoT VLA
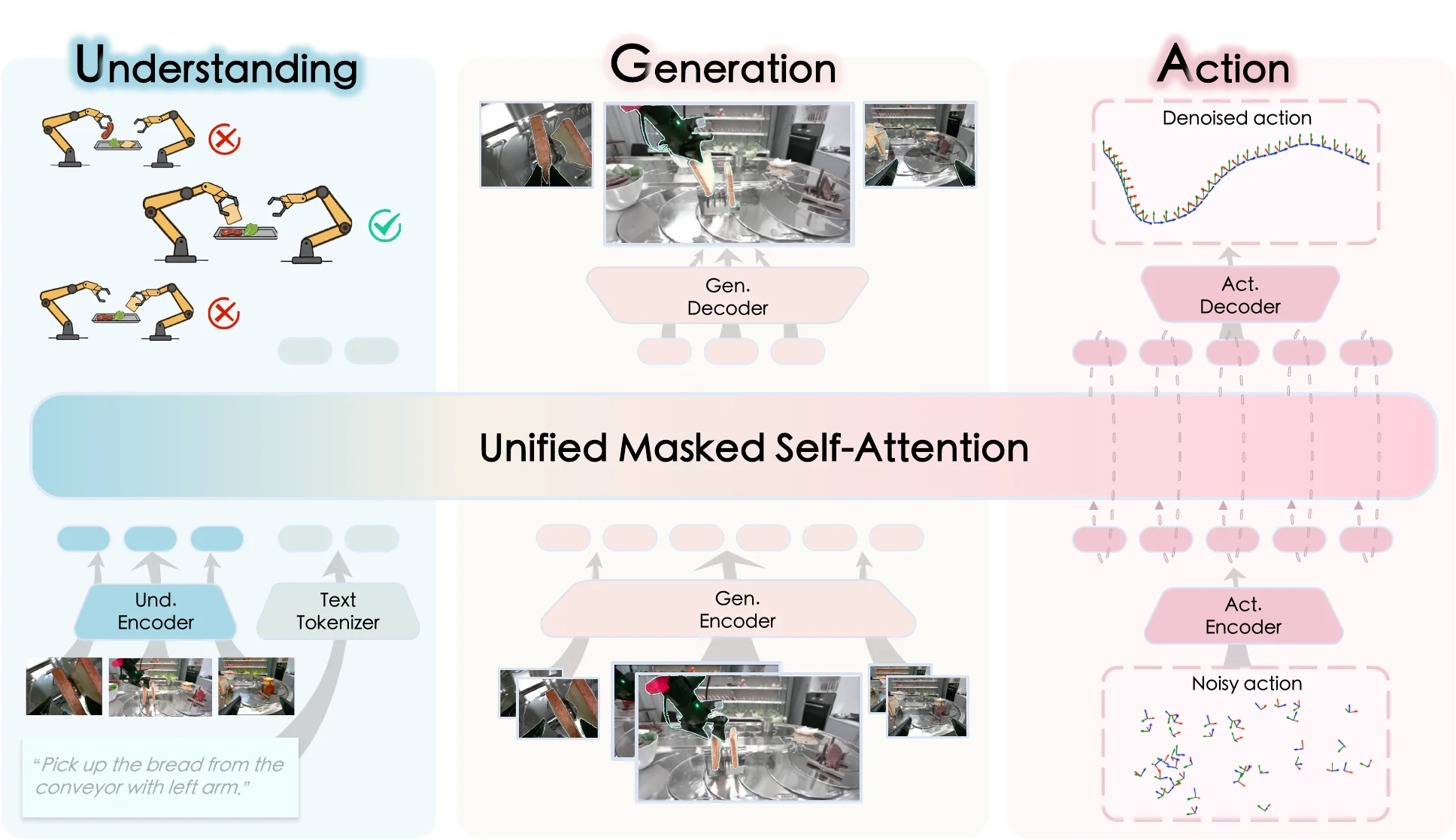
InternVLA-A1 本身思路与之前的 F1-VLA 类似,使用 VLM + WM + Actor 的 MoT 来作为模型结构,在预训练数据中主要使用的是 InternData-A1 以及 Agibot-World 的数据,本身其实依然没有比如说 Leverage 更多的 VLM 或者 WM 的数据来一起训练,不过从结果上确实很不错,这篇论文也算是 WM-VLA 类型论文中比较有代表性的工作了。
CLAP#
使用对比学习创建 latent action 的 VLA
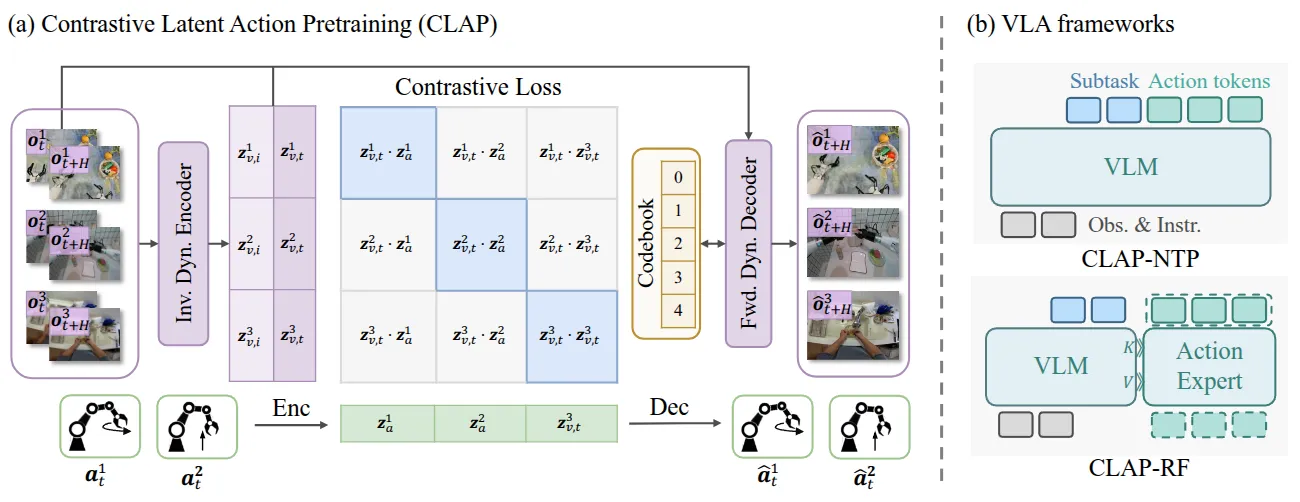
CLAP 从本质上与之前的诸如 LAPA 以及 UniVLA 都比较类似,其核心在于如何学习 Latent Action。CLAP 的做法分为两个部分,首先直接用 VQ-VAE 对于全部的 action 创造 codebook,称之为 Act-VAE。然后之后对于图像输入,也构成一个 VAE,其中分为两路,一路和 Act-VAE 的进行 SigLIP 损失,从而代表 Action,另一路则和这一路合在一起作为恢复的输入,代表无关的环境扰动。如此训练出来的 latent action 可以从人类数据中提取表征,之后一起预训练模型,然后投入到两个构型(其实也就是本博客经常提及的 OpenVLA-like 以及 Pi-like 的构型)的 VLA 里面去训练。从结果上人类数据的增幅大约 11 个点,不能说十分显著,但是至少是有效增幅。总体上还算做的比较有趣,值得一看。
Fast-ThinkAct#
将 CoT 蒸馏为 latent token 的高效 Reasoning VLA
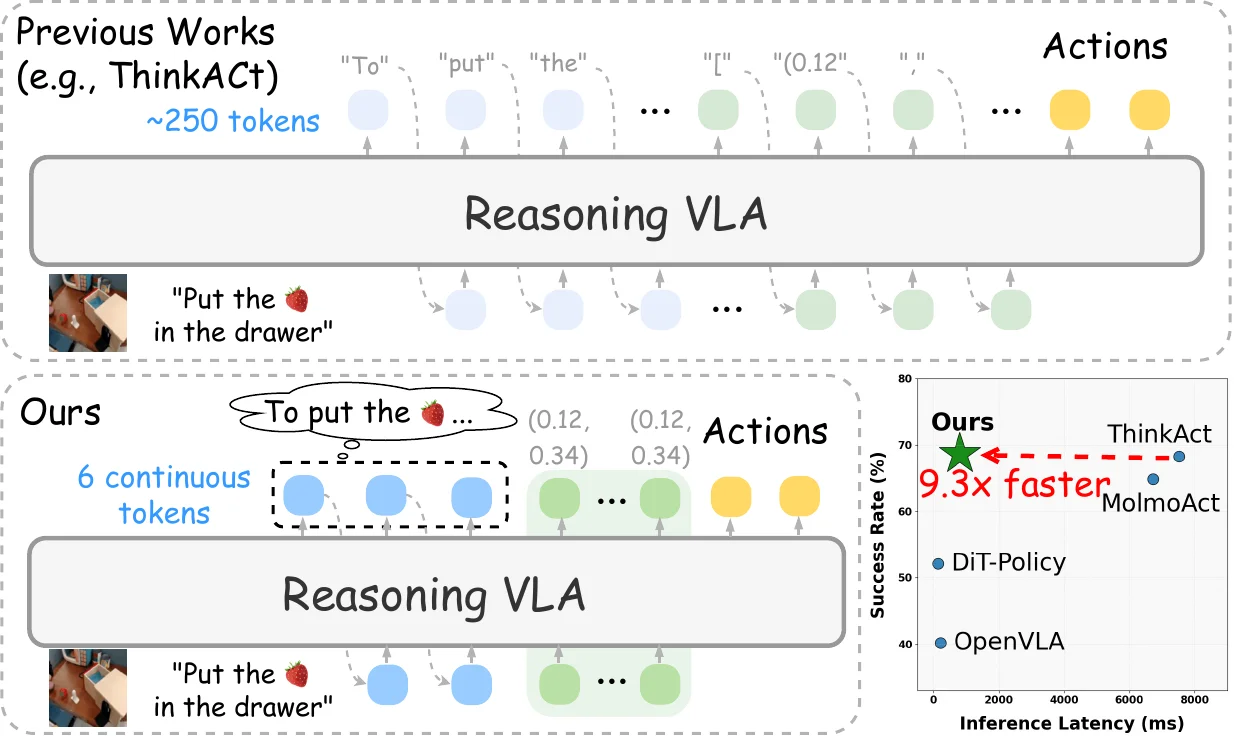
Fast-ThinkAct 本质上是 ThinkAct 的效率版本,核心在于解决 Reasoning VLA 里面显式 CoT 带来的推理延迟过高的问题。整体分为三个部分,首先是一个用 GRPO 训练的 Textual Teacher VLM,用来产生显式的推理轨迹;然后 Latent Student VLM 把推理压缩到约 6 个 continuous token 加上若干 spatial token 上,通过 L2 对齐 hidden state 来做 Visual Plan Distillation;最后还有一个 Verbalizer,把 latent 解码回文本,同时基于 GRPO 的 advantage 从 rollout 里挑出正负样本对,用 DPO 损失去训练 latent,让 latent 本身可言语化,保留可解释性。下游则接一个 Diffusion Policy。本身其实算是把 VLM 那边压缩 CoT 的技术部署过来了,中规中矩。
The Great March 100#
主打任务分布长尾的 100 个真机操作任务 Benchmark
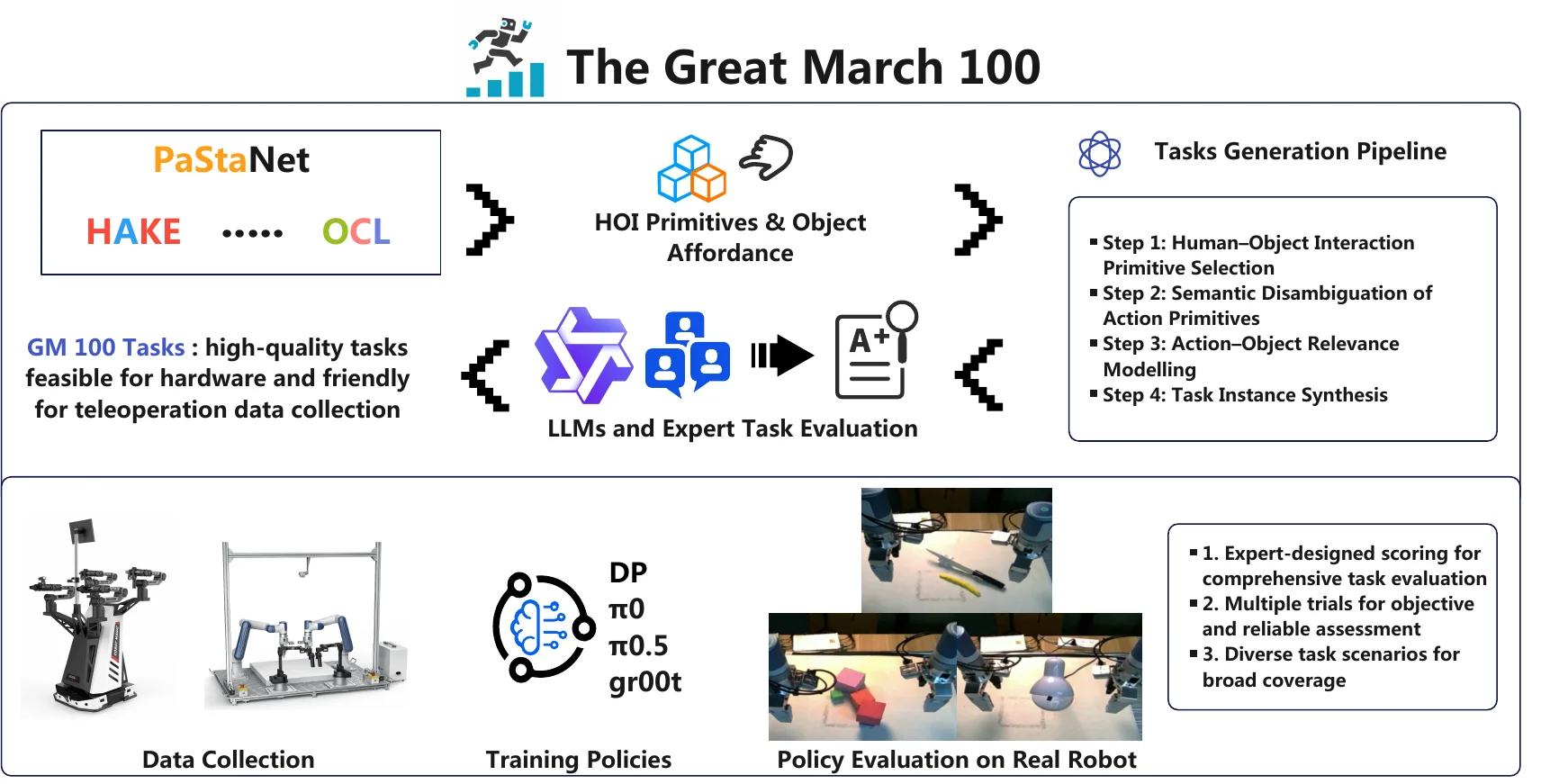
GM-100 从 Agibot、OXE 等数据集里收集已有任务并去重,和 LLM 做语义扩展,人工筛选判断可行性,最后实例化为 100 个任务,在 Agilex Cobot Magic 和 Dobot Xtrainer 两个平台上采集了 13K+ 真机遥操作轨迹,本身算是蚂蚁的内部评测工具链条,似乎并不提供公共服务,不过本身没问题,很 solid。
FRoM-W1#
LLM + VQ-VAE Motion Tokenizer 的开源人形 WBC 框架
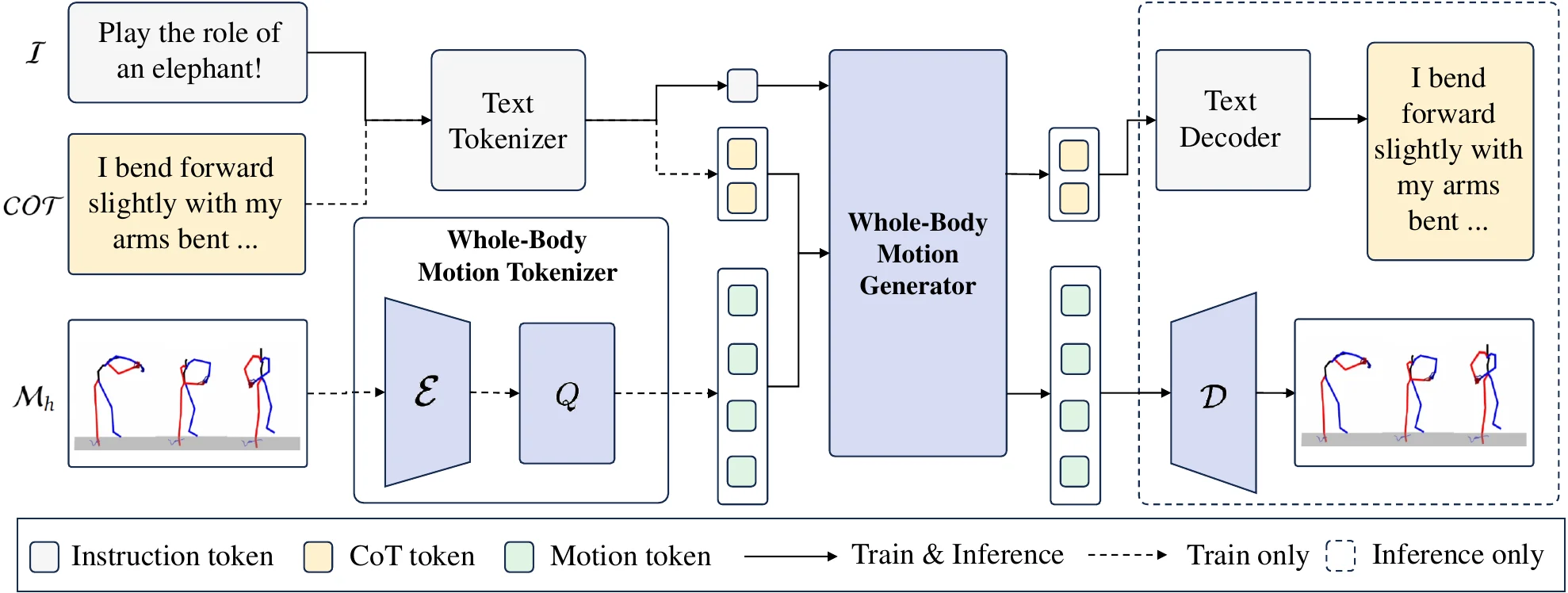
FRoM-W1 本身算是一种全身控制的框架,本身就是提出了所谓的 H-GPT,思路也比较简单。H-GPT 用 LLaMA-3.1 + VQ-VAE 把 SMPL-X motion 离散化成 token 与语言对齐,自回归生成;H-ACT 做 retargeting + RL 把人类动作迁到机器人关节。这一套 LLM + motion tokenizer + RL 的范式 MotionGPT、T2M-GPT 都做过,也算是比较经典的方法了。不过从本身的角度来说,这种对齐的意义可能不是很大,因为确实很难对于一个姿势或者一段时间不长的姿势引申出某种明确的语义信息。不过在协同优化之下还是可以 work 的,这是可以想象的。
Being-H0.5#
使用了大量预训练数据混合训练的 Pi-like VLA
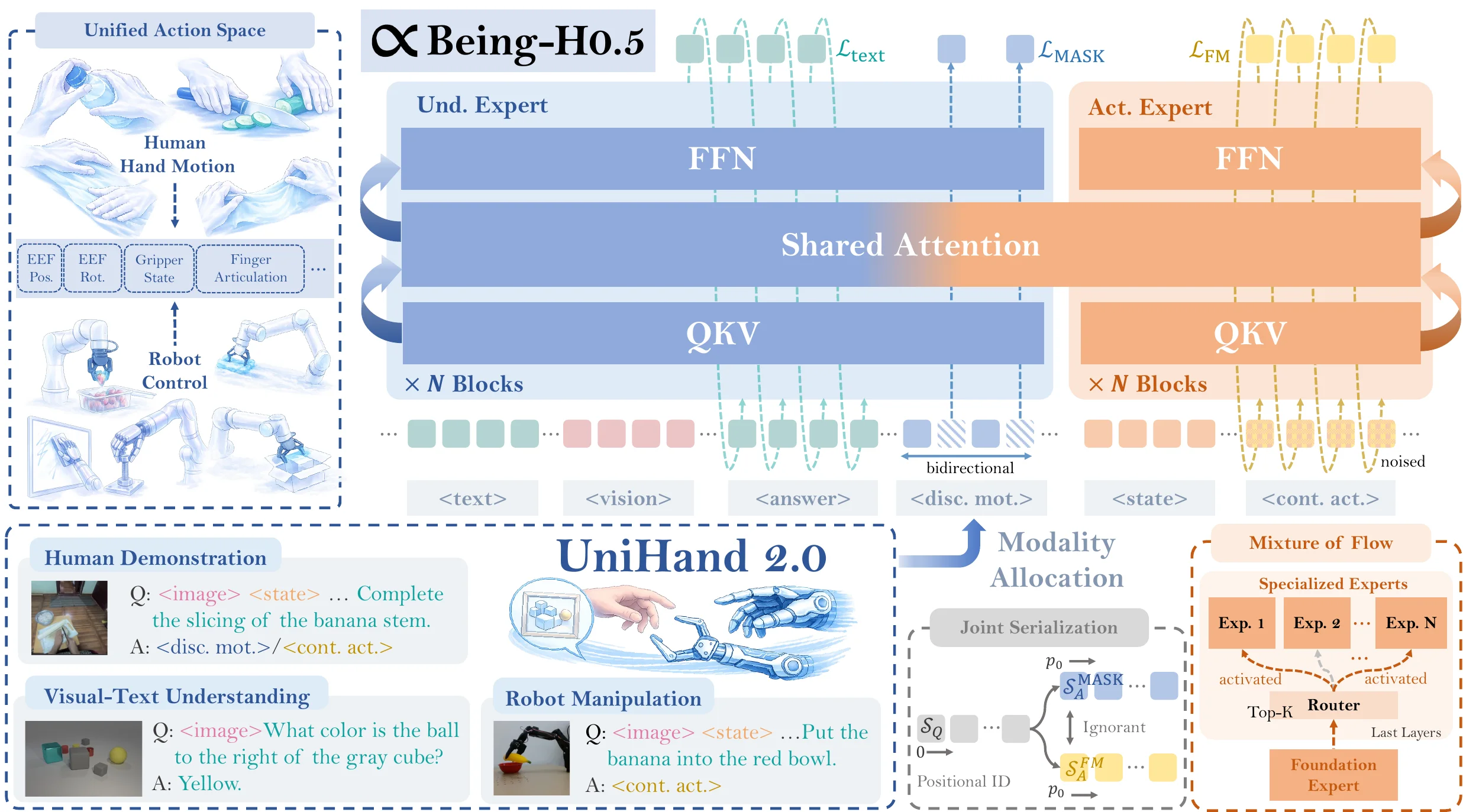
Being-H0.5 的本质是 Scale up 跨具身数据训练的 Pi-05 like 的 VLA,从结构上也可以看出来,本身包括了 VL 以及 Reasoning 以及 VLM 直接预测离散的 Action,这些做法和 Pi-0.5 基本一致,同时还在 Actor 里面应用了 MoE,称之为 MoF。为了使用大量的混合的数据,本身他们建立了一种 Unified Action Space 把 MANO 手参数与各种机器人控制信号(bimanual EE pose、joint、gripper、mobile base)映射到语义对齐的固定维度向量,不过似乎本身这部分说的还是比较含糊。Being-H0.5 还算是做 Pretraining 跨本体包括人类数据比较标准的范式,值得一读。
RoboBrain 2.5#
RoboBrain 2.5 具身大脑
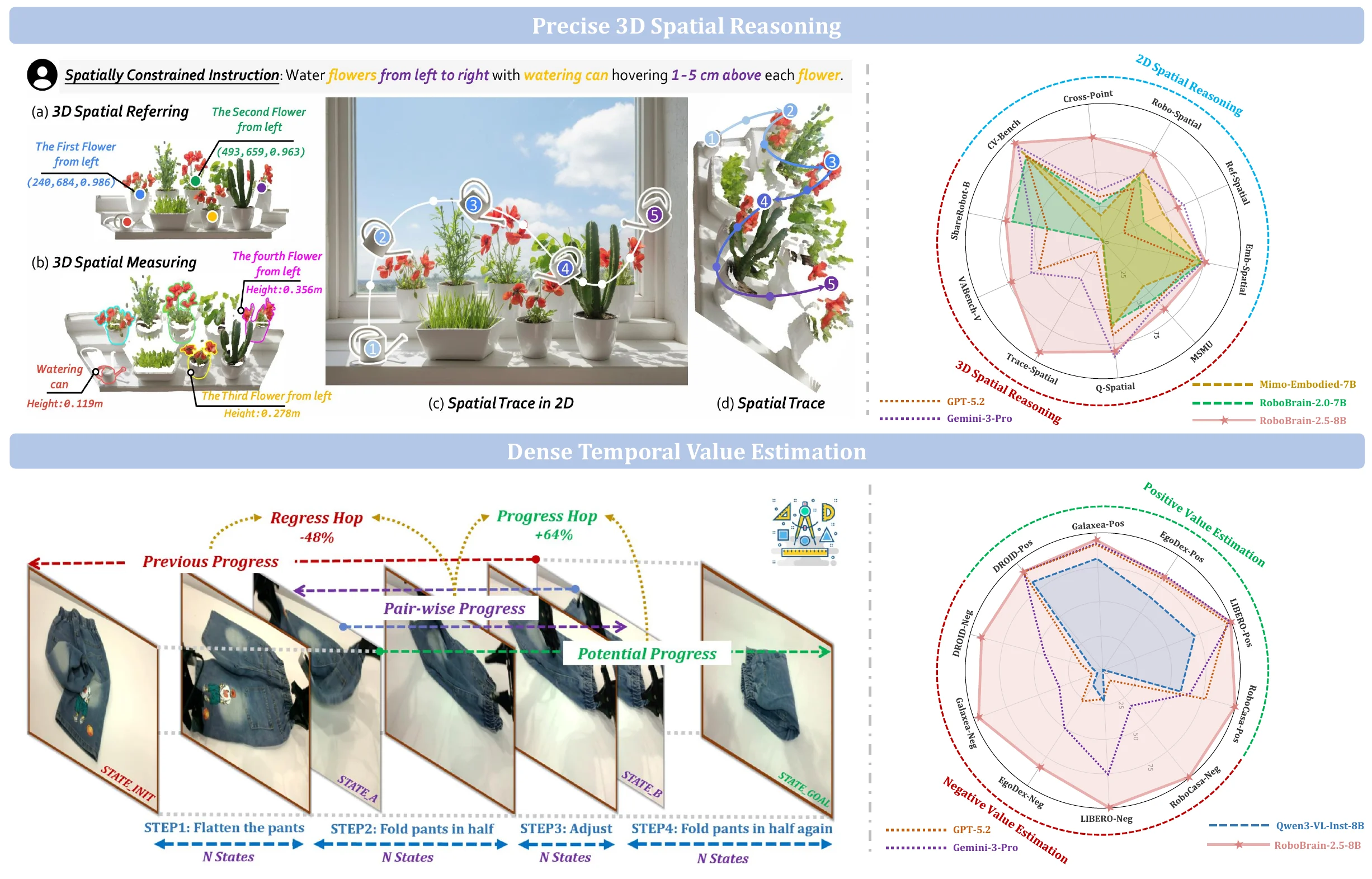
RoboBrain 2.5 是 RoboBrain 2.0 的续作,有了可观的提升,还是很不错的,对于 System2 感兴趣的读者可以去阅读其中数据配比部分。按照惯例,具身大脑不做过多评价。
TwinBrainVLA#
VLM + VLM 的双脑非对称 MoT VLA
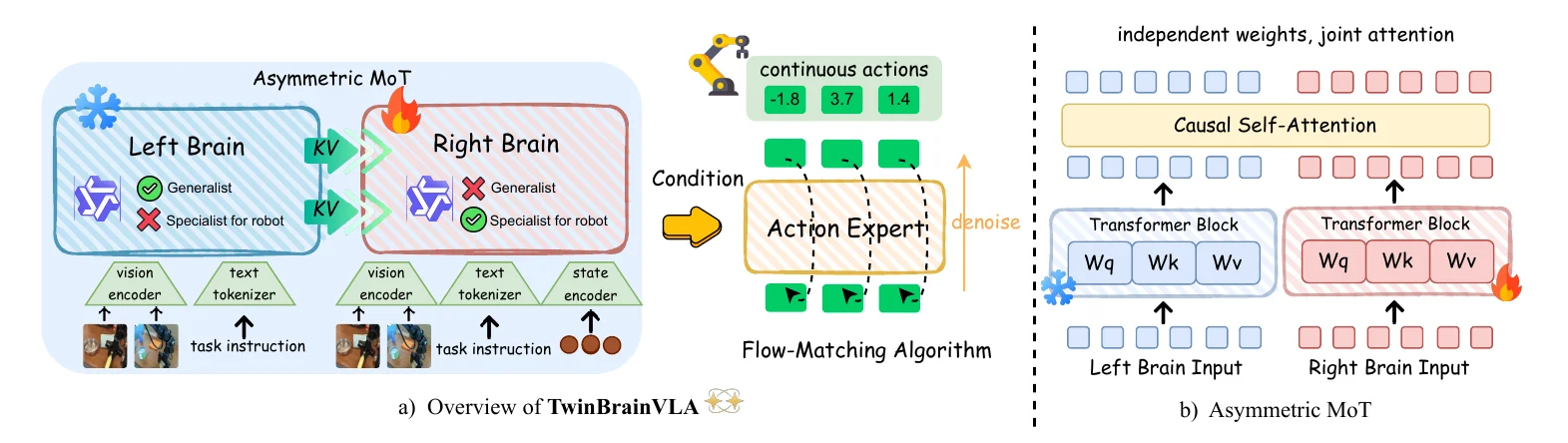
TwinBrainVLA 本身为了避免灾难性遗忘,使用了两个 VLM 以及一个 Actor 来进行 MoT,其中一个 VLM 是 frozen 的代表世界知识,在前面,后面的 VLM + Actor 就是传统的 Pi-like 的结构正常训练。本身这个想法还是比较有意思的,当然显然在目前底层 Actor 泛化能力有限的情况下本身这个结构依然无法泛化,不过确实可以说是一个自成双系统的结构了。使用两份权重虽然很重,但是确实是一种有趣的力大砖飞的解法,由此来想,任何的涉及灾难性遗忘似乎至少都可以这么做来讲故事,比如说某个 WM + WM + Actor?还是可以的。